阿里小蜜:电商领域的智能助理技术实践

视频由“IT 大咖说”提供,时长约 43 分钟,请在 WiFi 环境下观看 *
在全球人工智能领域不断发展的今天,包括 Google、Facebook、Microsoft、Amazon、Apple 等互联公司相继推出了自己的智能私人助理和机器人平台。
智能人机交互通过拟人化的交互体验逐步在智能客服、任务助理、智能家居、智能硬件、互动聊天等领域发挥巨大的作用和价值。因此,各大公司都将智能聊天机器人作为未来的入口级别的应用在对待。今天随着市场的进一步发展,聊天机器人按照产品和服务的类型主要可分为:客服,娱乐,助理,教育,服务等类型。
图 1 截取了部分聊天机器人。

图 1:一些 chat-bot 的汇总
2015 年 7 月,阿里推出了自己的智能私人助理 - 阿里小蜜,一个围绕着电子商务领域中的服务、导购以及任务助理为核心的智能人机交互产品。通过电子商务领域与智能人机交互领域的结合,带来传统服务行业模式的变化与体验的提升。
在去年的双十一期间,阿里小蜜整体智能服务量达到 643 万,其中智能解决率达到 95%,智能服务在整个服务量 (总服务量 = 智能服务量 + 在线人工服务量 + 电话服务量) 占比也达到 95%,成为了双十一期间服务的绝对主力。
智能人机交互系统,俗称:chatbot 系统或者 bot 系统。
图 2 是人机交互的流程图:
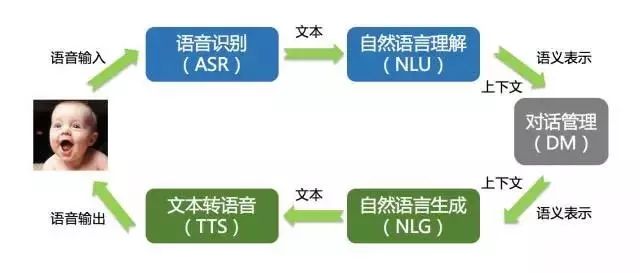
图 2:人机交互的流程
核心是 NLU(自然语言理解),通过对话系统处理后,最后通过自然语言生成的方式给出答案。一段语言如何理解对于计算机来说是非常有难度的,例如:“苹果”这个词就具备至少两个含义,一个是水果属性的“苹果”,还有一个是知名互联网公司属性的“苹果”。
在阿里小蜜这样在电子商务领域的场景中,对接的有客服、助理、聊天几大类的机器人。这些机器人,由于本身的目标不同,就导致不能用同一套技术框架来解决。因此,我们先采用分领域分层分场景的方式进行架构抽象,然后再根据不同的分层和分场景采用不同的机器学习方法进行技术设计。首先我们将对话系统从分成两层:
1、意图识别层:识别语言的真实意图,将意图进行分类并进行意图属性抽取。意图决定了后续的领域识别流程,因此意图层是一个结合上下文数据模型与领域数据模型不断对意图进行明确和推理的过程;
2、问答匹配层:对问题进行匹配识别及生成答案的过程。在阿里小蜜的对话体系中我们按照业务场景进行了 3 种典型问题类型的划分,并且依据 3 种类型会采用不同的匹配流程和方法:
问答型:例如“密码忘记怎么办?”→ 采用基于知识图谱构建 + 检索模型匹配方式
任务型:例如“我想订一张明天从杭州到北京的机票”→ 意图决策 +slots filling 的匹配以及基于深度强化学习的方式
语聊型:例如“我心情不好”→ 检索模型与 Deep Learning 相结合的方式
图 3 表示了阿里小蜜的意图和匹配分层的技术架构。
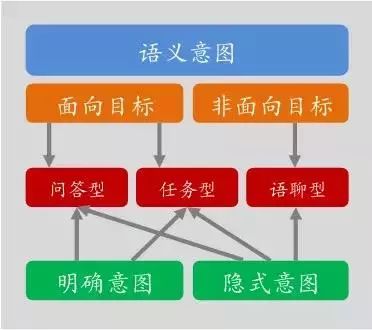
图 3:基于意图于匹配分层的技术架构
