Cassandra 的过去、现在、未来

分享嘉宾:陈江 阿里云 高级专家
文章整理:许攸
内容来源:Cassandra Meetup
出品平台:DataFunTalk
注:欢迎转载,转载请留言。
导读:本次分享的主题为 Cassandra 的过去、现在和未来,主要包括:
❶ 起源:发展历史
❷ 现状:架构介绍
❸ 未来:4.0 release 新特性,社区前沿工作
▌过去
1. 源起
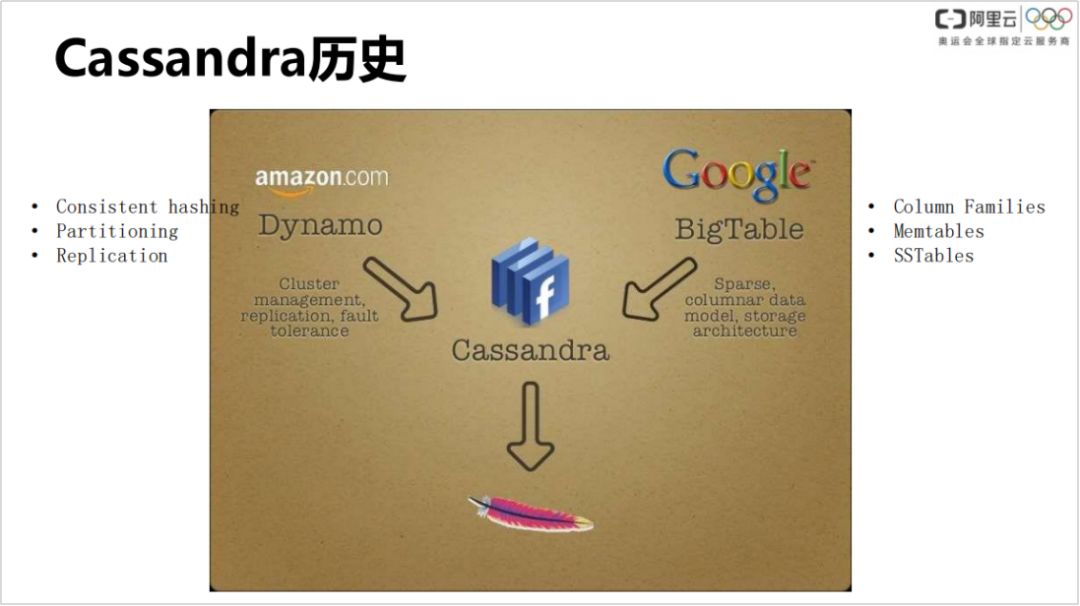
首先为什么会有 Cassandra 呢?
Cassandra 起源于早期非常著名的两个 table:google 的 BigTable 和 Amazon 的 Dynamo。Cassandra 从 BigTable 里面吸取了 LSM 单机引擎的精华,包括 Column Families、Memtables 和 SSTables;又从 Amazon 07年推出的 Dynamo Tabel 学习了怎么做分布式、怎么管理集群和灾难容错等经验。关于单机实现,Dynamo table 并没有披露太多,只提到一点 B-tree,基于此推测大概率是基于 sql 的 InnoDB 引擎。
2. 里程碑

Cassandra 主要的发展里程碑如下:
08年7月:facebook 发布 c*
09年:成为 apache 的孵化项目
10年:从 apache 项目毕业
11年:1.0版本发布,主要包括类似 levelB 的 leveled compaction。
13年:发布了 cas 和 trigger。
15年:3.0版本发布。
19年:4.0版本发布。
