陆金所机房一键切换平台建设

作者 | 刘俊
编辑 | 田晓旭
分享主要分为五个部分:整个平台建设的里程碑,帮助大家对建设过程有个整体认识;整体设计目标,描述一下我们的整体设计思路;关键技术实现方案,主要是关键组件的切换方式;平台建设完成之后的收益情况;未来陆金所多活机房建设的远期规划。
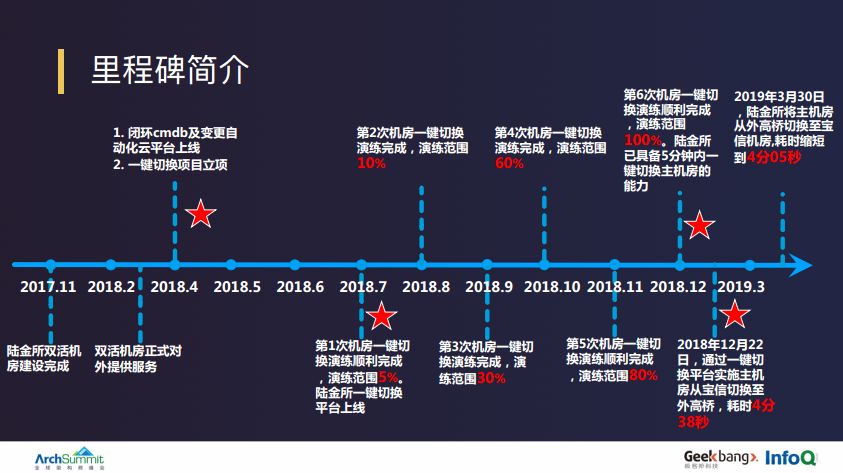
2012 年,陆金所开始对外提供服务,前后差不多经历了 7 次机房搬迁,截止到 2017 年底,陆金所才真正完成了同城双活的基础设施建设工作。2018 年初,我们整个网站架构完成了多活改造。2018 年 2 月,陆金所真正以双活形态对外提供相关服务。
为了应对未来双活及多活的运营场景和相关挑战,我们启动了切换平台建设。整个平台建设周期约为 3 个月,基于陆金所自研的 DevOps 流水线及自动化运维技术体系。2018 年 6 月,第一期平台功能开发和上线工作完成,2018 年 7 月,通过非核心业务、覆盖 5% 相关组件的切换场景验证了整个切换平台。
至此之后,我们每月会有一次例行的切换演练过程,并且从一些非核心、非关键的业务逐步演练覆盖到全部的组件和服务。我们在半年的时间里,进行了 6 次比较大的切换,2018 年 12 月,陆金所正式完成了覆盖全部服务的切换验证工作,12 月底,通过切换平台,陆金所完成了第一次主辅机房的正式切换,整体耗时 4 分 38 秒,符合预期。但是我们也从中发现了一些问题,所以 2019 年 3 月,我们在此基础上重新迭代了一个版本,将整体耗时从 4 分 38 秒缩短为 4 分 5 秒。
接下来,介绍一下陆金所的整体设计目标。
众所周知,陆金所现在大部分的技术框架都是在云计算、容器、微服务等技术环境下进行的。所以,数据中心多活或双活运营的核心问题都是在解决有状态服务的高可用管理。陆金所把有状态服务所在的机房称为主机房,相对应的,不是主服务所在的机房就是辅机房。
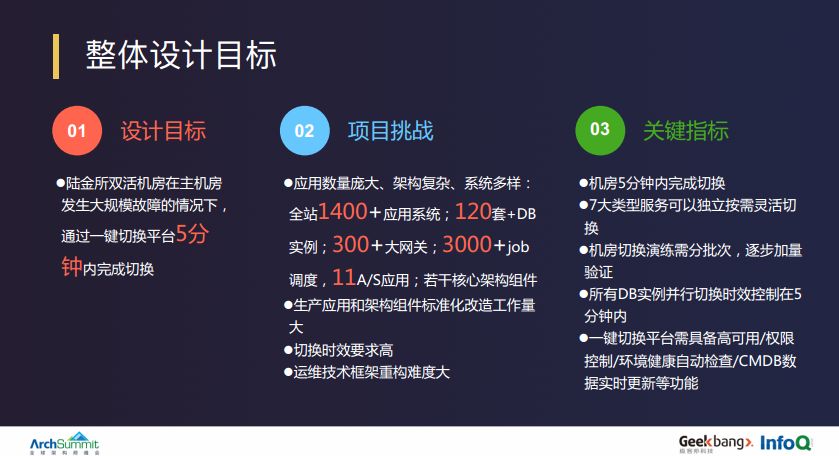
因此,在切换平台建设初期,我们就把平台的使用场景和建设目标确定为当主机房发生大面积服务故障时,能够通过切换平台在 5 分钟之内完成主机房内各个组件和服务的主辅角色切换,从而达到快速故障恢复的目标。