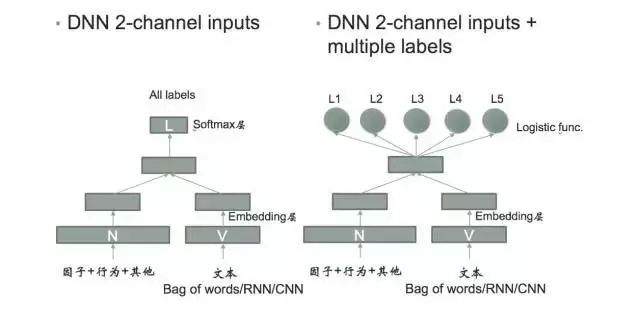
通常将意图识别抽象成机器学习中的分类问题,在阿里小蜜的技术方案中除了传统的文本特征之外,考虑到本身在对话领域中存在语义意图不完整的情况,我们也加入了用实时、离线用户本身的行为及用户本身相关的特征,通过深度学习方案构建模型,对用户意图进行预测, 具体如图 4:
图 4:结合用户行为的深度学习意图分类

在基于深度学习的分类预测模型上,我们有两种具体的选型方案:一种是多分类模型,一种是二分类模型。多分类模型的优点是性能快,但是对于需要扩展分类领域是整个模型需要重新训练;而二分类模型的优点就是扩展领域场景时原来的模型都可以复用,可以平台进行扩展,缺点也很明显需要不断的进行二分,整体的性能上不如多分类好,因此在具体的场景和数据量上可以做不同的选型。
小蜜用 DL 做意图分类的整体技术思路是将行为因子与文本特征分别进行 Embedding 处理,通过向量叠加之后再进行多分类或者二分类处理。这里的文本特征维度可以选择通过传统的 bag of words 的方法,也可使用 Deep Learning 的方法进行向量化。具体图:
图 5:结合用户行为的深度学习意图分类的网络结构
目前主流的智能匹配技术分为如下 3 种方法:
基于模板匹配 (Rule-Based)
基于检索模型 (Retrieval Model)
基于深度学习模型 (Deep Learning)
在阿里小蜜的技术场景下,我们采用了基于模板匹配,检索模型以及深度学习模型为基础的方法原型来进行分场景 (问答型、任务型、语聊型) 的会话系统构建。
智能导购主要通过支持和用户的多轮交互,不断的理解和明确用户的意图。并在此基础上利用深度强化学习不断的优化导购的交互过程。图 6 展示了智能导购的技术架构图。
图 6:智能导购的架构图
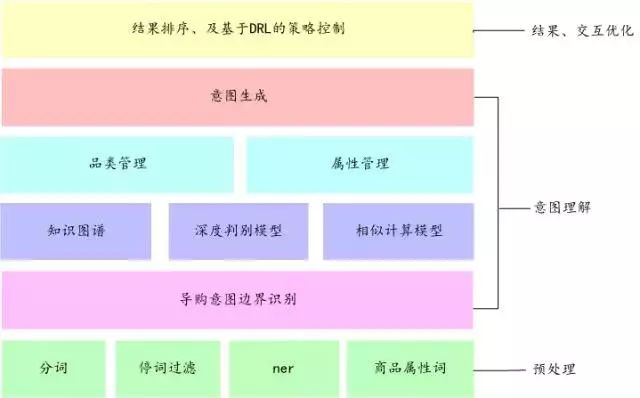
这里两个核心的问题:
a)在多轮交互中理解用户的意图。
b)根据用户的意图结果,优化排序的结果和交互的过程。
下面主要介绍导购意图理解、以及深度增强学习的交互策略优化。
智能导购下的意图理解主要是识别用户想要购买的商品以及商品对应的属性,相对于传统的意图理解,也带来了几个新的挑战。
第一,用户偏向于短句的表达。因此,识别用户的意图,要结合用户的多轮会话和意图的边界。
第二,在多轮交互中用户会不断的添加或修改意图的子意图,需要维护一份当前识别的意图集合。
第三,商品意图之间存在着互斥,相似,上下位等关系。不同的关系对应的意图管理也不同。
第四,属性意图存在着归类和互斥的问题。
针对短语表达,我们通过品类管理和属性管理维护了一个意图堆,从而较好的解决了短语表示,意图边界和具体的意图切换和修改逻辑。同时,针对较大的商品库问题,我们采用知识图谱结合语义索引的方式,使得商品的识别变得非常高效。下面我们分别介绍下品类管理和属性管理。
基于知识图谱和语义索引的品类管理
智能导购场景下的品类管理分为品类识别,以及品类的关系计算。下图是品类关系的架构图。