不得不说,Cassandra 能在当前比较有名,得益于 Facebook 当初做出了开源的决定。Facebook 最初08年发布 Cassandra 的时候,由于稳定性问题,内部并没有很看好,因此当时也没有大范围公开。但是他们很明智的放到了开源社区。经过在社区使用过程中的不断优化,变得越来越好,在当前 NoSql 宽表领域,Ccassandra 排名第一位。
3. 数据库排名
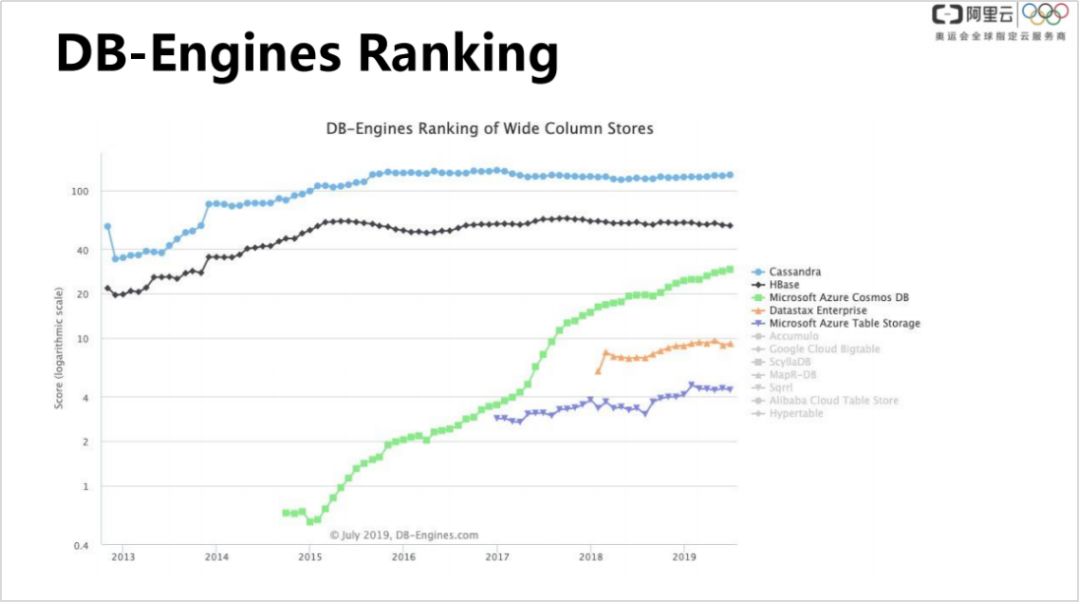
DB-Engines 的数据库排名在宽表领域对比了 Cassandra、Hbase、Microsoft Azure Cosmos DB 等比较著名的数据库,可以看到从13年 Cassandra 发布了2.0版本到现在,Cassandra 的表现都是一马当先的,热度远高于 HBbase 的。Cassandra 的热度在100以上,HBbase 大概只有50左右。
▌现在
1. 特征总览
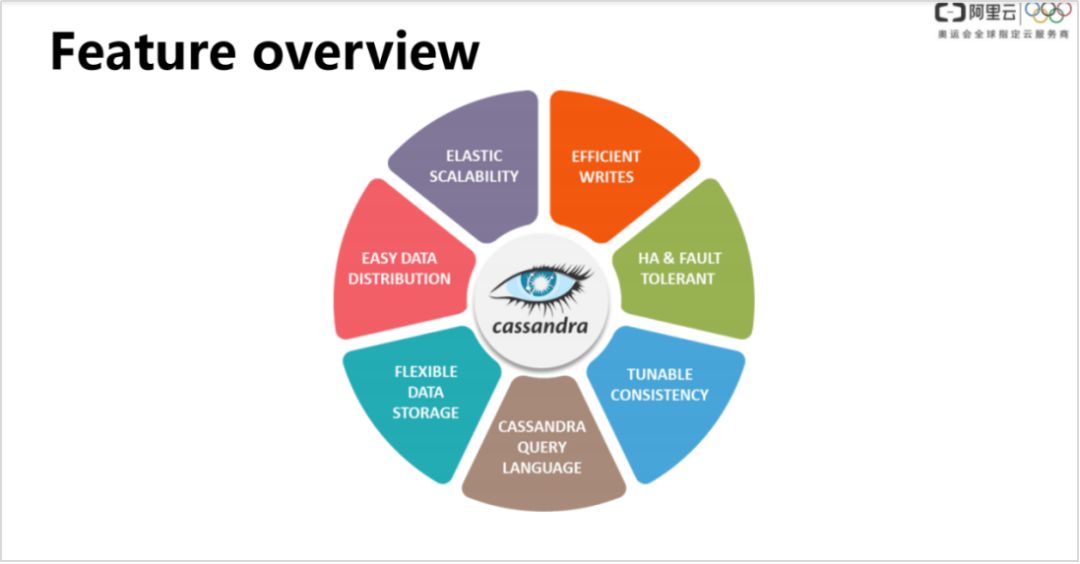
首先快速看下 Cassandra 的整体特点,对其有个整体的了解:
由于使用对等节点,因此易于扩展
由于采用 LSM 单机引擎,支持高效写入
高可用性和容错能力
可调一致性
支持 CQL 查询
弹性数据存储
易于做数据分布
2. 一致性 hash & gossip 去中心化
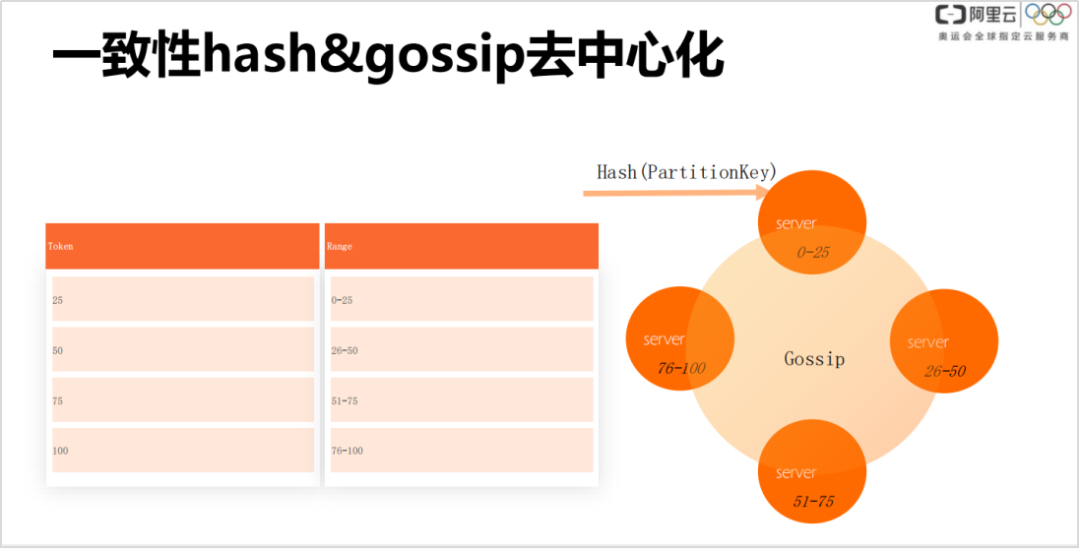