陆金所发展到现在已经是个很庞大的系统,包含超过 1400 个子应用,120 套 DB 实例,300 个大网关,3000 个 Job 调度,非自研、非外购的不能做双活的主备系统,基于状态的核心组件,例如分布式锁、文件系统等等。基于这样庞大的应用系统,想要在 5 分钟之内完成主机房全部组件的角色切换,难度是显而易见的。
我们是通过下面八个字来解决这些难题的:大而化小,分而置之。我们的整体目标是在 5 分钟之内完成整个机房服务的角色切换,而这个大目标又可以拆解为几个关键的核心指标:时效性、独立性、健壮性和数据闭环。然后再把这些关键指标逐层分解,下派到需要服务切换的团队,由他们进行对应指标达成率的细化设计、迭代式的优化和改进,通过小演练、大演练、小切换和大切换的方式,不断迭代优化实现整体平台设计目标。
接下来,介绍一些具体的实现技术方案,我会抽取几个比较有代表性的核心组件。
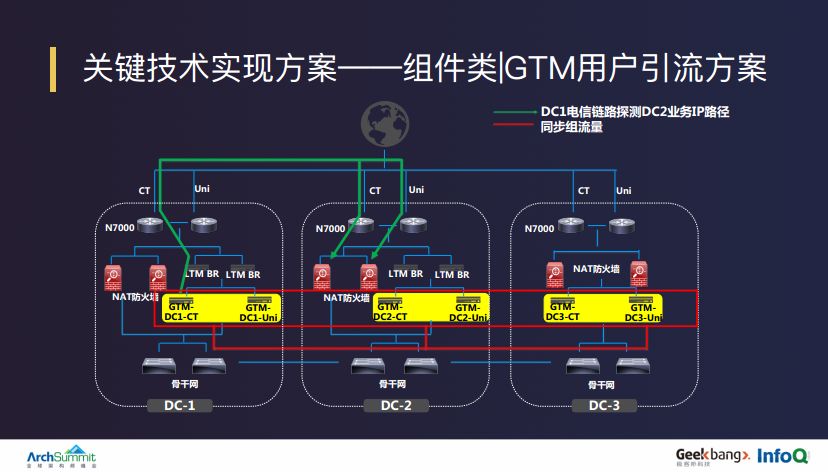
GTM 用户引流方案,GTM 是一个依托于 F5 设备的互联网域名管理平台,我们根据这套解决方案又进行了二次封装和开发,开发了一套基于互联网用户流量的白屏化工具,然后根据这个工具对互联网域名进行秒级的省份、运营商及机房级别的多纬度的细化流量分配管理。
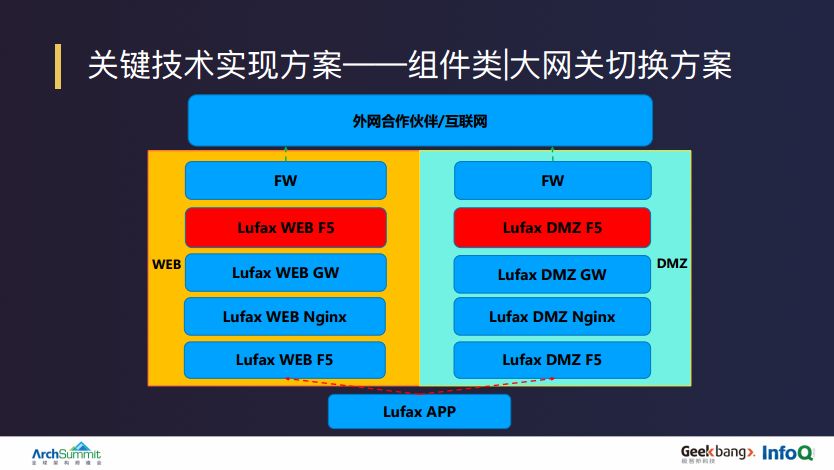
很多人可能不了解大网关是什么,这其实是一个互联网金融的核心特点,陆金所作为一个拥有很多金融品类的在线财富管理平台,本身有很多外部服务的对接需求,所以自然会有内部应用访问外部服务的特点,而在陆金所内部运营体系中,我们把这些链路资源统一称为大网关。
在大网关场景中,陆金所本身存在金融行业属性,有严格的监管合规要求和相对应的自身安全需求,所以无论是访问互联网,还是通过合作伙伴专线去访问合作伙伴的服务,都需要通过中间的 GW 集群。
所有的应用都不能直接对外访问,对外访问的需求都会对应一个点对点的开墙策略,但是这些策略又不能直接落在 GW 应用上,因为会限制集群本身的横向扩展和高可用部署。因此,我们的解决方法是在 GW 应用和防火墙之间又增加了一层逻辑 F5 的访问策略,把所有安全网络的策略及相关的网络映射策略都放在这一层。
