干货 | 三年拿到斯坦福CS博士的创业者李纪为:AI如何赋能金融

人工智能和金融,法律、医学等传统领域密切联系,金融科技正以前所未有的速度改变大众认知,这不仅驱动了传统金融业转型升级,也催生了诸多新金融业态。本次清华大数据“技术·前沿”系列讲座,我们荣幸地邀请到了香侬科技CEO李纪为博士,他从金融数据的获取、金融数据非结构到结构化、金融实体的用户画像等方面为大家分享了AI如何赋能金融。
公众号后台回复“AI金融”下载PPT全文

香侬科技创始人李纪为
李纪为:
今天非常有幸能跟各位探讨如何把人工智能的方法和知识,如语音、图像和自然语言处理等技术应用在金融领域。
在信息爆炸的时代,金融从业者的数目和其工作负荷量均逐年上升。从业人员如何在众多渠道中准确、快捷地获取需要的信息,并做出相应决策,显得尤为重要。其中找信息和根据信息做出交易决策分别对应AI里的不同应用。

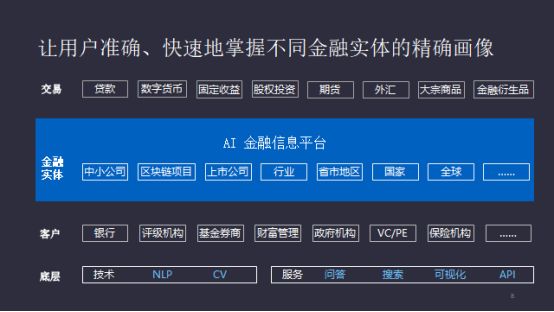
金融应用的直接的体现为股票、国债、贷款、固定收益、股权投资、主权基金,大宗商品、金融衍生品等,这些是金融实体的载体,比如说股票,它背后对应的是上市公司。如果要预估一个股票的涨跌,最重要的是了解它背后的金融实体发生了什么事,涉及到公司的收入、历史、运营情况,以及在整个大环境下,国家的金融趋势。其实就是涉及到对于不同金融实体的用户画像,即它们发生了什么,从何处获取这些信息。
交易类型连接的是金融实体和客户。从金融角度,我们需要从广泛的数据源里提取需要的信息,使整个过程变得有序、方便、及时和准确。从技术角度,应用人工智能技术,涉及到图像、自然语言处理等。从服务角度,提供什么样的服务取决于用户需求。
接下来我们探讨技术和落地场景的结合。我们并不缺少金融信息,却很难获得想要的数据,它们隐含在网上,可用性比较复杂,需要从非结构化变成结构化,如用算法把PDF、照片、表格等还原成文本数据,目前主流的解决办法是先把PDF变成图像,然后对该图像做解析,在图像里面获得所需要的文字或表格。
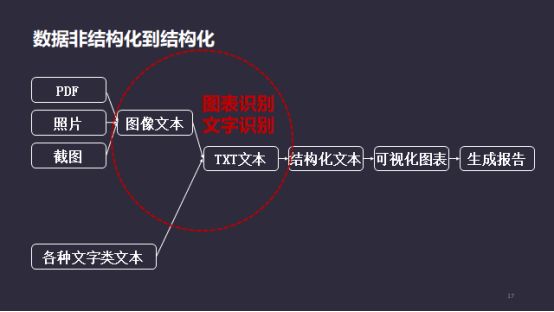
其中涉及大量的图表和文字的识别。举一个例子,将PDF中的表格转化为Excel形式。从图像处理的角度,第一步,把PDF转成图像,先把像表格的地方抽取出来。第二步,获取到该区域之后,把图像裁出来,再用图像处理。要把表格的位置从PDF里面裁出来,还是一个比较复杂的过程,需要标注很多的数据,比如这个表格的上下文。
当把该表格区域提出来时,还要识别里面的单元格以及单元格的文字,除此之外,单元格还可能涉及到大量的合并情况,需要运用比较复杂的算法。为了避免乱码,主流的解决办法是直接把它转成图像。

利用信息抽取的办法,我们可以把不可用的信息变得可用。用一个简单直观的算法直接把文本信息变成结构化的数据,比如,通过模型或算法就能自动地反馈出来想要的某些金融的数据指标。

其中涉及到自然语言处理的算法,其中一个模式是序列标注,可以用一项基于CRF的模型。CRF给出一个字符串,可以挑里面字符串的子串是否对应某一个或者几个不同指标。序列标注和问答在算法层面上处理的方式有所不同,如果两个模型得出一致的结果,我们就认为找到了对应答案。