如果现阶段我们再去设计表格系统,猜想应该还是会设计成这样,一次性 hash 是非常经典的分布式方式。它的核心思路是通过客户端和 server 端一致认可的一种协议,找数据的分布,规避 master 节点。传统的很多设计都存在 master 节点,里面存储了数据分片,客户端先去 master 里面找到第一层路由,然后再和路由的后端节点做交互。但是通过一次性 hash,可以屏蔽掉路由表环节。客户端和后端有一种默认的公约,只要照着公约就可以直接找到后端节点。
大体思路是:gossip 上带有程序,可以取个 hash 整数,后端进行 server 其实也会有唯一节点,把唯一节点做成 id 排序,每个 server 会管理一个 range。所以对于一个主键在 Cassandra 里是会切出前半部分,算出 hash 值之后,在这个环里可以做映射。
由于 Cassandra 的元信息比较少,只有一些分布信息,以及每个 server 管理了哪些 range 等,信息非常少,没有必要额外再切出一个 master 管理信息,因此它使用 gossip 协议。Gossip 协议是一种 pear 2 pear 的消息通信传递架构,具有最终一致性。可能有很短暂的一瞬间,里面的一些元信息 ( 如 token 分布 ) 是不太一样的。
3. LSM 单机引擎
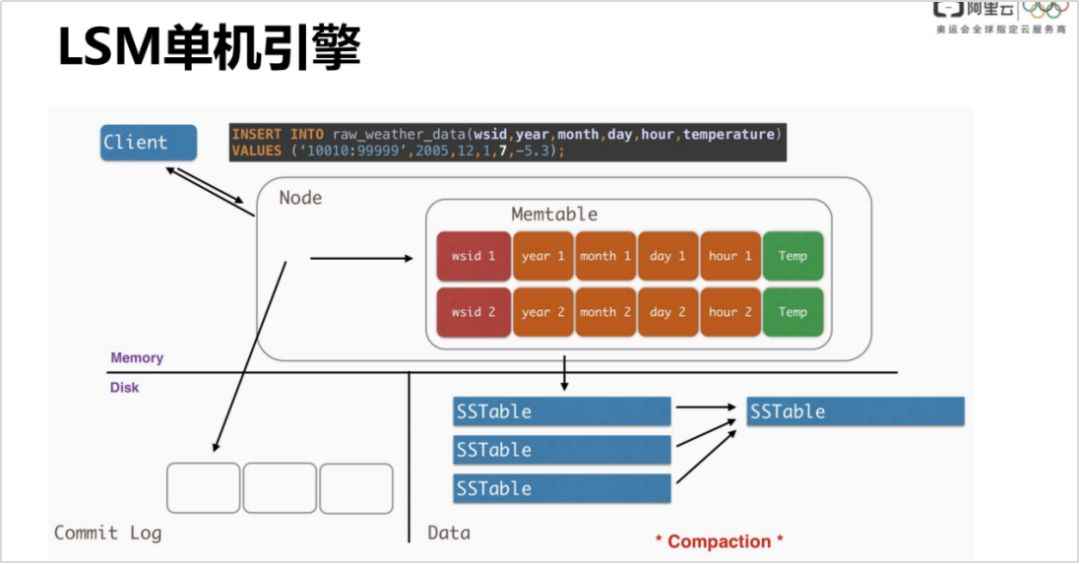
LSM 单机引擎现在已经不是一个很新的概念了,这里简单介绍一下:客户端按照一个 cql 写进来,在 Cassandra 里面这个叫做 replication,就是一次写。Cassandra 只能保证一次读和一次写是原子的,但是读跟写组合起来并不能保证是原子的。