这种方式的好处是:所有 GW 应用的状态都可以配置成无状态的,同时可以进行必要程度的水平扩展;所有合作伙伴的服务健康检查也可以在 F5 侧进行配置;给切换场景带来的好处是可以在大网关物理线路上做冗余配置,在切换过程中可以转化为整个网络的链路切换,类似于路由切换、防火墙策略切换,以及与互联网域名相关的 DNS 切换。
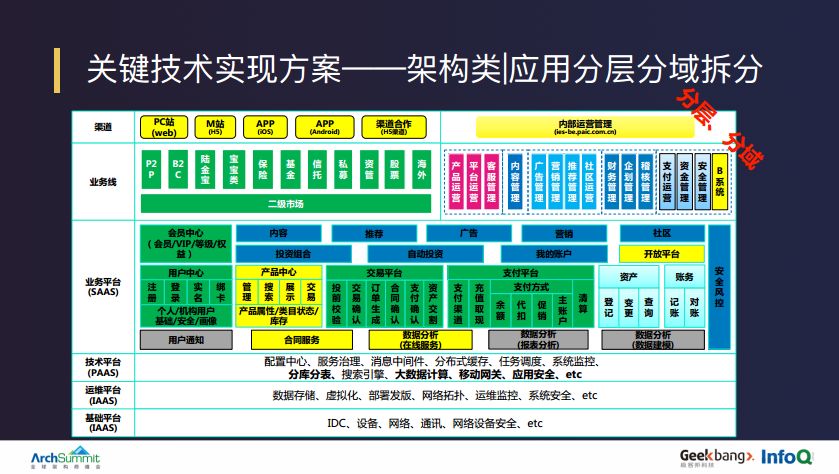
2016 年以前,陆金所的所有应用是相互依赖的,应用之间的依赖关系十分复杂,系统之间的耦合程度也很重,给运营和管理带来了很多问题。
为了解决这些问题,2017 年陆金所做了全站分层分域的架构改造。改造完成之后,陆金所的子系统从外部接入到基础架构分为七到八个层次,每个层次根据业务模型和依赖关系又可以分成一百多个域,其中每个域代表的是一个虚拟的应用组合或应用组,具备高内聚、域之间松耦合的特点。所有的域有自己独立的数据库,同层的域之间尽量不去依赖,跨层或不同层的域之间只能有单向依赖。
架构改造之后的好处是原来很多很繁杂的应用管理,现在可以变换为以域为单位的虚拟团队各司其职的管理维度,例如多活、监控、运维等都会有一个虚拟团队由专人负责迭代优化和功能改进。
与此同时,因为每个域都有自己独立的数据库,所以我们在数据库层面做了按域拆分。拆分之前,陆金所按域是个单实例的、百TB 级的库,拆分之后,变成了 100 多个小库,最大的库也是5 TB 级别的,为后续数据库切换带来了有利条件。
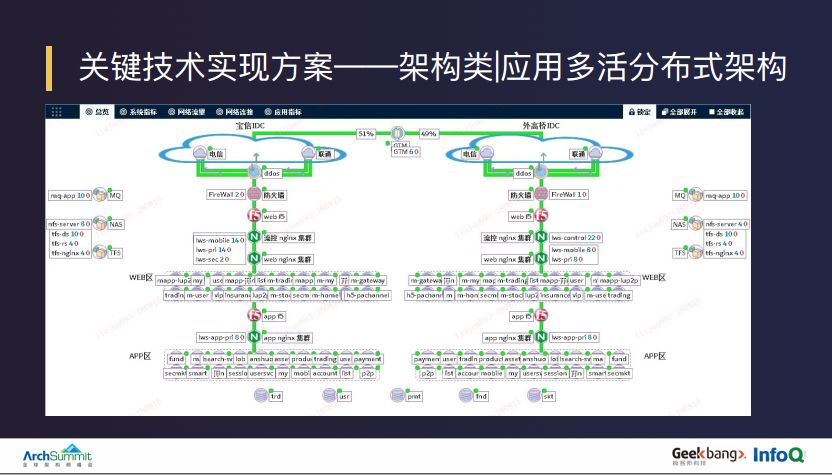
这是陆金所访问链路的架构,上图刚好是我们正常情况下,两个双活机房各承载 50% 流量的形态。当外部请求通过一个机房落地了之后,通过安全设备和防火墙之后,先到达的是 Web 层的 F5,但我们 Web 层的 F5 只做四层的负载。之后经过整个架构中的流控——Nginx 集群,上图是我们集群的默认形态,默认本机房流量落在本地,如果细化到每个应用的流量监控或切换时,我们会根据这个层的下发策略进行流量切换。这样可以直接做内部流量切换,避过了 GTM 切换可能发生的域名解析的延迟,提高了切换效率。
再往下就是比较标准的形态了,Web 层 Nginx 负载均衡做 7 层负载,然后通过 Web 层应用调用 App 层的 F5 和负载,触达到真正的 APP 应用,完成与数据库的交互访问。