从算法的层面,我们要抽取谁在哪里、做了什么。背后的算法相对复杂,原因就在于“做了什么”,人们可以做的事情非常多,难以在基于学习或者监督学习的体系框架内把这些不同类别的事件聚类。
除此之外,即便事情属于同一类,也有好坏之分。我们难以拿到大量的标志数据,既没法对这些事件进行全面定义又没法提出非常明确的标注细则。一旦没有标注,我们就没有训练数据,没有训练数据,就很难去训练基于监督类型的模型。
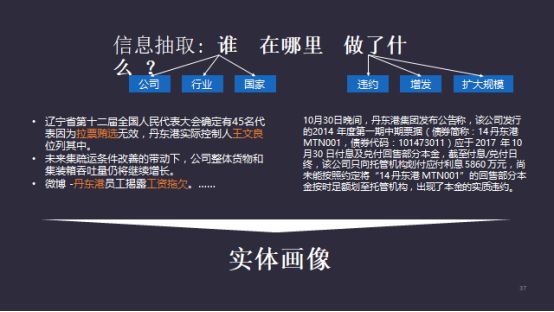
其背后涉及的算法叫做“human-in-the-loop”,如果把整个算法变成一个圈,人就在里面不停地干预。
第一步,可以对整个的文章以及里面的词、句和句法结构做无监督的聚类,比如LDA、PLSA或者是基于词向量的LDA等。而无监督的聚类算法有时不靠谱,需要通过人为标注了解类别是否有意义。
第二步,基于之前的标注,把标注的结果跟模型融合一起,可以再运行一个无监督的聚类。不断重复这个路径,模型迭代的结果会越来越好,人为标注的曲线和模型运行出的曲线开始逐渐趋近,得出不同的算法背的真正类别。从算法的角度讲,这个办法避免了大规模的人为标注的成本。