还有 cache 的操作,属于高级功能了,一次写写到后端的节点 ( node ) 里面,会先追加写 WAL ( Write-Ahead-Log ),然后会到 memtable 里面,当然里面有很多的优化,比如使用 memtable 这种方式,避免用户内存和 cornal space 内存的拷贝。
当 memtable 比较大时,列比较多的时候,会存成 SSTable,有三种 campaction 策略:基于使用窗口的,还有像 levelDB 一样基于 level 的,level0~level7,越往下数据越旧,SSTable 越大。
4. 使用现状

Cassandra 在各大公司都有广泛使用,这里列举了国内外一些大型公司的使用情况。Apple 有大范围使用 Cassandra,对外披露有 10W + nodes。国内360有使用,饿了么在推荐系统中也有使用。还有国外的一些巨头,像 Reddit 论坛平台和 discord 点餐平台也有在使用,比如 memcache 切到 Cassandra 主要是受限于内存。
5. 解决的问题 & 价值

① 随时在线
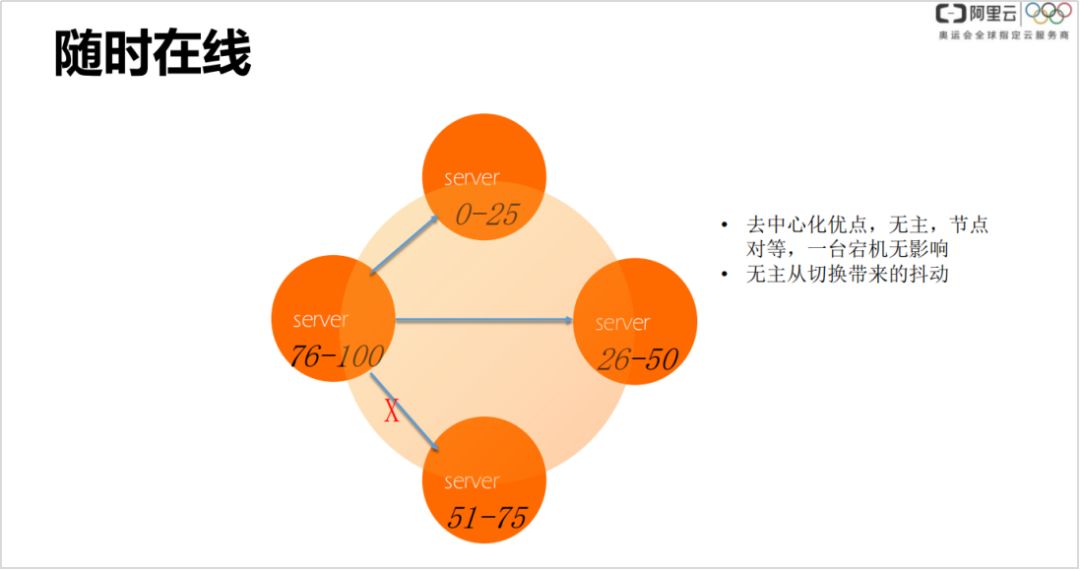
没有 master,多副本,具有可调一致性。比如挂了一台或者删掉一个副本,在一般的强制读模型下,是没有影响的。节点副本越多,冗余度越高,可接受的挂更多的节点。
无主从切换带来的抖动
② 线性扩展,易于运维
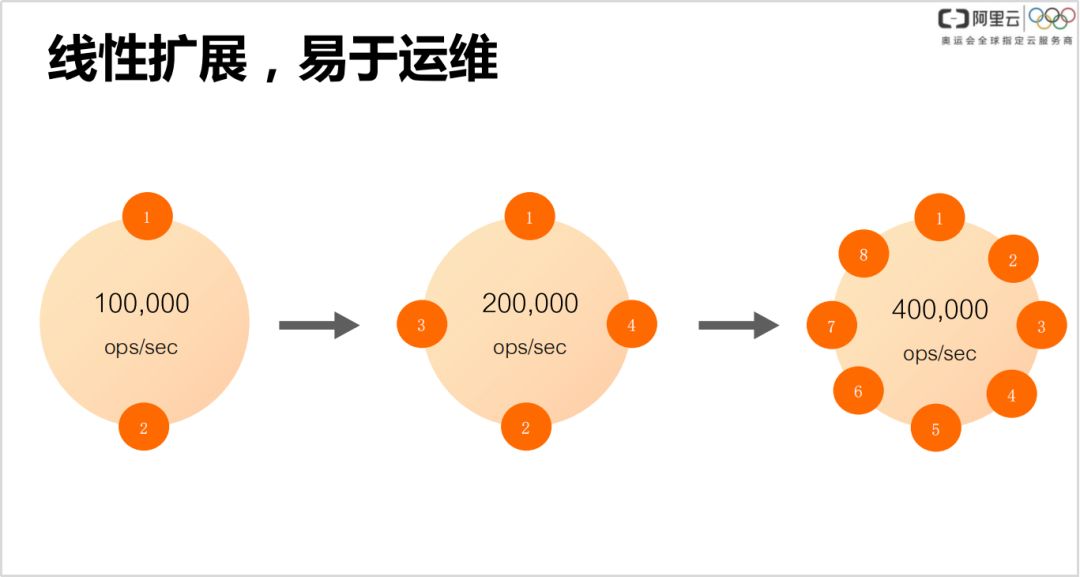
由于节点对等,可以进行线性扩展,因此非常易于运维。当集群扩展时,直接加一台机器就好了,绝大多数步骤都可以自动完成。因此很多公司都把商标做成一个环了,代表是可线性扩展的。