需要注意的是,陆金所所有的标准应用都需要严格按照这样的一套标准化的方式进行部署交付。这样做的好处是所有的标准化应用都是无状态的,支持水平横向扩展,不需要做特别多的切换复杂操作,只需切换流量。
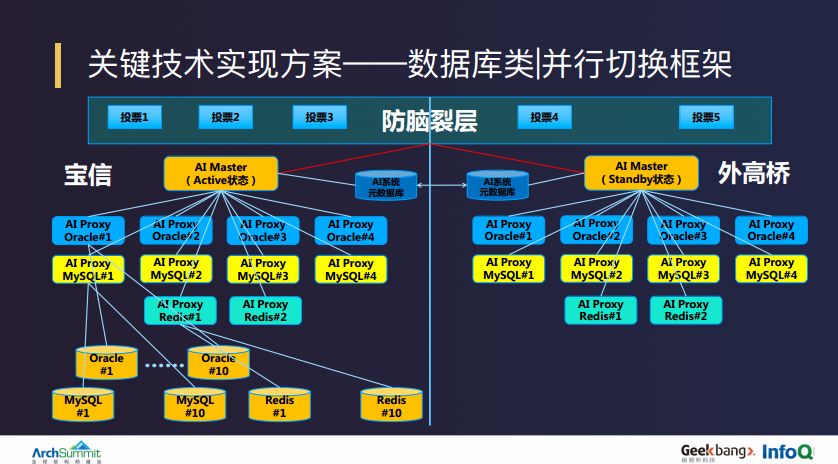
在日常活动中,我们常遇到的切换场景是核心组件的切换,比较有特色的一个场景是数据库 AI 切换。陆金所希望数据库发生故障时,能在无人工干预的情况下,智能地找到问题原因,并实现快速切换。
陆金所 DBA 团队自研了一套数据库的 AI 切换平台,上线之后能够把之前需要数个小时的数据故障恢复时间降到一到三分钟,一个 Redis 库能够在 30 秒之内完成 AI 切换,MySQL 实例能够在一分钟之内完成 AI 切换,Oracle 实例能够控制在一到三分钟。
AI 切换平台上线之后,我们在生产环境至少发生了 12 次真实情况的切换场景,数据库故障恢复的时间基本在一两分钟之内,为陆金所整个网站的可用率提供了比较大的贡献。
当切换指令下发之后,AI Master 会把所有的切换指令下发给各个 AI Proxy,AI Proxy 再下发给其下管理的数据库实例,每个数据库实例把对应的切换状态和返回信息返回给各个 Proxy,并通过 AI Master 返回给调用方。
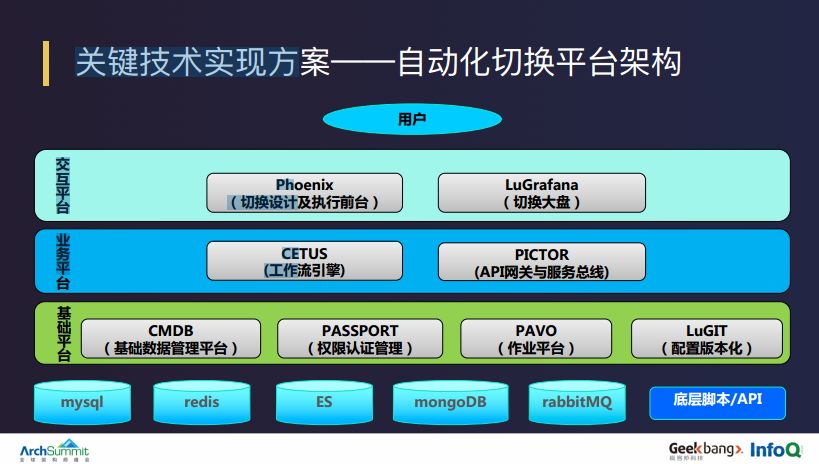
上图是整个切换平台的架构,不是特别复杂,基本上分为三个层次,第一层是交互层,主要是由 Phoenix 平台跟 LuGrafana 组成,分别用来执行切换操作和切换大盘;业务层主要是由流程引擎、服务总线和 API 网关组成;最后一层是基础层,主要是由 CMDB 配置中心、统一权限认证管理 PASSPORT、作业平台 PAVO 和配置版本中心 LuGIT 组成。
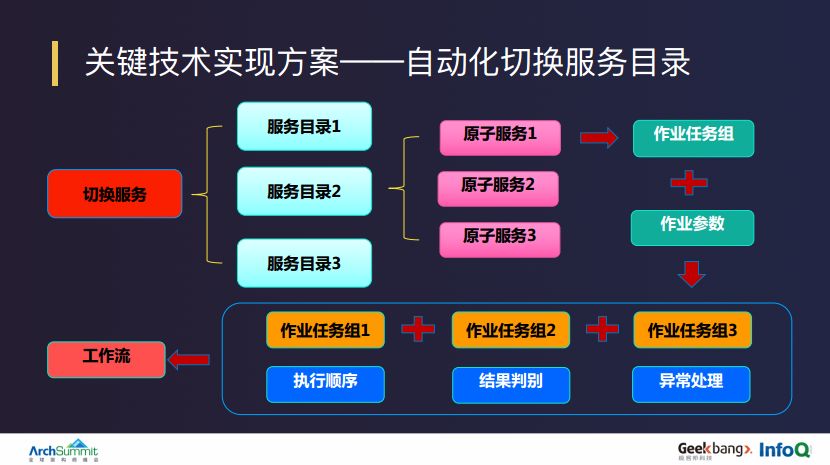
陆金所的核心切换基本上是由 7 个核心组件的切换组成,每个核心组件的切换都有个性化的切换逻辑。在设计切换平台时,我们希望切换服务目录能够更加的抽象化、通用化,所以我们采用了上图的设计模型,一个切换服务相当于是一个组合目录,由一个或者多个服务目录组成,每个切换服务目录根据自己依赖的资源,再分为一个或者多个原子切换服务,每个原子切换服务又由一个作业任务和作业参数组合而成。当这个任务组明确了作业任务以及作业参数之后,再运行,就会生成一套可编排的执行实例,所有的概念通过流程引擎进行整个调度。