图 7:品类管理架构图
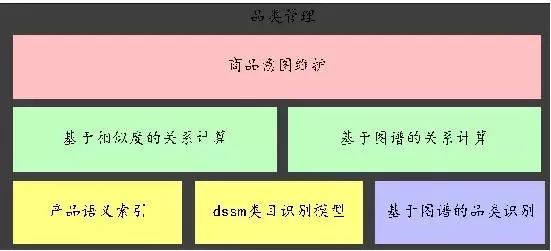
品类识别:
采用了基于知识图谱的识别方案和基于语义索引及 dssm 的判别模型。
a) 基于商品知识图谱的识别方案:
基于知识图谱复杂的结构化能力,做商品的类目识别。是我们商品识别的基础。
b) 基于语义索引及 dssm 商品识别模型的方案:
知识图谱的识别方案的优势是在于准确率高,但是不能覆盖所有的 case。因此,我们提出了一种基于语义索引和 dssm 结合的商品识别方案兜底。
图 8:基于语义索引和 dssm 的商品识别方案
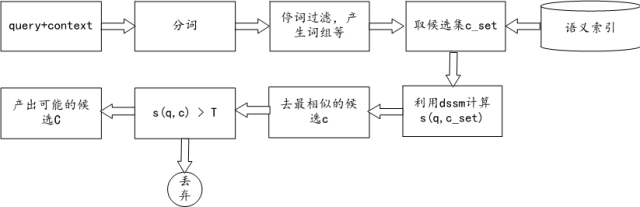
图8:基于语义索引和dssm的商品识别方案
语义索引的构造:
通常语义索引的构造有基于本体的方式,基于 LSI 的方式。我们用了一种结合搜索点击数据和词向量的方式构造的语义索引。主要包括下面几步:
第一步:利用搜索点击行为,提取分词到类目的候选。
第二步:基于词向量,计算分词和候选类目的相似性,对索引重排序。
基于 dssm 的商品识别:
dssm 是微软提出的一种用于 query 和 doc 匹配的有监督的深度语义匹配网络,能够较好的解决词汇鸿沟的问题,捕捉句子的内在语义。本文以 dssm 作为基础,构建了 query 和候选的类目的相似度计算模型。取得了较好的效果,模型的 acc 在测试集上有 92% 左右。
图 9:dssm 模型的网络结构图
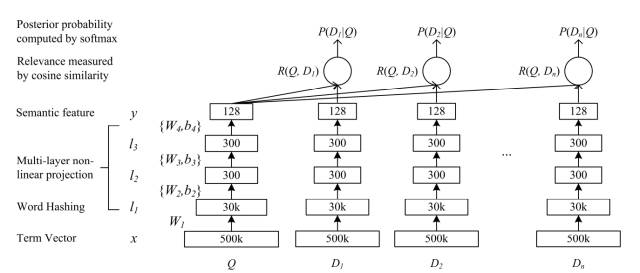
样本的构造:训练的正样本是通过搜索日志中的搜索 query 和点击类目构造的。负样本则是通过利用 query 和点击的类目作为种子,检索出来一些相似的类目,将不在正样本中的类目作为负样本。正负样本的比例 1:1。
品类关系计算:
品类关系的计算主要用于智能导购的意图管理中,这里主要考虑的几种关系是:上下位关系和相似关系。举个例子,用户的第一个意图是要买衣服,当后面的意图说要买水杯的时候,之前衣服所带有的属性就不应该被继承给水杯。相反,如果这个时候用户说的是要裤子,由于裤子是衣服的下位词,则之前在衣服上的属性就应该被继承下来。
上下位关系的计算 2 种方案:
a)采用基于知识图谱的关系运算。
b)通过用户的搜索 query 的提取。
相似性计算的两种方案:
a)基于相同的上位词。比方说小米,华为的上位词都是手机,则他们相似。
b)基于 fast-text 的品类词的 embedding 的语义相似度。
基于知识图谱和相似度计算的属性管理
下图是属性管理的架构图:
图 10:属性管理架构图
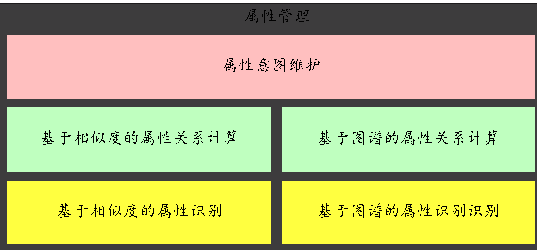
整体上属性管理包括属性识别和属性关系计算两个核心模块,思路和品类管理较为相似。这里就不在详细介绍了。
强化学习是 agent 从环境到行为的映射学习,目标是奖励信号 (强化信号) 函数值最大,由环境提供强化信号评价产生动作的好坏。agent 通过不断的探索外部的环境,来得到一个最优的决策策略,适合于序列决策问题。图 11 是一个强化学习的 model 和环境交互的展示。
