超难NLP新基准SuperGLUE正式发布:横扫SOTA模型BERT勉强过关

新智元原创
【新智元导读】Facebook AI Research、Google DeepMind、华盛顿大学和纽约大学合作,共同推出了SuperGLUE,这是一系列用来衡量现代高性能语言理解AI表现的基准测试任务,SuperGLUE针对的是已经达到挑战上限的会话式AI深度学习模型,为其提供更难的挑战,其比GLUE基准任务更负责,旨在构建能处理更加复杂和掌握更细微差别的语言模型。
目前NLP主要着眼在多任务学习和语言模型预训练,从而孕育出各种模型,如BERT、Transformer、Elmo、MT-DNN、GPT-2等。为了评估这些模型的精准度,GLUE基准应运而生。
GLUE全称是通用语言理解评估(General Language Understanding Evaluation),基于已有的9种英文语言理解任务,涵盖多种数据集大小、文本类型和难度。终极目标是推动研究,开发通用和强大的自然语言理解系统。
但随着NLP模型狂飙似的发展速度,仅推出一年时间的GLUE基准,已经显得有些力不从心。于是,Facebook AI研究院、谷歌DeepMind、华盛顿大学以及纽约大学4家公司和高校开始携手打造进化版新基准:SuperGLUE!
近日,进化后的基准也正式宣布上线,可供大家使用了!
地址:
https://gluebenchmark.com
因为BERT在GLUE上是当前最成功的方法,所以SuperGLUE也使用BERT-LARGE-CASED variant.11作为模型性能基准。
如果你搜索SuperGLUE,出现在首页的一定的各种胶水。这也是科技公司在给产品起名时特别喜欢玩儿的一个梗:利用命名的首字母缩写成为一个十分普通、十分常见的英文单词,这个单词经常和实际的科技产品毫不相关。
实际上,我们今天要介绍的SuperGLUE,全称是超(级)通用语言理解评估(Super General-Purpose Language Understanding Evaluation)。
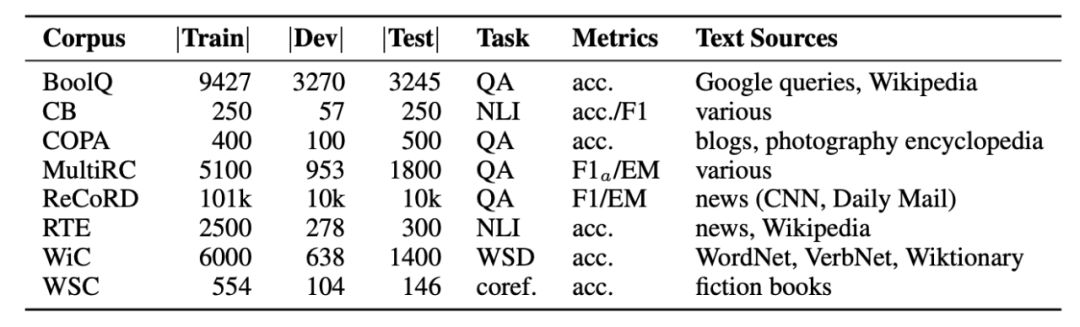
据SuperGLUE团队介绍,为了获得更强悍的任务集,他们向各个NLP社区发出了征集令,并最终获得一个包含约30种不同NLP任务的列表。随后按照如下标准筛选:
-
任务本质:即测试系统理解英语的能力 -
任务难度:即超出当前最先进模型的能力 -
可评估性:具备自动评断机制,同时还需要能够准确对应人类的判断或表现 -
公开数据:拥有可公开的数据 -
任务格式:提升输入值的复杂程度,允许出现复杂句子、段落和文章等 -
任务许可:所用数据必须获得研究和重新分发的许可



登录查看更多
相关内容
Arxiv
11+阅读 · 2019年10月30日
Arxiv
10+阅读 · 2019年9月15日




相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2019年10月30日
Arxiv
10+阅读 · 2019年9月15日