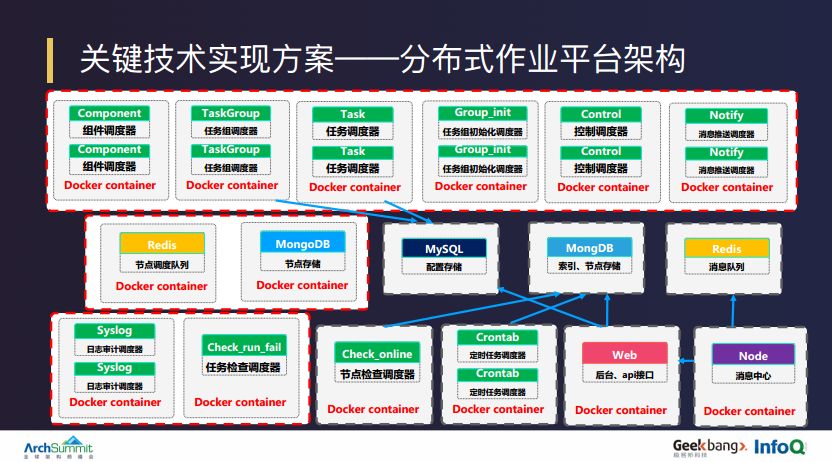
根据技术运营和日常运维的场景,陆金所自研了一套分布式作业平台,依托于微服务框架,由多个角色节点的容器组合而成,每个角色节点都可以根据自己设定的监控阈值进行水平动态伸缩,每个服务组件所负责的作业都可以按照作业特性进行全生命周期的状态管理。
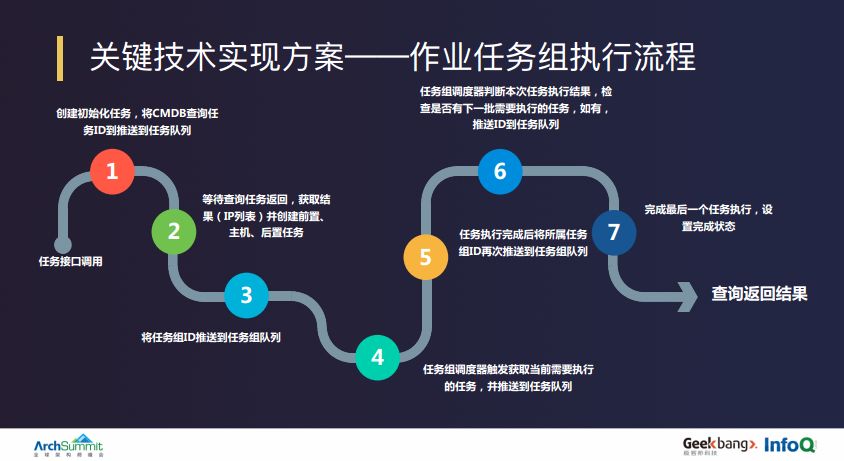
每个作业组的执行都是按照 7 个步骤,首先是下发 CMDB 主机任务,这其中有一个很关键的点——数据闭环,我们要求所有的切换作业或日常变更的数据都来自于 CMDB,最后的变更结果状态同样也要回流给 CMDB。接下来是初始化对应的后续作业任务,通过获取到的主机任务以及作业任务,把对应的任务压入任务队列,并通过任务的调度程序执行每个任务的串行或并行的任务调度与执行,任务调度结束之后,判断任务执行结果以及是否开始执行下一任务。这样往复执行,直到作业调度程度发现任务组已经全部执行完毕,汇总整个任务的执行状态,反馈给调用方。

在日常工作中,机房级别的切换其实是很少,所以整个切换平台不仅提供机房级别的一键切换服务,更多的是提供各个核心组件的切换服务,这些组件切换服务是日常运维或发现故障时,大家使用最多的。
上图是我们切换平台的主界面,左边是具体的服务目录,右上是整个可视化的流程展示,右下是执行任务具体的每一个执行结点、执行时间、状态进度等等的展示。
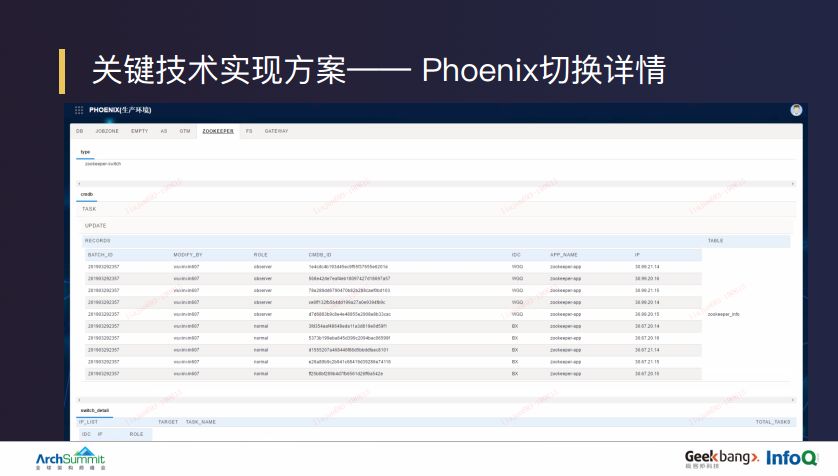
上图展示了切换组件的切换详情,我们内部业务把它称为切换计划。它主要展示的是组件的切换类型、切换动作、切换资源以及切换参数,同样也有对应的 CMDB 闭环原数据的更新逻辑。除此以外,我们还要求每个组件在正常的切换数据展示之外,还要在生成切换计划的时候,要提供组件切换异常时回滚的参数。我们在切换以前,会反复确认各个资源的属组、切换原数据的正确性,以保障切换动作的可靠性。
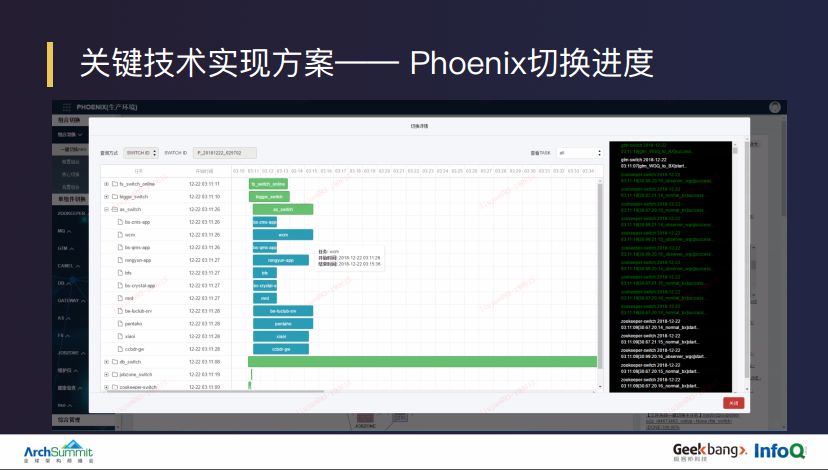
