重读 CenterNet,一个在Github有5.2K星标的目标检测算法
新智元推荐
新智元推荐
来源:我爱计算机视觉
作者:张凯
【新智元导读】本文带领大家重温 Objects as Points 一文,其于2019年4月发布于arXiv,谷歌学术显示目前已有403次引用,Github代码仓库已有5.2K星标,无论在工业界和学术界均有巨大影响力。
论文作者信息:

动机
CenterNet原理
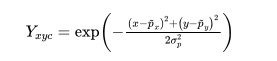
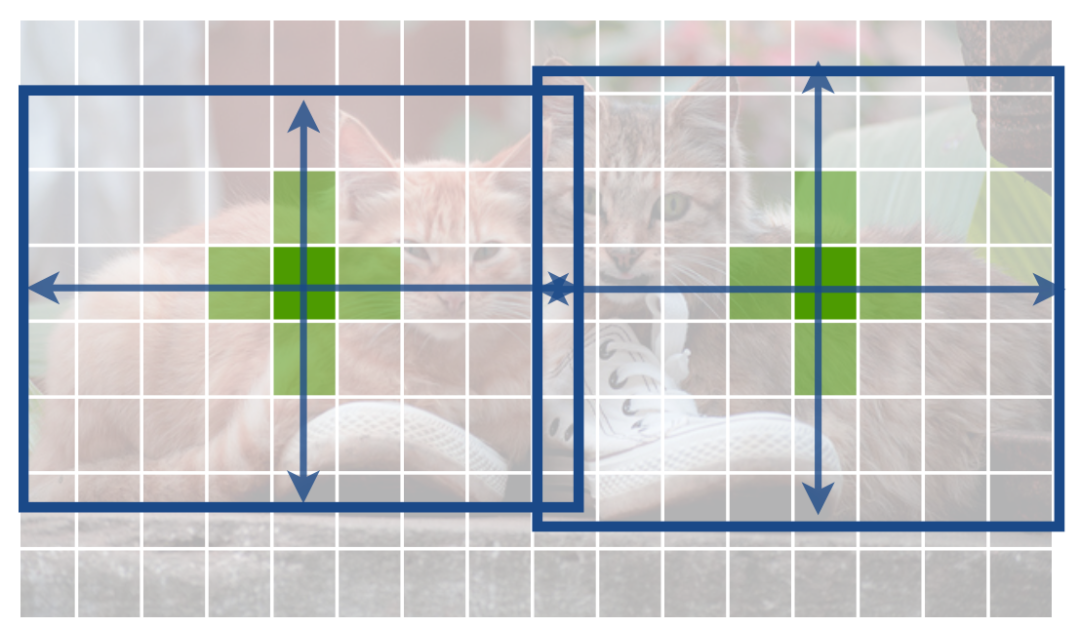
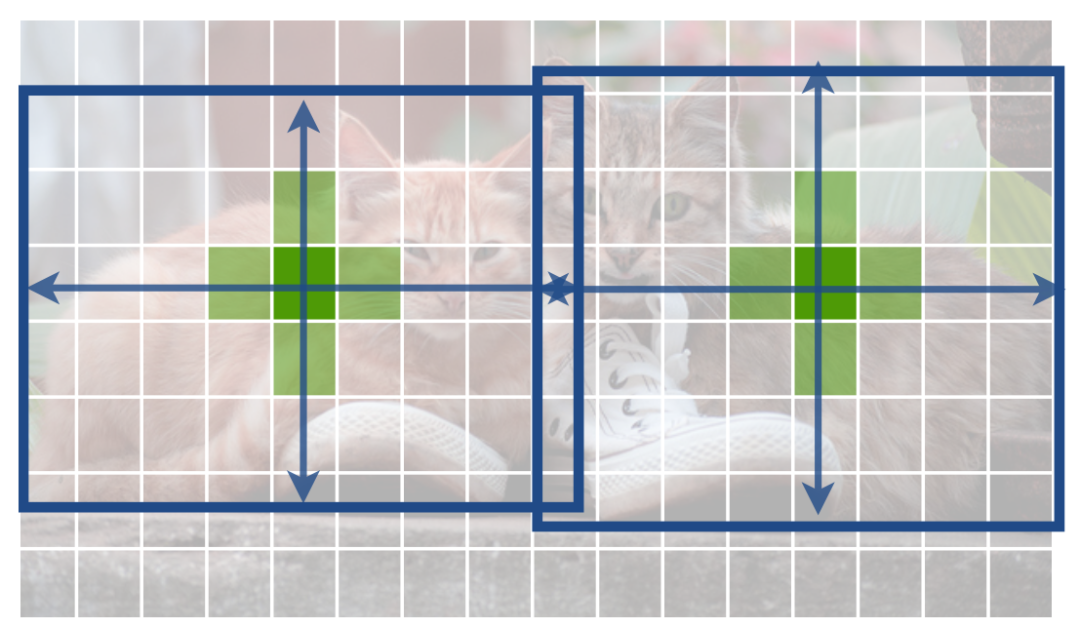
1.1 关键点(key point)损失函数
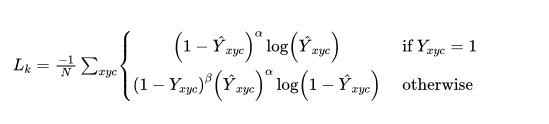
-
当 时,若 接近1,由于 项的存在,损失函数会急剧衰减,而当 不接近1时,损失函数轻微衰减,使得优化器更关注 不接近1的样本。 -
当 时,若 接近0,由于 项的存在,损失函数急剧衰减,而当 接近1时,损失函数轻微衰减,使得优化器更关注 接近1的样本。
1.2 offset损失函数
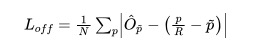
1.3 尺寸(size)损失函数
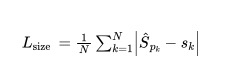
1.4 整体的损失函数
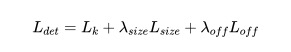
网络结构
作者尝试了4种网络结构,分别为ResNet-18、ResNet-101、DLA-34、Hourglass-104,如下图所示,方框内的数字用于指出特征的尺寸,当方框内数字为4时,表示此时特征的长和宽分别为输入图片的1/4。
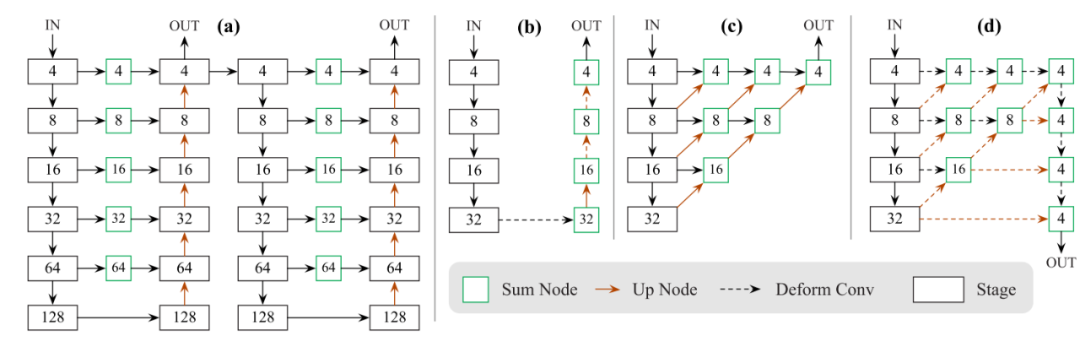
Hourglass-104
-
ResNet-18和ResNet-101
-
DLA-34