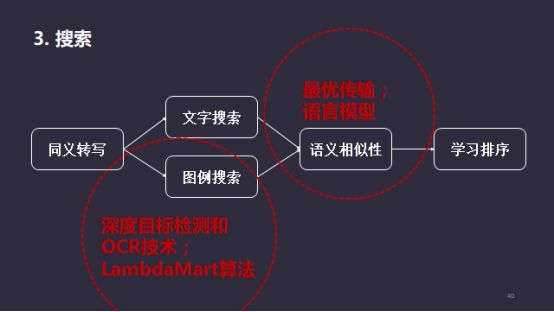
除此之外,实现方法还涉及语音相似度的分析、目标的检测、为用户提供的服务方式等。
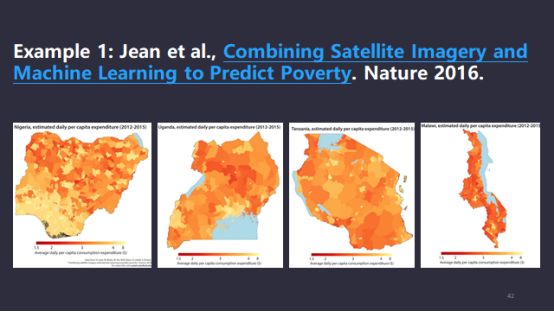
应用场景有很多。第一个例子,我们假设在非洲国家买国债。非洲国家的宏观经济数据或不披露,或存在报假情况,很难找到明确的指标,我们可以应用人工智能,比如大量的卫星云图的图像,2016年《Nature》里的相关文章指出这个国家的GDP、国情、人民生活水平甚至和晚上这个国家灯火的亮度有一定关系,我们可以把类似的情况落地,对它的GDP、CPI做宏观分析。
第二个例子,企业的风险画像。针对中小企业提供贷款担保和偷税问题,我们有两个维度可以衡量,一个是中小企业贷款时候声称的收入,另一个是可以找到企业所交的税,通过企业交的税反推出它今年大概的收入。从网上去找到大量的不同维度的数据,如公司法务、人员、行业的用户画像等就能够描述出来。
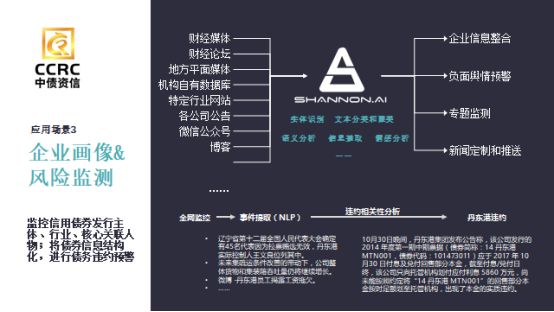
把技术手段和应用场景结合起来,从大量的数据源中提取有意义的信息,我们就可以提供大量的知识体系和信息为金融赋能。
公众号后台回复“AI金融”下载PPT全文
Ps:数据派给大家带福利啦,这么优秀的小哥哥正在招聘哦,感兴趣的小伙伴速速砸简历过来吧!
社招/校招/实习职位
后端开发工程师
自然语言处理(NLP)工程师
机器视觉工程师
前端开发工程师
运维工程师
爬虫工程师
金融数据分析师
行业研究员
职位具体信息:
1. 后端开发工程师
工作职责:
1. 后端基础架构和研发;
2. 分布式算法的设计与实现;
3. 高性能 Web 服务器开发
4. 自动化监控,AIOps框架研发
5. 在线业务系统、日志系统、自动化测试平台的设计与实现;
任职要求:
1. 重点大学本科及以上学历,计算机相关专业;
2. 掌握Golang / Python;
3. 熟悉 Linux 操作系统原理;
4. 有良好的数据结构和算法基础;
5. 熟悉MySQL/PostgreSQL 、Redis、消息队列、ELK等常用组件,并有能力进行定制化改进;
6. 有高并发大容量数据服务的设计和实现经验优先,有较好的产品意识优先。
2. 自然语言处理(NLP)工程师
工作职责:
1. 设计并优化用于金融文本的NLP算法;
2. 使用文本数据集,进行模型训练和测试;
3. 挖掘最新算法的使用场景,提升产品性能。
任职要求:
1. 重点大学本科及以上学历,计算机相关专业;
2. 掌握自然语言处理框架,比如tagging, parsing;
3. 掌握机器学习、深度学习基本理论知识;
4. 熟悉Python, C++, java 中的至少一门;
5. 有工程开发经验优先。
3. 机器视觉工程师
工作职责:
1. 掌握机器视觉前沿算法,并基于产品进行性能优化;
2. 设计、实施、和优化图像识别算法;
3. 参与图像识别、OCR,大规模图像分类等工作。
任职要求:
1. 重点大学本科及以上学历,计算机相关专业;
2. 理解、熟悉使用前沿图像识别算法
3. 至少熟悉C++、python 或者 java中的一门
4. 掌握TensorFlow或者Pytorch
5. 有较好的工程实现的能力,能够将算法落地到实际的产品中
4. 前端开发工程师
工作职责:
1. 参与Web前端系统的开发、调试、部署、维护;
2. 参与前端架构的研讨与设计,迭代技术框架;
3. 参与前后端数据交互接口设计;
4. 与UI设计师配合,对数据进行可视化展示。
任职要求:
1. 重点大学本科及以上学历,计算机相关专业;
2. 掌握web开发技术,比如HTML5、CSS3、ES6、熟悉常见的页面布局模型 (具有浏览器兼容性处理者优先)
3. 掌握vue.js框架或其它流行框架(angular, react),掌握webpack等基于node.js的开发工具;
4. 有移加端开发、数据可视化开发、网站性能优化经验优先。
5. 运维工程师
工作职责:
1. 负责运维系统的架构设计和开发,持续优化运维系统,提高运维效率;
2. 建立并完善监控报警体系,实现快速响应;
3. 负责公司网络安全,集群管理,构建paas平台。
任职要求:
1. 熟练掌握 Python,Shell,Go等语言,能独立开发运维工具;
2. 了解主流运维工具的配置、管理、使用,如Zabbix、Ganglia、Prometheus等;
3. 深入理解MySQL的运行机制和体系架构,能独立实施MySQL主备高可用方案,容灾备份;
4. 熟悉 Redis、Kafka、Mongodb、Elasticsearch等集群部署和管理;
5. 熟悉微服务架构,具有 Docker 和 K8S 相关的实施和运维经验;
6. 能基于 Gitlab、Jenkins 等开源工具搭建代码管理和持续集成环境。
6. 爬虫工程师
工作职责:
1. 负责开发分布式爬虫系统的开发与维护。
2. 负责爬虫框架的开发与维护。
3. 参与爬虫核心算法及调度策略优化。
4. 从网页中抽取、清洗、转换和存储数据。
5. 实时监控爬虫的进度和警报反馈。
任职要求:
1. 重点大学统招本科及以上学历。
2. 熟练掌握C/C++、Python、Java、Go中至少一门语言。
3. 熟悉HTML、JavaScript等前端技术,及HTTP、TCP/IP等协议。
4. 扎实的数据结构与算法基础。
5. 良好的团队合作精神及较强的沟通能力。
6. 善于学习新的知识,优秀的分析问题和解决问题的能力,对解决具有挑战性问题充满激情。
7. 金融数据分析师
工作职责:
1. 搜集各类数据,理解各类数据背后的经济金融含义;
2. 负责数据标注工作,制定数据标注的标准和规范。
任职要求:
1. 重点院校全日制本科以上学历;
2. 经济、金融、管理、会计等商科类专业优先;
3. 对待工作认真负责,对待数据严谨仔细;
4. 对金融行业感兴趣,对证券市场有基本的了解。
8. 行业研究员
工作职责:
1. 对相关行业和上市公司进行持续地跟踪和深入研究,把握行业走向和周期运行趋势,判断股票的投资价值;
2. 对接公司核心算法部门,提供产品需求以及二级市场的投研逻辑,不断丰富公司产品的内容和功能。
任职要求:
1. 重点院校全日制本科以上学历;
2. 具备证券公司、基金公司、保险资管等二级市场从业经历或者实习经历;
3. 具备较强的信息搜集能力、分析判断能力、沟通表达能力和良好的团队合作精神;
4. 证券从业资格、基金从业资格、CPA、CFA等资格证书者优先。
简历投递方式
校招网申时间:
2018.9.1-2018.10.15
投递邮箱:
hr@shannonai.com
邮件标题:
岗位-院校-姓名-联系电话(请以PDF形式投递简历)





