KSQL:Apache Kafka的开源流式SQL
点击上方“CSDN”,选择“置顶公众号”
关键时刻,第一时间送达!
作者丨Madison Moore
译者丨lloog
译者注:作者从好处、特点、下一步发展等多维度介绍Apache Kafka的开源流式SQL,KSQL。
KSQL是一个用于Apache katkatm的流式SQL引擎。KSQL降低了进入流处理的门槛,提供了一个简单的、完全交互式的SQL接口,用于处理Kafka的数据。你不再需要用Java或Python这样的编程语言编写代码了!KSQL是开源的(Apache 2.0许可)、分布式的、可扩展的、可靠的和实时的。它支持广泛的强大的流处理操作,包括聚合、连接、窗口、会话,等等。
一个简单的例子
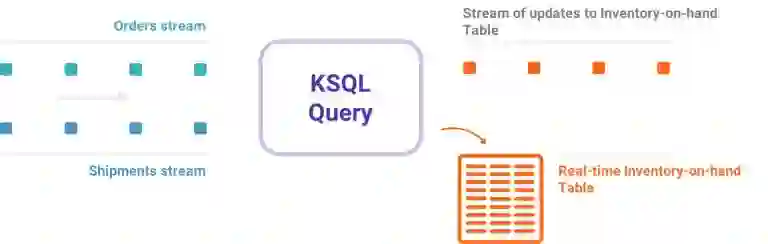
查询流数据是什么意思,这与SQL数据库有什么区别呢?
实际上,它与SQL数据库有很大的不同。大多数数据库都用于对存储数据进行按需查找和修改。KSQL不进行查找(但是),它所做的是连续的转换——也就是,流处理。例如,假设我有一个来自用户的点击流,以及一个关于这些用户不断更新的帐户信息的表。KSQL允许我对这一串单击和用户表进行建模,并将两者结合在一起。即使这两件事之一是无限的。
因此,KSQL所运行的是连续查询——在Kafka主题的数据流中,连续不断地运行新数据。相反,传统数据库对关系数据库的查询是一次性查询——在数据库中运行一次SELECT语句获取有限行的数据集。
KSQL的好处是什么?
很好,所以你可以不断地查询无限的数据流。这有什么好处?
1. 实时监控实时分析
CREATE TABLE error_counts AS
SELECT error_code, count(*)FROM monitoring_stream
WINDOW TUMBLING (SIZE 1 MINUTE)
WHERE type = 'ERROR'
其中的一个用途是定义定制的业务级度量,这些度量是实时计算的,您可以监视和警报,就像您的CPU负载一样。另一个用途是在KSQL中定义应用程序的正确性的概念,并检查它在生产过程中是否会遇到这个问题。通常,当我们想到监控时,我们会想到计数器和仪表跟踪低水平的性能统计。这些类型的测量器通常可以告诉你CPU负载很高,但是它们不能真正告诉你你的应用程序是否在做它应该做的事情。KSQL允许从应用程序生成的原始事件流中定义定制指标,无论它们是日志事件、数据库更新还是其他类型的事件。
例如,一个web应用程序可能需要检查,每次新客户注册一个受欢迎的电子邮件,创建一个新的用户记录,并且他们的信用卡被计费。这些功能可能分布在不同的服务或应用程序中,您可能希望监视每个新客户在SLA中发生的每一件事,比如30秒。
