盘口数据频繁变化,100W用户如何实时通知?

并没有做过相关的业务,结合自己的架构经验,说说自己的思路和想法,希望对大家有启示。
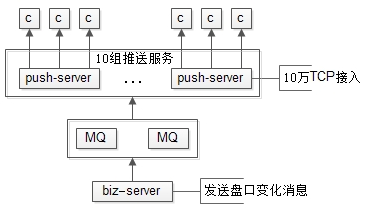
搭建专门的推送集群,维护与客户端的tcp长连接,实时推送
每台推送服务维护10W长连接,10台推送服务即可服务100W用户
推送集群与业务集群之间,通过MQ解耦,推送集群只单纯的推送消息,无任何业务逻辑计算,推送消息的内容,都是业务集群计算好的
如果消息量不大,例如几秒钟一个消息,可以开多线程,例如100个线程,并发推送
如果消息量过大,例如一秒钟几百个消息,可以将消息暂存一秒,批量推送
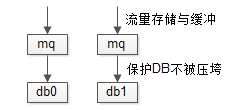
水友已经想到了,可以用 缓存 来降低数据库的压力,但担心“随着时间的推移,这个偏差势必会慢慢放大”。
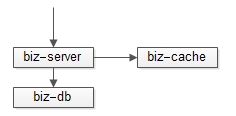
做一个异步的线程,每秒钟访问一次数据库,将复杂的业务逻辑计算出来,放入高可用缓存
所有的读请求不再耦合业务逻辑计算,都直接从高可用缓存读结果
长连接比短连接性能好很多倍
推送量巨大时,推送集群需要与业务集群解耦
推送量巨大时,并发推送与批量推送是一个常见的优化手段
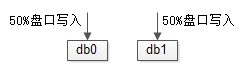
写入量巨大时,水平切分能够扩容,MQ缓冲可以保护数据库
业务复杂,读取量巨大时,加入缓存,定时计算,能够极大降低数据库压力

《用DB自增键生成uid了,还能分库吗?》
《几万条群离线消息,如何高效拉取?》
讨论:
做过盘口推送的朋友,说说你们的方案,一起学习?
登录查看更多
相关内容
Arxiv
4+阅读 · 2018年5月18日





相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年5月18日