如何动手设计和构建推荐系统?看这里
选自 towardsdatascience
作者:Parul Pandey
机器之心编译
参与:陈韵莹、shooting
关于推荐系统,我们之前已经在相关文章中介绍了其概念、原理、目的等。本文中,作者进一步拓展,详细描述了设计和构建推荐系统的流程。最后,她还附上了一些推荐系统专用的 Python 库,以简化流程。

选择太少不好,但选择太多会导致瘫痪。
你听说过著名的果酱实验吗?在 2000 年,来自哥伦比亚大学和斯坦福大学的心理学家 Sheena Iyengar 和 Mark Lepper 基于现场实验提出了一项研究。
平常,消费者在当地食品市场的一家高档杂货店购物,那里有个试吃摊位提供了 24 种果酱。某天,同样的试吃摊位只提供了 6 种果酱。
这项实验的目的是判断哪种情况能获得更高的销量,预想的是更多种类的果酱能吸引更多的人,从而带来更多的生意。然而,研究人员观察到一种奇怪的现象:尽管摆上 24 种果酱时摊位吸引了更多人的兴趣,但与只呈上 6 种果酱时相比,销售额反而更低(大约是后者的十分之一)。

图源:The Paradox of Choice
所以为什么会这样?其实大量的选择看起来确实很有吸引力,但是过量的选择有时会让客户感到困惑和阻碍。因此,即使网上商店可以访问数以百万计的商品,但如果没有好的推荐系统,这些选择也会弊大于利。
在上一篇关于推荐系统的文章中,我们概述了神奇的推荐系统。现在让我们更深入地了解它的架构和与推荐系统相关的各种术语。
术语和架构
下面是与推荐系统相关的一些重要术语。
物品/文档
这些是系统推荐的实体,如 Netflix 上的电影,Youtube 上的视频和 Spotify 上的歌曲。
查询/上下文
系统利用一些信息来推荐上述物品,这些信息构成了查询信息。查询信息还可以是以下各项的组合:
用户信息,可能包括用户 ID 或用户先前交互过的物品。
一些额外的上下文信息,如用户设备、用户位置等。
嵌入
嵌入是将分类特征表示为连续值特征的一种方法。换句话说,嵌入是将高维向量转换到叫做嵌入空间的低维空间。在这种情况下,要推荐的查询或物品必须映射到嵌入空间。很多推荐系统依赖于学习查询和物品的适当嵌入表征。
资源地址:https://developers.google.com/machine-learning/glossary/#embeddings
上面是一个很好的推荐系统资源,值得一读。我在上面做了一些总结,但你可以详细研究它。它从整体角度描述了推荐系统,特别是从谷歌的角度。
架构概述
推荐系统常见的架构包括以下三个基本组件:
1. 候选生成