2. 安全性和异常检测
CREATE STREAM possible_fraud AS
SELECT card_number, count(*)
FROM authorization_attempts
WINDOW TUMBLING (SIZE 5 SECONDS)
GROUP BY card_number
HAVING count(*) > 3;
这是您在上面的演示中看到的一个简单的版本:KSQL查询,它将事件流转换为数值时间序列,使用Kafka-Elastic连接器将其注入到弹性中,并在Grafana UI中可视化。安全用例通常看起来很像监视和分析。而不是监视应用程序的行为或业务行为,您正在寻找欺诈、滥用、垃圾邮件、入侵或其他不良行为的模式。KSQL提供了一种简单、复杂和实时的方式来定义这些模式和查询实时流。
3. 在线数据集成
CREATE STREAM vip_users AS
SELECT userid, page, action
FROM clickstream c
LEFT JOIN users u ON c.userid = u.user_id
WHERE u.level = 'Platinum';
在公司中完成的大部分数据处理都属于数据丰富的领域:从几个数据库中提取数据,转换它,将其连接到一个键值存储、搜索索引、缓存或其他数据服务系统中。在很长一段时间内,用于数据集成的ETL-提取、转换和加载-作为周期性的批处理作业执行。例如,实时转储原始数据,然后每隔几个小时转换一次,以实现高效的查询。对于许多用例来说,这种延迟是不可接受的。KSQL与Kafka的连接器一起使用时,可以从批处理数据集成到在线数据集成。您可以使用流-表连接存储在表中的元数据来丰富数据流,或者在将流加载到另一个系统之前对PII(个人可识别的信息)进行简单的过滤。
4. 应用程序开发
许多应用程序将输入流转换为输出流。 例如,负责重新排序在线商店库存不足的产品的流程可能会产生销售和出货流,以计算出订单流。
对于用Java编写的更复杂的应用程序来说,Kafka的原生流API可能帮助不大。但是对于简单的应用程序,或者对Java编程不感兴趣的团队来说,一个简单的SQL接口可能就是他们想要的。
KSQL中的核心抽象
KSQL在内部使用Kafka的Streams API,并且它们共享与Kafka流处理相同的核心抽象。 KSQL有两个核心抽象,它们映射到Kafka Streams中的两个核心抽象,并允许您操纵Kafka主题:
1. 流:流是无限制的结构化数据序列(“事实”)。 例如,我们可以有一个金融交易流,例如“Alice向Bob发送了100美元,然后查理向鲍勃发送了50美元”。 流中的事实是不可变的,这意味着可以将新事实插入到流中,但是现有事实永远不会被更新或删除。 流可以从Kafka主题创建,或者从现有的流和表中派生。
CREATE STREAM pageviews (viewtime BIGINT, userid VARCHAR, pageid VARCHAR)
WITH (kafka_topic='pageviews', value_format=’JSON’);
2. 表:一个表是一个流或另一个表的视图,它代表了一个不断变化的事实的集合。例如,我们可以拥有一个包含最新财务信息的表,例如“Bob的经常帐户余额为$150”。它相当于传统的数据库表,但通过流化等流语义来丰富。表中的事实是可变的,这意味着可以将新的事实插入到表中,现有的事实可以被更新或删除。可以从Kafka主题中创建表,也可以从现有的流和表中派生表。
CREATE TABLE users (registertime BIGINT, gender VARCHAR, regionid VARCHAR, userid VARCHAR)
WITH (kafka_topic='users', value_format='DELIMITED');
KSQL简化了流应用程序,因为它完全集成了表和流的概念,允许使用表示现在发生的事件的流来连接表示当前状态的表。 Apache Kafka中的一个主题可以表示为KSQL中的STREAM或TABLE,具体取决于主题处理的预期语义。 例如,如果要将主题中的数据作为一系列独立值读取,则可以使用CREATE STREAM。此类流的一个例子是捕获页面视图事件,其中每个页面视图事件都不相关且独立于另一个页面视图事件。另一方面,如果您希望将某个主题中的数据读取为可更新的值的集合,那么您将使用CREATE TABLE。在KSQL中应该读取一个主题的示例,它捕获用户元数据,其中每个事件代表特定用户id的最新元数据,如用户的姓名、地址或首选项。
KSQL:实时点击流分析和异常检测
让我们来看一个真正的例子。这个例子展示如何使用KSQL进行实时监视、异常检测和警报。对clickstream数据的实时日志分析可以采取多种形式。在本例中,我们将标记在web服务器上消耗过多带宽的恶意用户会话。监视恶意用户会话是会话化的众多应用之一。但从广义上说,会话是用户行为分析的基础。一旦您将用户和事件关联到一个特定的会话标识符,您就可以构建许多类型的分析,从简单的度量,例如访问计数。我们通过展示如何在Elastic支持的Grafana仪表板上实时显示KSQL查询的输出,来结束这个例子。
您也可以按照我们的指示,亲自完成例子,并查看代码。