③ 多 DC,两地三中心
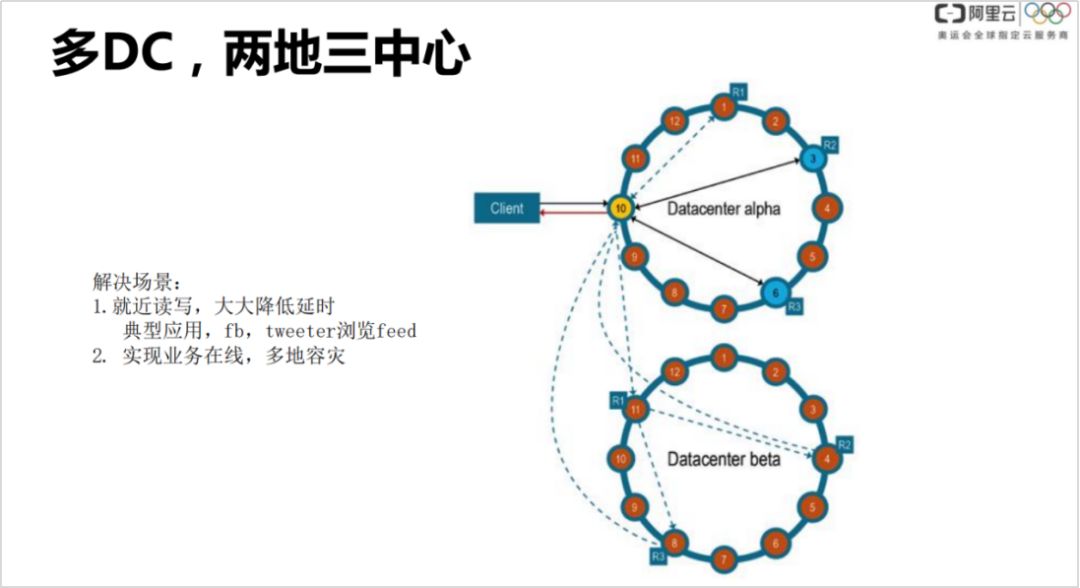
就近读写,大大降低延时。比如有个国际化的业务,在中国和国外皆有分布,比如 FB 的图片社交业务,国内和国外的用户都会发图片动态,我会关注国外朋友的图片动态,通过多 DC 可以就近读写,读的延时是很低的。
实现业务的多地容灾。比如某个地域发生地震,整个机房宕掉了,可以把业务的就近起一个 DC。
④ Cql + 丰富数据结构 + 类 jdbc driver

⑤ 完备的多语言客户端

有非常完备的多语言客户端,主流的语言都在里面,包括我们常用的 python、C++、Go、node JS、php 等日常使用比较多的语言。
6. 性能表现
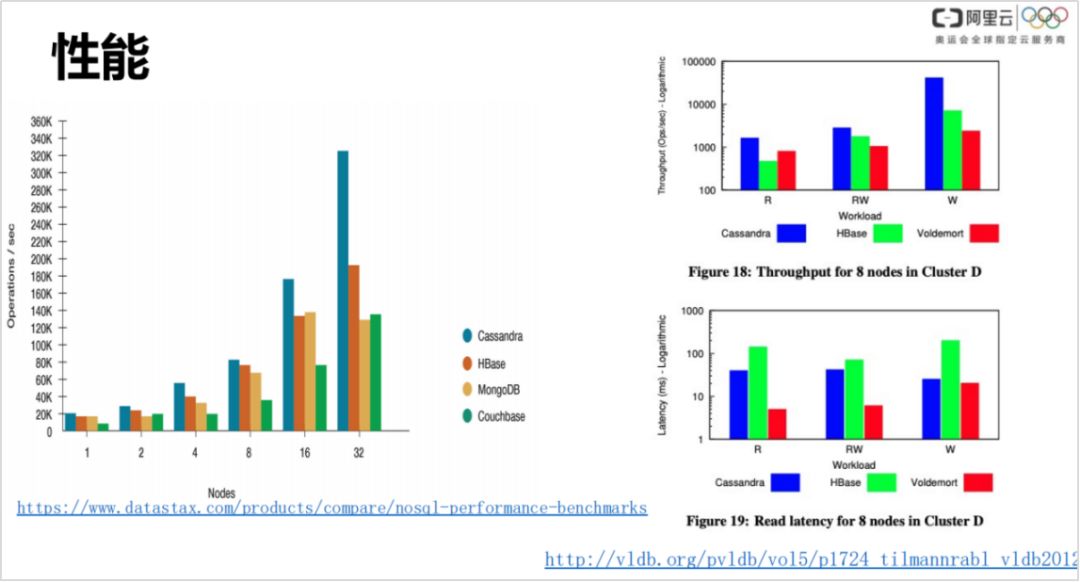
这是外部的一些权威的性能披露。左侧图对比了 Cassandra、HBase、MongoDB 和 Conchbase 的性能表现,右侧是比较有名的一篇论文,对比了 Cassandra、HBase 和 Voldemort 在延时、吞吐化方面的表现,Cassandra 的延时表现是优于 HBase 的。
7. 使用场景

下面我们讲一下 Cassandra 的使用场景,这里我分享一下自己的看法,以及自己论文的一些最佳实践。
① 不适合用的场景:
-
Cassandra 是一种 NoSql 的解决方案,很多 TP 的场景是不适合使用的。 -
不适用于先读后写的操作。