使用CenterNet做3D目标检测
2D目标检测只需要网络输出目标的位置和尺寸即可,而3D目标检测还需要网络输出目标的深度、(长、宽、高)、目标的角度这3个额外的信息。
3.1 深度
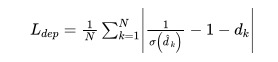
3.2 长、宽、高
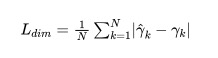
3.3 角度
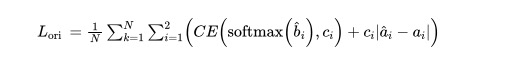
实验结果
4.1 2D目标检测
-
random flip -
random scaling -
cropping -
color jittering

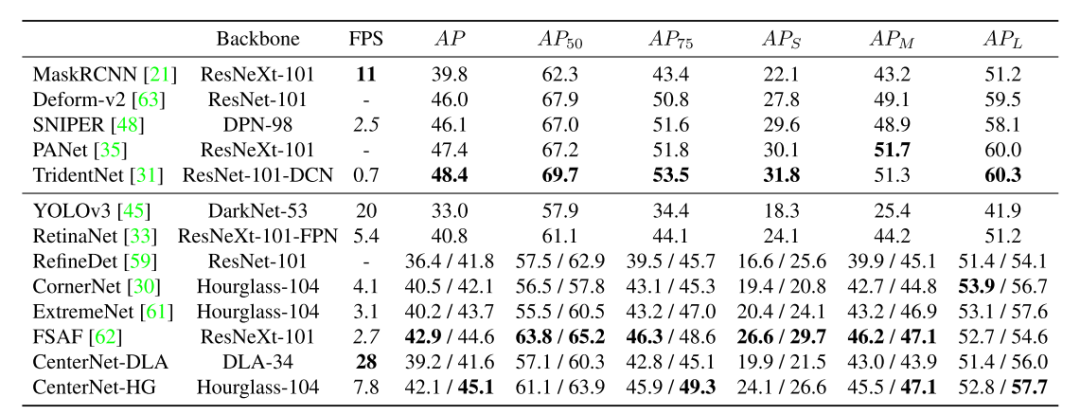
4.2 3D目标检测

总结
-
提出了CenterNet框架用于目标检测,该方法预测目标的关键点和尺寸,简单、速度快、精度高,不需要预定义anchor,也不需要NMS,完全实现端到端训练; -
在CenterNet框架下,可以通过增加网络的head预测目标的其他属性,比如3D目标检测中的目标深度、角度等信息,可扩展性强。 -
源码: https://github.com/xingyizhou/CenterNet


登录查看更多
相关内容


相关VIP内容
相关资讯