图 11:env-model 的交互图
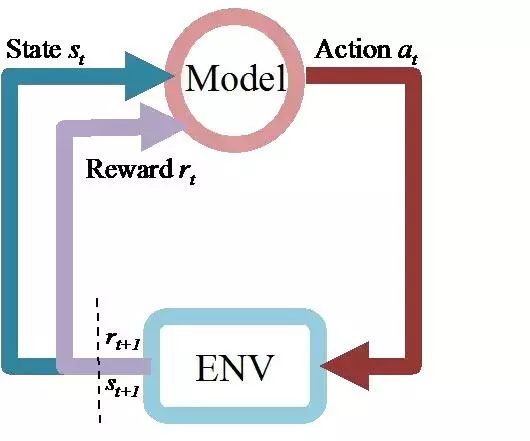
深度强化学习是结合了深度学习的强化学习,主要利用深度学习强大的非线性表达能力,来表示 agent 面对的 state 和 state 上决策逻辑。
目前我们用 DRL 主要来优化我们的交互策略。因此,我们的设定是,用户是强化学习中的 env,而机器是 model。action 是本轮是否出主动反问的交互,还是直接出搜索结果。
状态 (state) 的设计:
这里状态的设计主要考虑,用户的多轮意图、用户的人群划分、以及每一轮交互的产品的信息作为当前的机器感知到的状态。
state= ( intent1, query1, price1, is_click,query_item_sim, …, power, user_inter, age)
其中 intent1 表明的是用户当前的意图,query1 表示的用户的原始 query。price1 表示当前展现给用户的商品的均价,is_click 表示本轮交互是否发生点击,query_item_sim 表示 query 和 item 的相似度。power 表示是用户的购买力,user_inter 表示用户的兴趣, age 表示用户的年龄。
reward 的设计:
由于最终衡量的是用户的成交和点击率和对话的轮数。因此 reward 的设计主要包括下面 3 个方面:
a) 用户的点击的 reward 设置成 1
b) 成交设置成 [1 + math.log(price + 1.0) ]
c) 其余的设置成 0.1
DRL 的方案的选型:
这里具体的方案,主要采用了 DQN, policy-gradient 和 A3C 的三种方案。
智能服务的特点:有领域知识的概念,且知识之间的关联性高,并且对精准度要求比较高。
基于问答型场景的特点,我们在技术选型上采用了知识图谱构建 + 检索模型相结合的方式来进行核心匹配模型的设计。
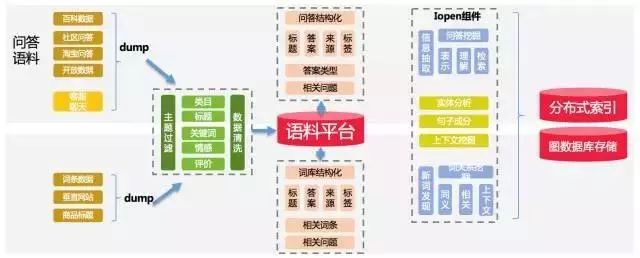
知识图谱的构建我们会从两个角度来进行抽象,一个是实体维度的挖掘,一个是短句维度进行挖掘,通过在淘宝平台上积累的大量属于以及互联网数据,通过主题模型的方式进行挖掘、标注与清洗,再通过预设定好的关系进行实体之间关系的定义最终形成知识图谱。基本的挖掘框架流程如下:
图 12:知识图谱的实体和短语挖掘流程
挖掘构建的知识图谱示例如图 13:
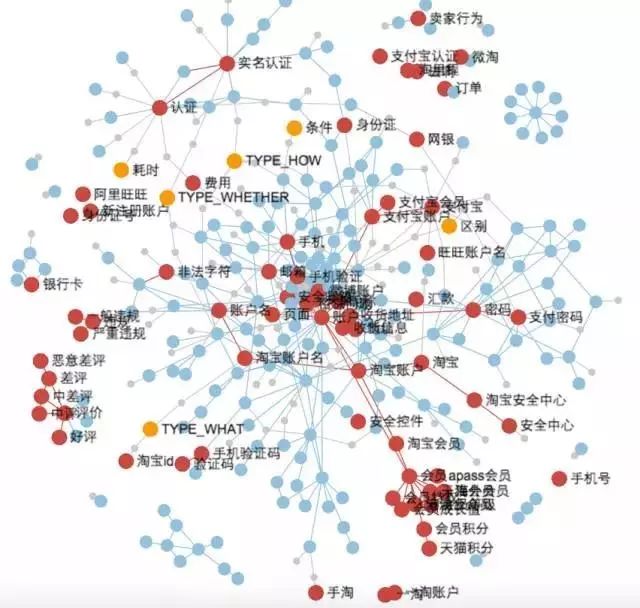
图 13:具体的知识图谱的示例
基于知识图谱的匹配模式具备以下几个优点:
(1) 在对话结构和流程的设计中支持实体间的上下文会话识别与推理
(2) 通常在一般型问答的准确率相对比较高(当然具备推理型场景的需要特殊的设计,会有些复杂)
同样也有明显的缺点:
(1) 模型构建初期可能会存在数据的松散和覆盖率问题,导致匹配的覆盖率缺失;