和其他数据库不太一样的地方,Cassandra 是一种无主的,反言之即 Cassandra 是一种多主的。多主的意思就是多个节点都可以操作,并不是都转发到一个节点上。在一个节点上很容易加锁,只要对某一行加锁,对所有的请求保持串行就可以了。所以对于独立行写其实是有冲突的,在 Cassandra 里面解决冲突的办法是很暴力的,就是 last write win ( 最后写入者获胜 ),因此导致 Cassandra 不适合做先读后写的操作。对于这种场景,Cassandra 建议使用 cas 的语法,但 cas 的性能比较差,因此使用 cassandra 时要避免冲突很多的场景。什么是冲突很多呢?比如多个手机用户同时更新一条数据,就是强冲突的。
② 使用场景
风控领域:用户画像库、爬虫、发欺诈系统、订单数据
个性推荐领域:用户行为分析、用户画像、推荐引擎和海量实时数据处理
大数据
社交 Feeds
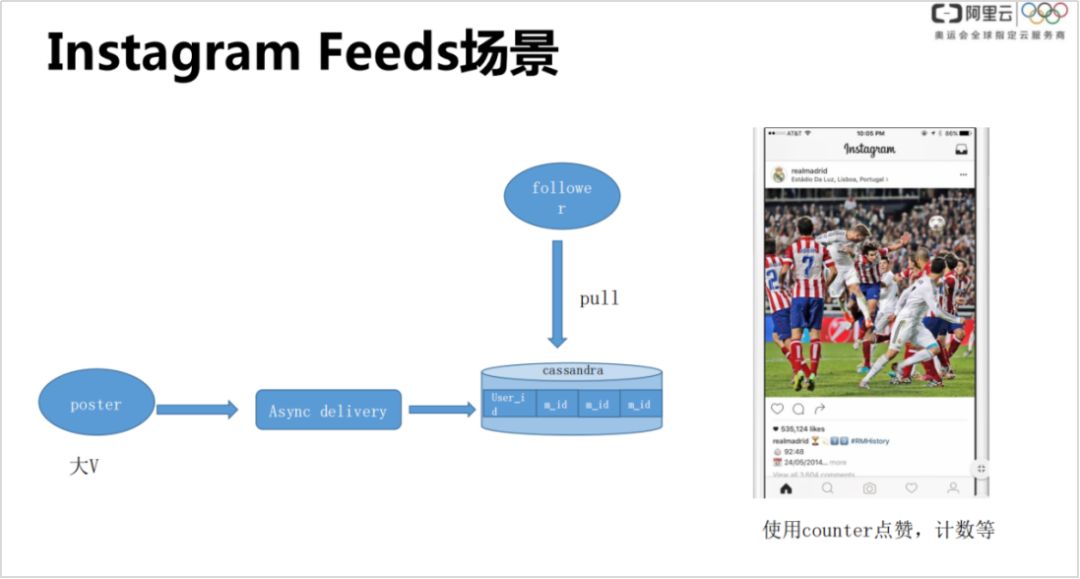
Instagram 的 Feeds 应用场景,与微博类似,大 V 会发图片和动态,同时一般也有很多的粉丝。当大 V 发图片或者动态,首先会有一个异步的推送 ( delivery ),把大 V 发布内容推到数据库里,然后粉丝读取大 V 动态的时候,再去拉取数据库的对应信息。比如川普有几千万的粉丝,对于每个粉丝都会去更新消息的 id,然后把信息写进来。对于每个粉丝,通过自己 id 查到对应的消息 id,再关联别的表查一下就可以获取到大 V 的动态。
这个例子充分利用了 Cassandra 的弹性扩展,一般传统的 sqlserver 只有单边节点,存储无论容量还是 ES 都是有限的。还使用了 Cassandra 的其他特性,比如 count 在 cassandra 里面都是分片计算的,效率非常高,因此点赞、计数这种场景做起来是没有压力的。