上图是切换进度页面,主要是给相对应的切换资源属组使用的,在切换过程中,各个切换的属组观察这个页面能够获取到核心组件的整体切换状态以及组件切换的里程碑。如果接着细化,可以迅速看到所负责组件的子分类和子任务的执行情况和执行耗时,当发现切换问题时能够第一时间发现并处理。
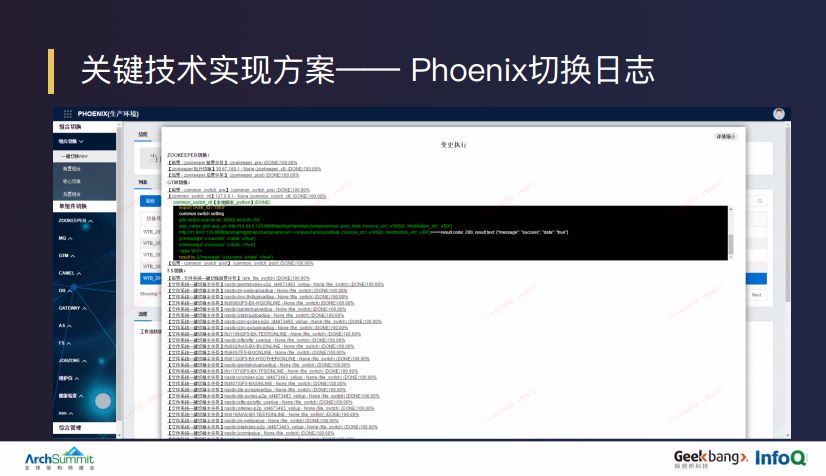
上图是切换日志的界面,如果切换正常,一般是不会去看日志的,但是当在切换过程中某些组件或动作发生错误时,切换操作人员会第一时间通过错误信息的指引迅速打开日志,定位到对应错误的任务,展开详细日志确认错误的具体情况,并决策这个错误需要通过什么样的方式和行为去处理。目前支持的行为有重试、回滚、忽略、暂停和终止。
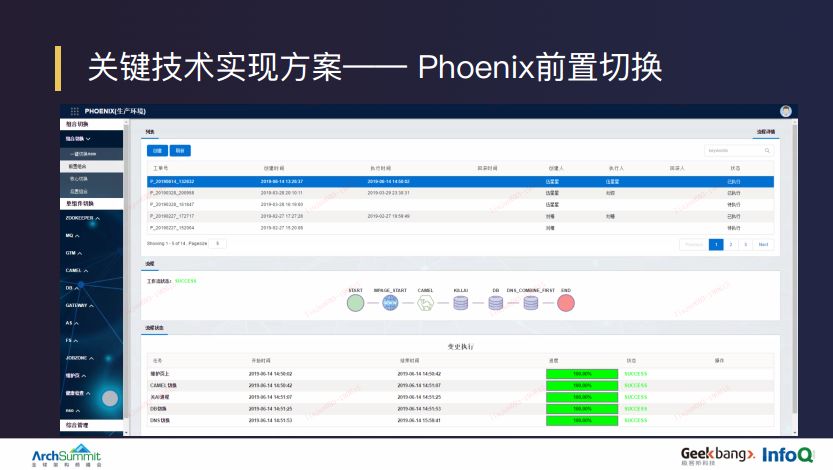
机房级别的切换过程主要可以分为三部分:前置、核心和后置。
前置的主要任务有以下几项:第一个全站挂维护页,在切换开始时,在陆金所外部的 Nginx 上下发一条指令让它把流量都切换到运维的这面,相当于是给用户明确的信息页面,防止在切换过程中流入外部流量;第二,在双活机房建设中会有一个流控层,默认策略是流控层的流量是落在本机房,不能有交叉访问,否则的话,如果切换开始,流控层还将流量引入原机房,那么会导致切换失败;第三,为后续核心组件和 DB 切换、DNS 切换做一些准备工作。

核心切换主要就是 7 大核心组件的并行切换过程,整个切换内容需要严格按照 ITIL 的实施标准,还要注意数据闭环,所有的数据要符合数据归档、CMDB 的数据闭环。
在设计初期,我们还是比较简单粗暴的,要求所有的组件不互相依赖,做完全的并行切换。但是在不断的演练实践过程中,我们做了更多的细化工作,每个组件依赖于不同的资源切换,但有些资源可能是同类项,所以我们把不同核心组件共有的资源配置在一起,只做一次切换。这样就避免每次切换都要并行地去做 DNS 切换或者 Nginx 相关的配置变更。众所周知,DNS 切换和 Nginx 的配置变更理论上是一次下发,但为了保证配置的可靠性,在真正的下发过程中是串行的,当我们把同类项资源放在一个环境中,整个效率就提高了,切换时间从 4 分 5 秒缩短到 4 分钟以内。
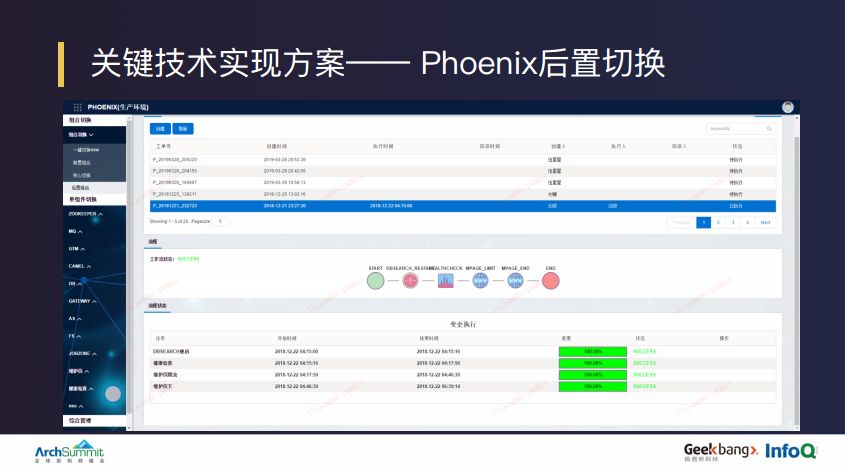