(2) 对于知识图谱增量维护相比传统的 QA Pair 对知识的维护上的成本会更大一些;
因此我们在阿里小蜜的问答型设计中,还是融入了传统的基于检索模型的对话匹配。
其在线基本流程分为:
(1) 提问预处理:分词、指代消解、纠错等基本文本处理流程;
(2) 检索召回:通过检索的方式在候选数据中召回可能的匹配候选数据;
(3) 计算:通过 Query 结合上下文模型与候选数据进行计算,通过我们采用文本之间的距离计算方式 (余弦相似度、编辑距离) 以及分类模型相结合的方式进行计算;
(4) 最终根据返回的候选集打分阈值进行最终的产品流程设计;
离线流程分为:
(1) 知识数据的索引化;
(2) 离线文本模型的构建:例如 Term-Weight 计算等;
检索模型整体流程如图 14:
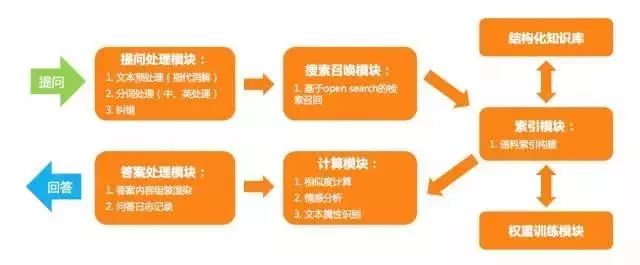
图 14:检索模型的流程图
智能聊天的特点:非面向目标,语义意图不明确,通常期待的是语义相关性和渐进性,对准确率要求相对较低。
面向 open domain 的聊天机器人目前无论在学术界还是在工业界都是一大难题,通常在目前这个阶段我们有两种方式来做对话设计:
一种是学术界非常火爆的 Deep Learning 生成模型方式,通过 Encoder-Decoder 模型通过 LSTM 的方式进行 Sequence to Sequence 生成,如图 15:
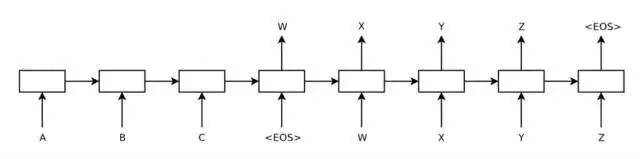
图 15:seq2seq 网络结构图
GenerationModel(生成模型):
优点:通过深层语义方式进行答案生成,答案不受语料库规模限制缺点:模型的可解释性不强,且难以保证一致性和合理性回答
另外一种方式就是通过传统的检索模型的方式来构建语聊的问答匹配。
RetrievalModel(检索模型):
优点:答案在预设的语料库中,可控,匹配模型相对简单,可解释性强
缺点:在一定程度上缺乏一些语义性,且有固定语料库的局限性
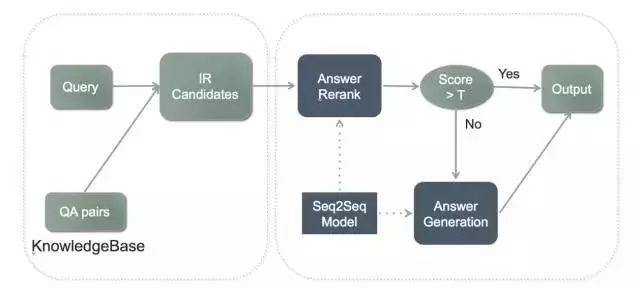
因此在阿里小蜜的聊天引擎中,我们结合了两者各自的优势,将两个模型进行了融合形成了阿里小蜜聊天引擎的核心。先通过传统的检索模型检索出候选集数据,然后通过 Seq2Seq Model 对候选集进行 Rerank,重排序后超过制定的阈值就进行输出,不到阈值就通过 Seq2Seq Model 进行答案生成,整体流程图 16:
图 16:小蜜的闲聊模块
目前的人工智能领域任然处在弱人工智能阶段,特别是从感知到认知领域需要提升的空间还非常大。智能人机交互在面向目标的领域已经可以与实际工业场景紧密结合并产生巨大价值,随着人工智能技术的不断发展,未来智能人机交互领域的发展还将会有不断的提升,对于未来技术的发展我们值得期待和展望:
1、数据的不断积累,以及领域知识图谱的不断完善与构建将不断助推智能人机交互的不断提升;
2、面向任务的垂直细分领域机器人的构建将是之后机器人不断爆发的增长点,open domain 的互动机器人在未来一段时间还需要不断提升与摸索;