看看里面
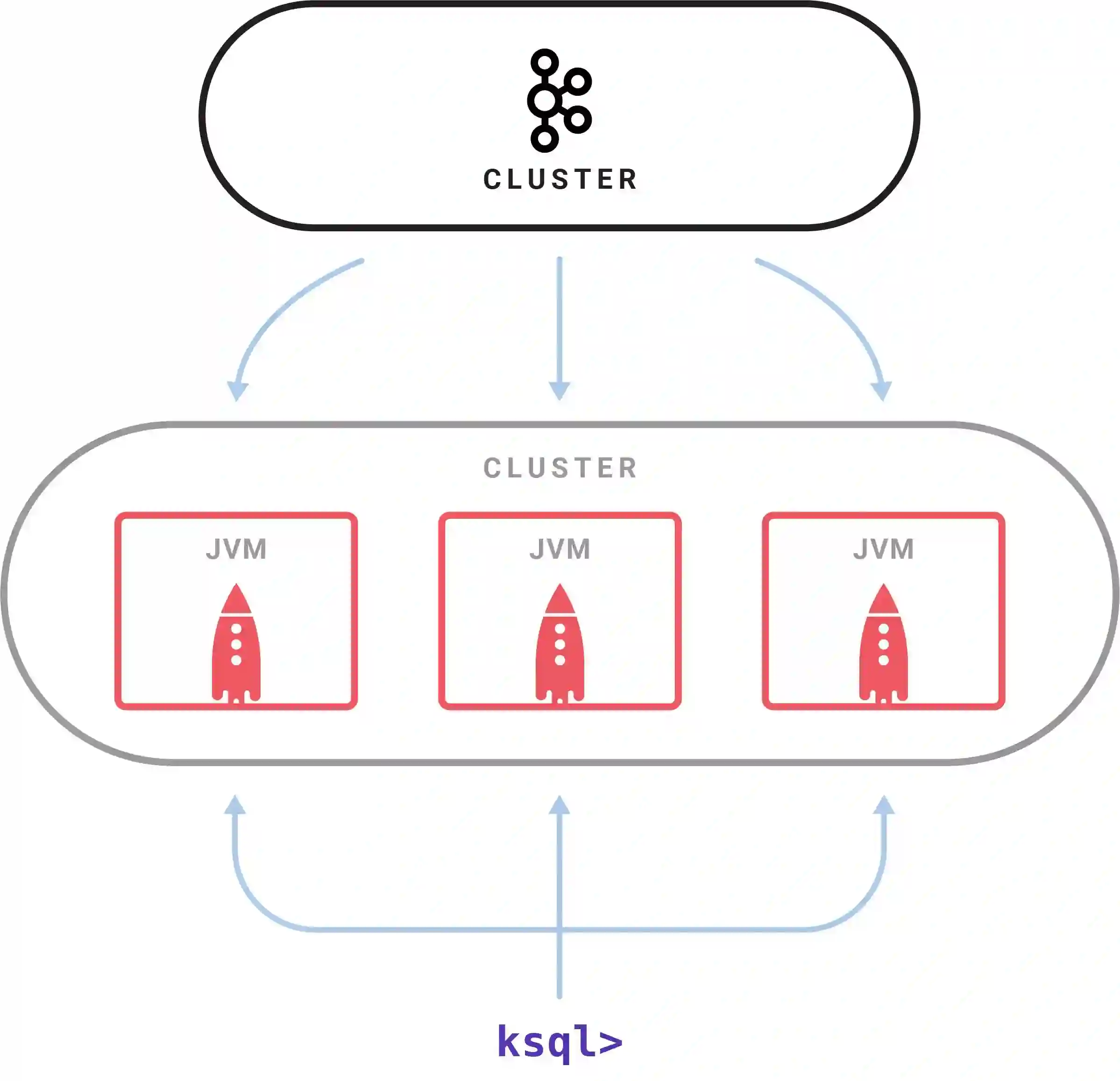
有一个KSQL服务器进程执行查询。一组KSQL进程作为集群运行。您可以通过启动更多的KSQL server实例来动态添加更多的处理能力。这些实例是容错的:如果一个失败了,其他的就会接管它的工作。查询是使用交互式的KSQL命令行客户端启动的,该客户端通过REST API向集群发送命令。命令行允许检查可用的流和表,发出新的查询,检查状态并终止正在运行的查询。KSQL内部是使用Kafka的流API构建的;它继承了它的弹性可伸缩性、先进的状态管理和容错功能,并支持Kafka最近引入的一次性处理语义。KSQL服务器将此嵌入到一个分布式SQL引擎中(包括一些用于查询性能的自动字节代码生成)和一个用于查询和控制的REST API。
Kafka + KSQL将数据库转出来
过去我们已经讨论过将数据库转入内部,现在我们通过向内向外的DB添加一个SQL层来实现。
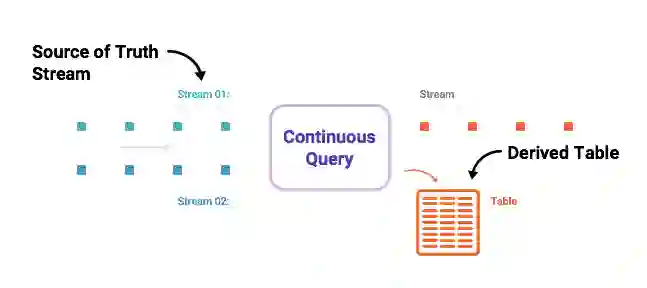
在关系数据库中,表是核心抽象,日志是一个实现细节。 在以数据库为中心的事件世界中,核心抽象不是表; 它是日志。 这些表只是从日志导出的,并随着新数据到达日志而不断更新。 中央日志是Kafka,KSQL是引擎,允许您创建所需的物化视图,并将其表示为不断更新的表。
然后,您可以以这种流式表格方式运行即时查询(即将在KSQL中),以便以持续的方式获取日志中每个键的最新值。
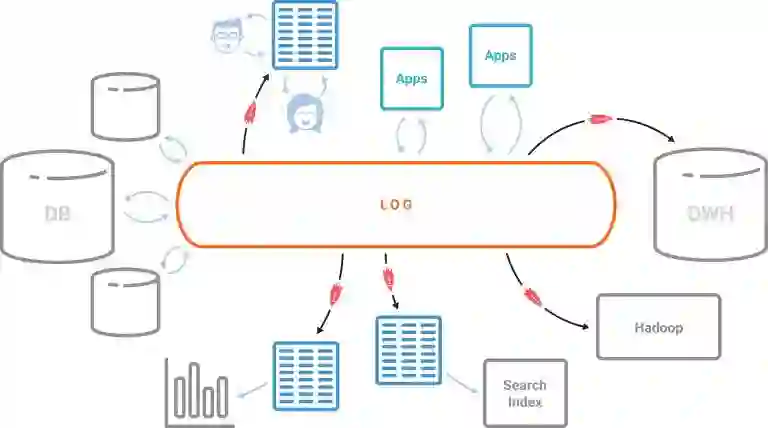
使用Kafka和KSQL将数据库转出,对一家公司的所有数据都有很大的影响,这些数据可以自然地以流媒体方式进行表示和处理。Kafka日志是流数据的核心存储抽象,允许进入您的离线数据仓库的相同数据现在可以用于流处理。其他一切都是在日志上的一个流化的物化视图,它是各种数据库、搜索索引,或者是公司的其他数据服务系统。创建这些派生视图所需的所有数据和ETL,现在都可以使用KSQL以流媒体方式完成。监控、安全、异常和威胁检测、分析和对故障的响应都可以实时进行,而当时间太晚了。所有这些都可以通过一个简单而又熟悉的SQL接口来使用所有Kafka的数据:KSQL。
KSQL的下一步是什么?
我们正在发布KSQL作为开发者预览,开始构建社区,收集反馈。我们计划在开源社区工作时增加更多的功能,将其从质量,稳定性和KSQL的可操作性转变为生产就绪系统,以支持更丰富的SQL语法,包括进一步的聚合功能和时间点SELECT在连续的表上 - 即,为了能够快速查找到目前为止所计算的内容,以及连续计算流结果的当前功能。