后置切换比较容易理解,当整个核心切换完成之后,后续要做的是对全站服务的自检。当后置服务的自检任务及后续的服务、限流等动作做完之后,整个切换工作就做完了。
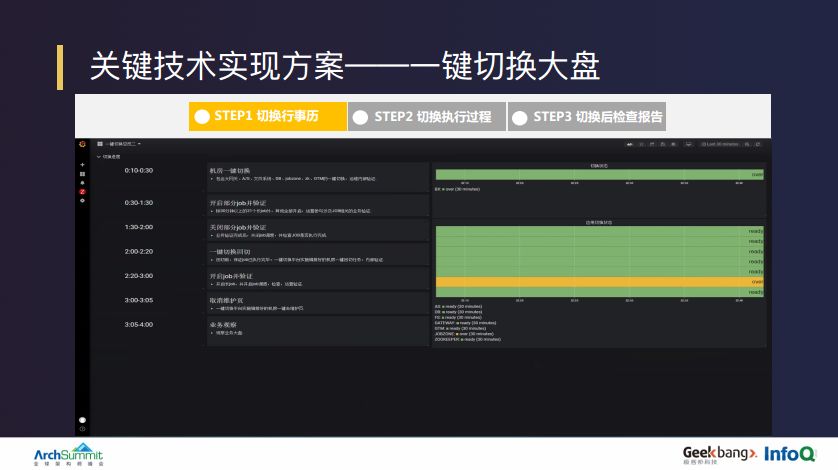
除了切换平台之外,切换大盘同样很重要。在切换之前,除了切换操作人员以外,参与日常切换演练的其它同学,例如开发、测试、架构、运维相关的同学,其实都不会使用到切换平台,大部分看的都是切换大盘。切换大盘在切换之前主要展示的是详细的切换行事历,主要目的是希望所有参与切换的同学能够十分清楚的了解这次切换的具体细节,以保证在整个切换过程中大家的信息是同步的。
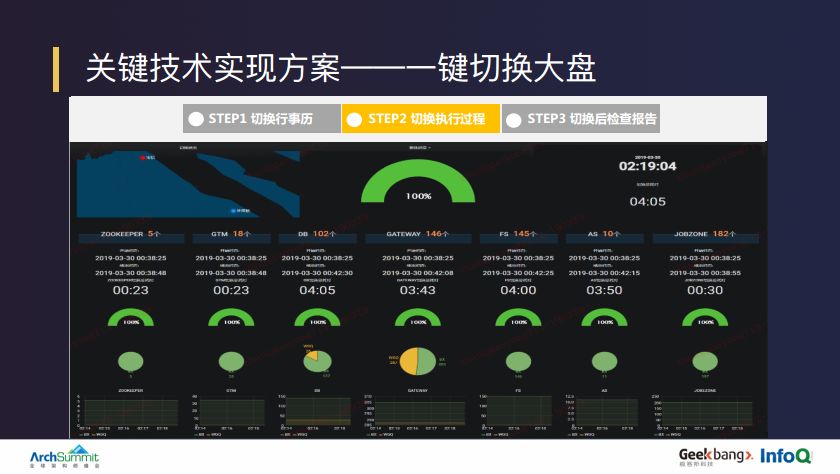
在核心组件切换大盘中,用户能够很直观的了解到各个组件的切换进展、整体的切换情况。
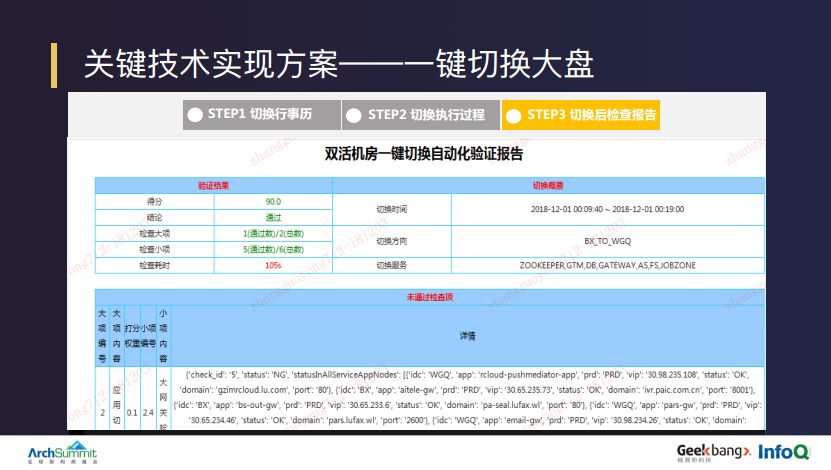
后置切换,主要是完成陆金所全站服务可用化的自检。自检结果会生成一个可用性报告,目的是让相关的切换同学比较直观的看到这次切换结果是不是和预期的一致。

除了切换工具,在整个切换过程中都会贯穿事前、事中和事后这三个步骤。我们要求的是,事前做好充分准备,事中做到统一行动,事后做到持续监控、观察和总结。
如果在切换过程中发现了问题,我们会持续跟踪,直到这个问题在下一次切换中得到优化和解决为止。这样做的目的是希望切换过程中所有相关的组件和服务能够都做到精益求精,把关键指标尽可能做到最好。
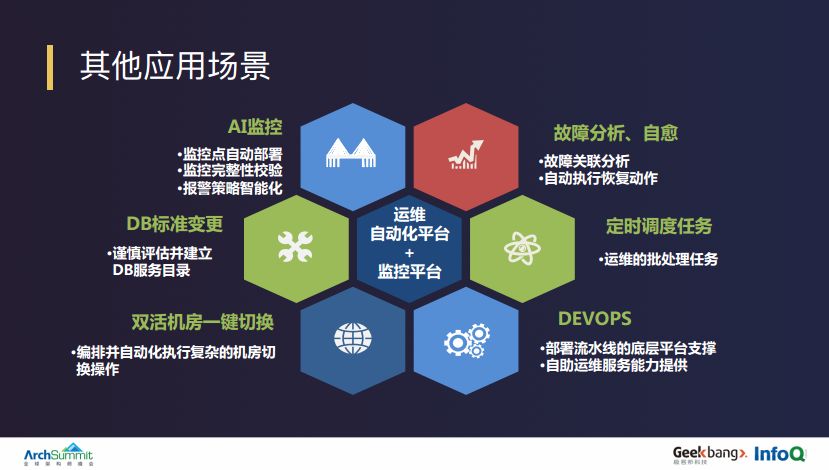
刚才说的 DevOps 流水线和自动化运维的技术框架,不但在切换服务中使用,而且也在陆金所技术运营相关的其它场景中使用。我们的标准化变更、监控、故障分析和自愈、整个 DevOps 全流程都是基于这一套技术体系搭建起来的,这套技术体系是陆金所运维中台核心的子系统。
简单介绍一下平台建设完成之后的收益。

切换平台上线交付之后,整个陆金所的技术运营能力得到了明显提升,它不但适用于陆金所内部的场景,而且在整个平安的体系内部也有很大的普适性,目前我们也在做整个框架的推广,希望能对金融领域的兄弟企业起到示范作用。
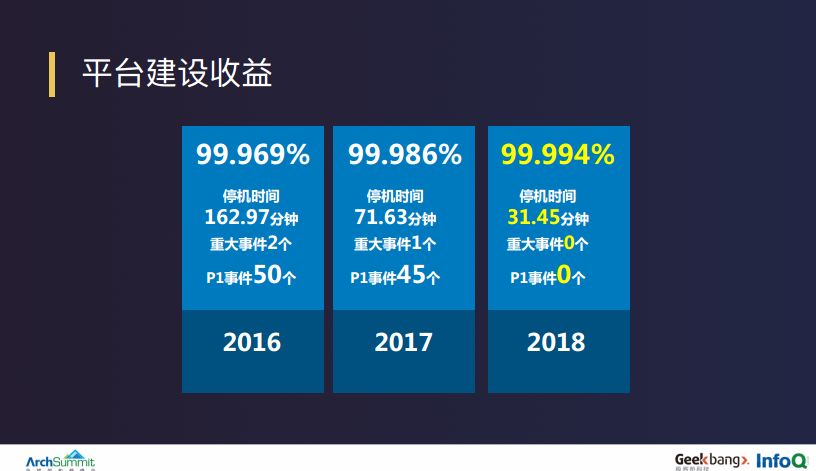