这是推荐系统的第一阶段,将用户过去活动中的事件作为输入,并从一个大型语料库中检索一小部分(数百)视频。主要有两种常见的候选生成方法:
基于内容的过滤
基于内容的过滤是指根据物品本身的属性来推荐物品。系统会给用户推荐与其过去喜欢的物品相类似的东西。
协同过滤
协同过滤依赖于用户-物品交互,并且基于相似用户喜欢类似事物的概念,例如购买某物品的客户也购买了此物品。
2. 评分
另一个模型通常以 10 分为满分进一步对候选集进行排名和评分,这构成了第二阶段。以 Youtube 为例,排名网络通过丰富的视频特征和用户特征获得期望的目标函数,基于此函数来为每个视频评分。按其分数排名,评分最高的视频将呈现给用户。
3. 重新排名
这是第三阶段,系统会考虑额外的限制,以确保多样性,新鲜度和公平性。例如,系统删除了之前用户明确不喜欢的内容,并且还考虑了网站上的任何新物品。
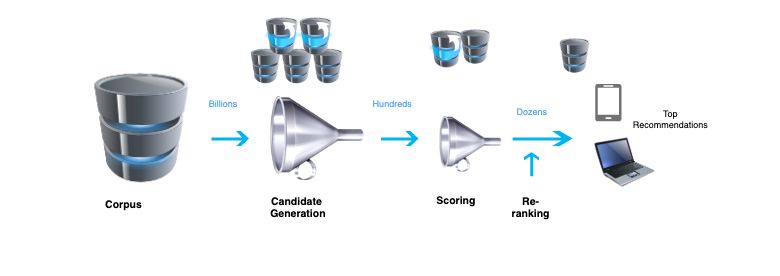
典型推荐系统的整体结构
相似度计算
你如何定义两个物品是否相似?事实证明,基于内容的过滤和协同过滤技术都应用了某种相似性度量。下面来看看两种度量方法。
假设有两部电影-电影 1 和电影 2 属于两种不同的类型。我们将两部电影绘制在二维图形上,如果电影不属于某一类别,则赋值为 0;如果电影属于某一类别,则赋值为 1。
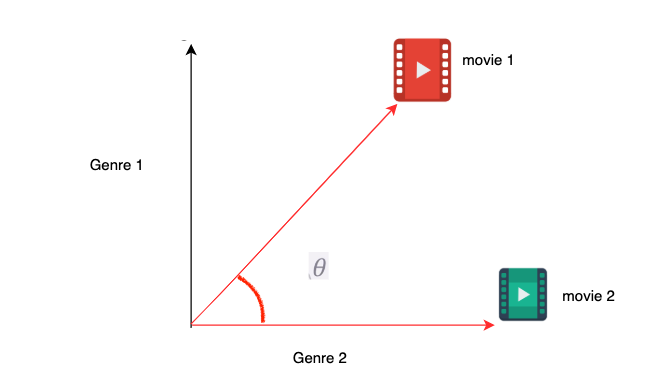
这里,电影 1(1,1)属于类别 1 和类别 2,而电影 2(1,0)只属于类别 2。这些坐标可以被看作是向量,这些向量之间的夹角告诉我们它们的相似度。
余弦相似度
计算两个向量之间夹角的余弦,similarity(movie1,movie2) = cos(movie1,movie2) = cos 45,结果约为 0.7。余弦为 1 时相似度最高,而余弦为 0 时表示相似度为 0。
点积
两个向量的点积是角的余弦乘以范数的乘积,即 similarity(movie1,movie2) = ||movie1|| ||movie 2|| cos(movie1,movie2)。
推荐系统流程
典型的推荐系统流程包括以下五个阶段:

典型的推荐系统流程
假设我们正在构建一个电影推荐系统。系统没有关于用户或电影的先验知识,只知道用户通过与电影进行交互给出的评分。下面是由电影 ID、用户 ID 和电影评分组成的数据帧。
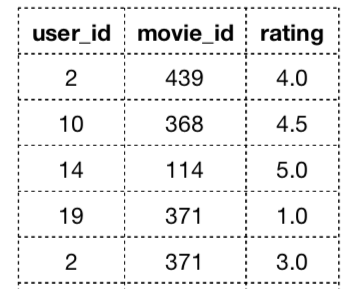
电影评分数据帧
因为我们只有自己打出的评分,可能不够公正,所以我们可以使用协同过滤来搭建推荐系统。
1. 预处理
效用矩阵变换
我们要先将电影评分数据帧转换为用户-物品矩阵,也称为效用矩阵(utility matrix)。