3、随着分布式计算能力的不断提升,深度学习在席卷了图像、语音等领域后,在 NLP(自然语言处理) 领域将会继续发展,在对话、QA 领域的学术研究将会持续活跃;
在未来随着学术界和工业界的不断结合与积累,期待人工智能电影中的场景早日实现,人人都能拥有自己的智能“小蜜”。
参考文献:
[1] : Huang P S, He X, Gao J, et al. Learningdeep structured semantic models for web search using clickthrough data[C]// ACMInternational Conference on Conference on Information & KnowledgeManagement. ACM, 2013:2333-2338.
[2] Minghui Qiu and Feng-Lin Li. MeChat: A Sequence to Sequence andRerank based Chatbot Engine. ACL 2017
[3] Dzmitry Bahdanau, Kyunghyun Cho, and YoshuaBen- gio. 2015. Neural machine translation by jointly learning to align andtranslate. In Proceedings of ICLR 2015
[4]Matthew Henderson. 2015. Machine learning fordialog state tracking: A review. In Proceedings of The First InternationalWorkshop on Machine Learning in Spoken Language Processing.
[5] Mnih V, Badia A P, Mirza M, et al.Asynchronous Methods for Deep Reinforcement Learning[J]. 2016
[6] Li J, Monroe W, Ritter A, et al. DeepReinforcement Learning for Dialogue Generation[J]. 2016.
[7] Sordoni A, Bengio Y, Nie J Y. Learning concept embeddings for queryexpansion by quantum entropy minimization[C]// Twenty-Eighth AAAI Conference onArtificial Intelligence. AAAI Press, 2014:1586-1592.
陈海青,阿里巴巴智能服务事业部资深技术专家,在阿里从事智能人机交互领域相关的工作和研究 8 年,带领团队构建了阿里巴巴智能交互机器人系统。本文来自陈海青在“携程技术沙龙——人机语义交互 AI”上的分享。