时空时序
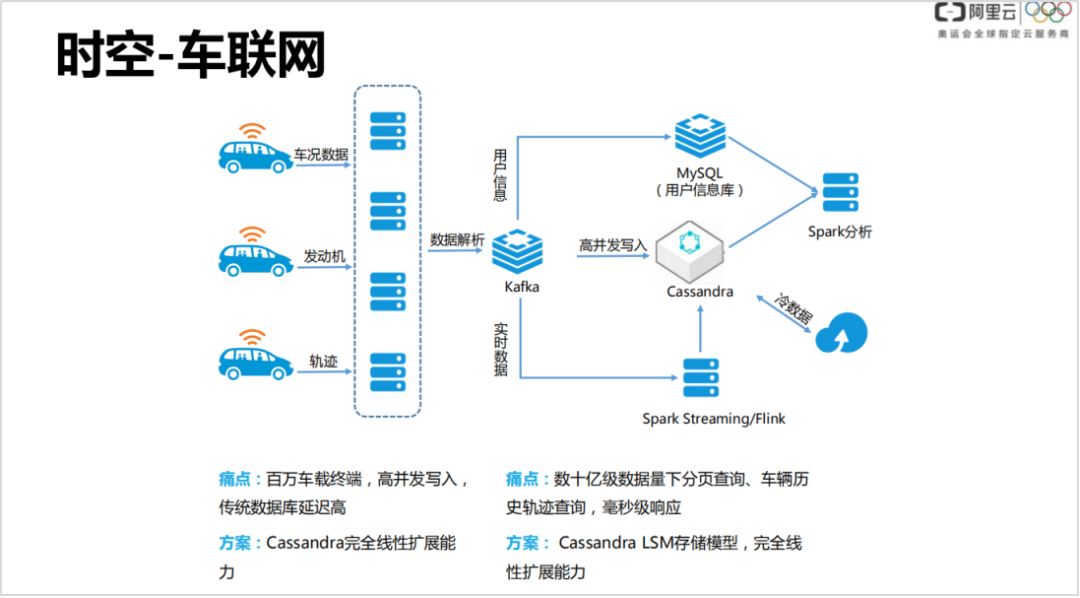
现阶段 IOT ( 物联网 ) 是比较热门的,有各种可穿戴设备,比如手表电话之类,还有像滴滴这样的公司,都会把数据实时上传到在线的数据库里。一般可能会做一些初期的 ETL 转换,在这个例子中使用 kafka、消息队列,然后有可能发的是比较快的,慢慢地把并发起到 Cassandra 里面,基于 Spark,或者基于某些数据,数据不断上传,对旧数据进行定期归档,存到备用。这种场景的特点是客户端非常多,像滴滴有上万台车同时在线地写入非常多的数据,数据量并发非常大。Cassandra 有个特点,是一个 LSM 的存储模型,写入性能非常高,扩展能力是很强的,整体集群扩展能力很高,通过加节点就能作线性扩展。
▌将来
1. 4.0版本发布

近期发布的 4.0-alpha,重点修复的功能点:
修复 incremental repair bug,推荐使用全量修复,但全量的修复是有问题的,会有很多重复的数据
Node 间通信优化为使用 netty,之前是自行研发,每个连接都会建立一个线程,处理效率比较慢
内嵌时间函数和算数操作符
可以说有非常大的改进,但是很遗憾没有从0到1的 feature
SASI & MV 仍标记为 Experience
2. 社区未来工作 ( NGCC 2019 )

可插拔引擎,并且可以支持 rocksdb 的引擎,因为 rocksdb 引擎实际上已经成为 LSM 的一种标准,对接到这里,基本代码可以不用运维,因此可以大大降低 GC,防止业务抖动