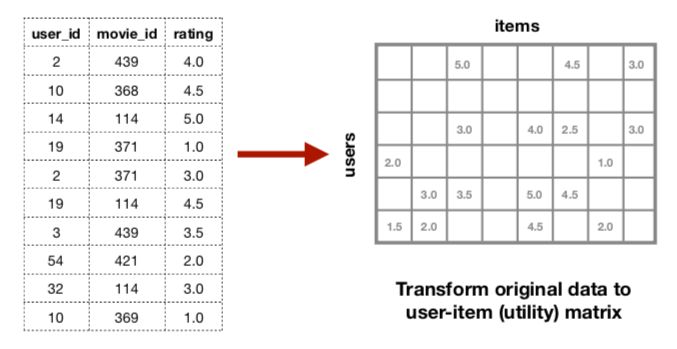
图源:https://2018.pycon.ca/fr/talks/talk-PC-55468/
矩阵的每个单元格都为用户对电影的评分。这个矩阵通常可用一个 scipy 稀疏矩阵来表示,因为一些特定的电影没有评分,所有许多单元格都是空的。如果数据稀疏,协同过滤就没什么用,所以我们需要计算矩阵的稀疏度。
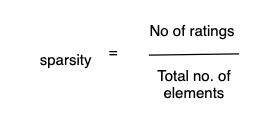
如果稀疏值达到 0.5 或以上,那么协同过滤可能就不适合了。这里需要注意的另一个重点是,空的单元格实际上代表新用户和新电影。因此,如果新用户的比例很高,那么我们可能会考虑使用其他推荐方法,如基于内容的过滤或混合过滤。
归一化
总是会有过于积极的用户(总是打 4 或 5 分)或过于消极的用户(评分都是 1 或 2)。因此,我们需要对评分进行归一化,以权衡用户和物品的偏差。这可以通过均值归一化来实现。
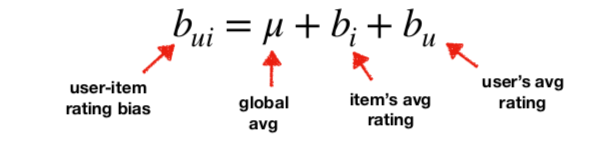
图源:Normalisation the Ratings
2. 模型训练
数据经过预处理后,我们要开始建模构建流程。矩阵分解是协同过滤中常用的一种技术,尽管也有其它方法,如邻域法(Neighbourhood method)。以下是相关步骤:
将用户-物品矩阵分解为两个潜在因子矩阵——用户因子矩阵和物品因子矩阵。
用户评分是由人生成的电影特征。我们认为这些可以直接观察到的特征很重要。然而,也有一些不可直接观察到的特定特征,它们在评分预测中也很重要。这些隐性特征被称为潜在特征(Latent Features)。
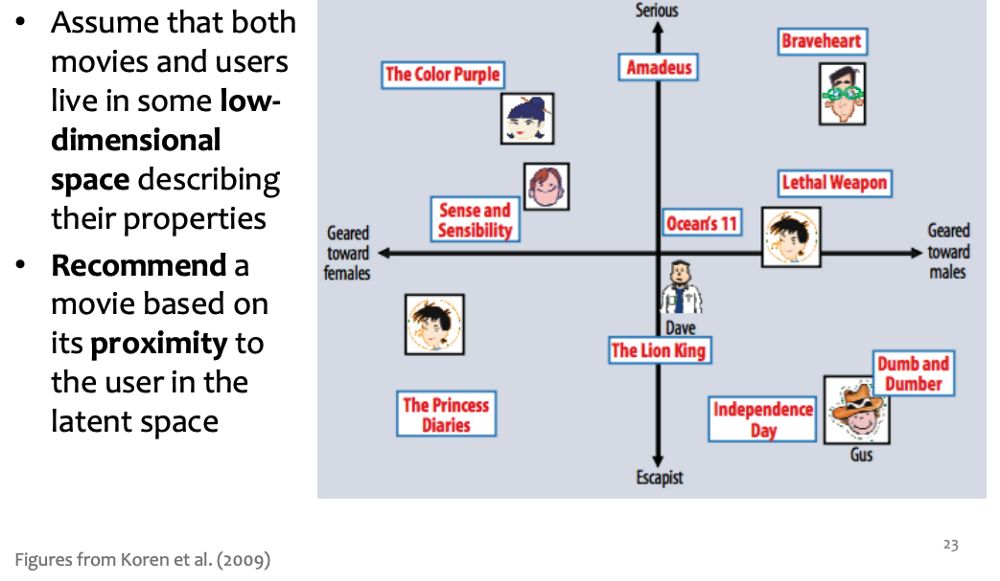
潜在因子方法的简单图示
潜在特征可以被认为是用户和物品之间交互的基础特性。本质上,我们不清楚每个潜在特征代表什么,但可以假设一个特征可能代表一个用户喜欢喜剧电影,另一个潜在特征可能代表该用户喜欢动画电影等等。
根据这两个潜在矩阵的内积(inner product)来预测缺失评分。
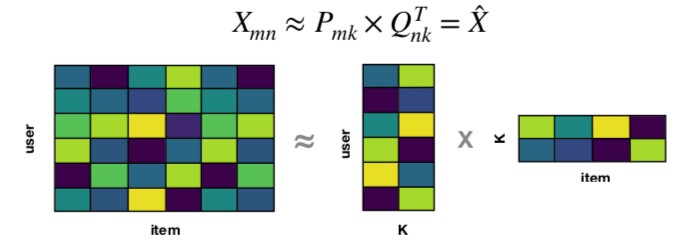
图源:https://2018.pycon.ca/fr/talks/talk-PC-55468/
这里的潜在因子用 K 表示。这个重建的矩阵补充了原始用户-物品矩阵中的空白单元格,因此现在已经知道未知的评分了。
但是我们如何实现上面所示的矩阵分解呢?好吧,事实证明,有很多方法可以做到这一点,方法如下:
交替最小二乘法(ALS)
随机梯度下降(SGD)
奇异值分解(SVD)
3.超参优化