上图是直接带来的收益数据,陆金所本身的业务每年也在呈几何增长,但我们的服务支持、可用性在 2018 年达到了一个很好的水平,这完全依赖整个切换服务和架构改造。
最后,和大家分享一下整个陆金所多活机房的规划方向。
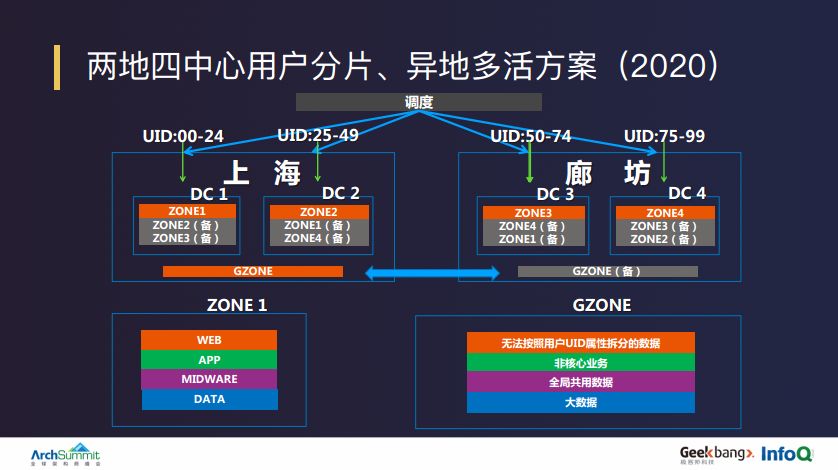
陆金所现在建成的是两地三中心,就是同城双活、异地灾备。异地灾备和同城双活现在的流量分配是 50:49:1,我们会分差不多 1% 不到的流量到河北廊坊的机房,让这个灾备机房永远是一个热的状态,但是承载相对少的流量,以确保在我们真正需要启用灾备的时候,能够迅速的把服务拉起来,并且确保服务的可用性。
2020 年,我们希望整个陆金所的服务状态能够达到两地四中心的服务多活形态。另外,我们也会把重心放在去“O”以及分库分表的工作上,因为只有达成这个目标,才能真正完成我们预期的多活服务治理形态。整个服务切换平台也会考虑更多异常情况,例如在真的极限情况下,切换是我们最优先考虑的方案,但是在一些可能达不到切换条件的异常场景时,我们会启用激活,激活不是做角色的切换,而是把原来主机房的主服务,直接从服务治理的一些集群中摘掉,把原来辅机房的备用服务启动为主服务。这是一个集群的有损方案,但当自动判断策略判定达不到切换效果时,我们会采用这种方式。
除此之外,我们现在还使用的是 Oracle、MySQL 这样的数据库,在金融行业中,我们现在看到的瓶颈或水桶原则最短的短板都是数据库,同行中的大部分企业还没有办法做到像 BAT 使用纯分布式数据库的架构来支撑。我们认为目前比较有普适价值的方式,就是去 O,通过自己的去 O 方式把 Oracle 切换效率低下、切换操作复杂、易出错的场景降到最低。当我们完成去 O 之后,就能做到基于用户级别的分库分表。这样,哪怕是在跨地域的情况下,也能做到切换过程不会因为延迟导致服务不可用或服务性能下降。
刘俊,陆金所技术运营部运维开发团队经理。2016 年 4 月入司至今,先后在规划管理团队和运维开发团队担任资深架构师、团队经理职务。负责陆金所核心 IT 技术运营系统的建设与保障工作,负责陆金所 DevOps 核心运营流程与工具链的持续优化改进以及技术运营相关业务的技术选型、方案制定与架构设计。同时也负责 IT 技术体系可用率保障的相关技术工作。

点个在看少个 bug 👇