SideCar:因为 Cassandra 是无主的,没有传统意义上的 master 节点可以拉起,因此有个痛点--需要从每个节点上拉取部分信息。Sidecar 是个一站式运维平台,后面会详细介绍。
Scylladb: 改进了数据修复,传统的修复是比较废的,先去拉去 partition 粒度的 merkele tree ( 一个 hash tree ),逐个节点做比较。如果节点数据不一致,说明数据要做修复,修复也是比较暴力的,直接 pear 2 pear 的对拷,数据拷贝量是 double 的。
下一代 Cassandra compaction 的一个策略,也就是改进目前主流的 compaction 的一个优化,比如说 leveled compaction。
3. ROCKSANDRA
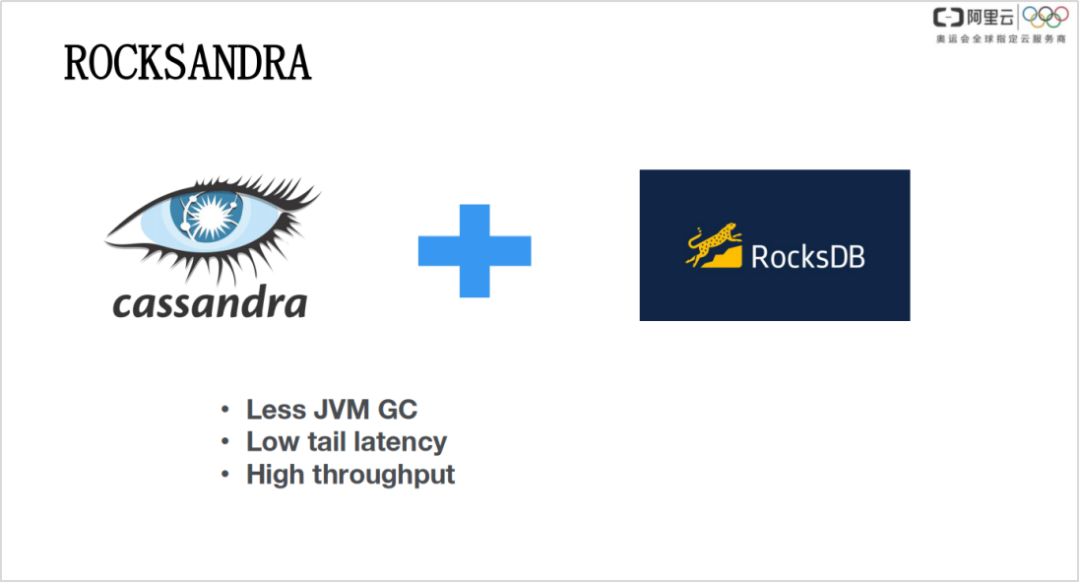
Rocksandra 是 Instagram 主要在做的一件事情,把 Cassandra 和 rocksDB 结合起来,可以实现更低的 JVM 的 GC 优化、解决长尾延时,并实现高吞吐。
4. Sidecar

Sidecar 是一个一站式运维平台:
传统的数据加入的 bootsrap 阶段和数据移动都可以在此完成
常用容错和操作的运维命令集成
配置升级
监控和指标
企业级的备份恢复,相当于是一个 dashboard,在这里可以进行备份和恢复
修复优化


陈江
——END——
文章推荐:

DataFunTalk:
专注于大数据、人工智能技术应用的分享与交流。

一个「在看」,一段时光!👇