在调参之前,我们需要挑选一个评估指标。对于推荐系统来说,普遍的评估指标是 Precision@K,它需要查看前 K 个推荐,并计算那些推荐中与用户实际相关的推荐所占的比例。
因此,我们的目标是找到给出最佳 Precision@K 的参数或者想要优化的任何其它评估指标。一旦找到参数,我们就可以重新训练模型,以获得预测的评分,并且我们可以使用这些结果生成推荐。
4. 后处理
然后我们可以对所有预测的评分进行排序,并为用户获得前 N 个推荐。我们还希望排除或过滤掉用户以前已经交互过的物品。就电影而言,没有必要推荐用户以前看过或不喜欢的电影。
5. 评估
我们之前已经讨论过这个问题,但我们在这里更详细地讨论一下。评估推荐系统的最佳方法是实践。像 A/B 测试这样的方法是最好的,因为我们可以从真实的用户那里得到真实的反馈。然而,如果这行不通,我们就必须求助于一些离线评估。
在传统的机器学习中,我们通过分割原始数据集来创建一个训练集和一个验证集。然而,这对于推荐系统模型不起作用,因为如果我们在一个用户群上训练所有数据然后在另一个用户群上验证它,模型不会起作用。
因此,对于推荐系统,我们实际上需要随机地屏蔽掉矩阵中一些已知的评分。然后,我们通过机器学习预测这些屏蔽的评分,然后将预测评分与实际评分进行比较。
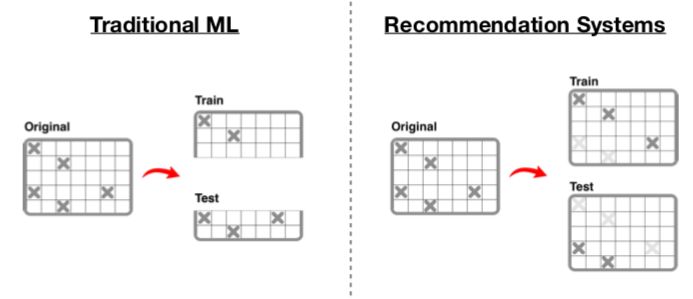
线下评估推荐系统
早前,我们讨论了 Precision 作为评估指标,这里还有一些其他指标可以使用。
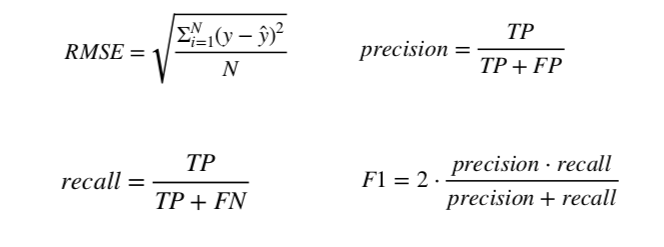
python 库
有许多专门为了推荐目的而创建的 python 库可供使用。以下是最受欢迎的几个:
Surprise:python scikit 构建和分析推荐的系统。
Implicit:针对隐式数据集的快速 Python 协同过滤。
LightFM:针对隐式和显式反馈,通过 Python 实现的很多流行推荐算法。
pyspark.mlibz*.*recommendation:Apache Spark 的机器学习 API。
结论
在本文中,我们讨论了推荐在缩小选择范围上的重要性。我们还讲述了设计和构建推荐系统的流程。实际上,Python 可以访问大量专门的库来简化这个过程。不如尝试使用一个来构建自己的个性化推荐引擎吧。

延伸阅读:
原文链接:https://towardsdatascience.com/recommendation-systems-in-the-real-world-51e3948772f3
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



