网络压缩最新进展:2019年最新文章概览
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文授权转载自:SIGAI
SIGAI特约作者
卓哥哥
研究方向:计算机视觉
导言
本文对2019年CVPR, ICLR和ICML关于网络压缩方向的论文做了快速浏览和简单的笔记。简要介绍,算是抛砖引玉,对于想钻得更深的朋友,恐怕还得靠把论文下下来再仔细品读一番才行。从总结的论文看,网络剪枝、量化和网络结构搜索方法占据主流,并且越来越趋向直接用模型在硬件上的运行效率作为模型设计的重要考量指标。对于这三大顶会,CVPR偏向于实际的应用,而其余二者则更加偏向理论研究。
CVPR 2019
1. Exploiting Kernel Sparsity and Entropy for Interpretable CNN Compression [1]
机构:厦门大学,深圳鹏城实验室,北航,华为诺亚方舟实验室,布法罗大学以及上海腾讯优图 (大佬云集)
笔记:
1. 本文通过实验得出网络结构中特征图的重要性依赖于其稀疏程度和信息丰富性,从而提出一种基于核稀疏性和信息熵的剪枝方法来判断特征图的重要性并对网络进行相应的剪枝。
2. 由于提出的方法可以在只给出2D核的情况下计算特征图的稀疏性和信息熵,并不需要以往数据驱动的方法对特征图进行评估(所以类似于无监督学习,通过2D核本身就可以进行重要性推导),因此网络中所有层可以并行处理。
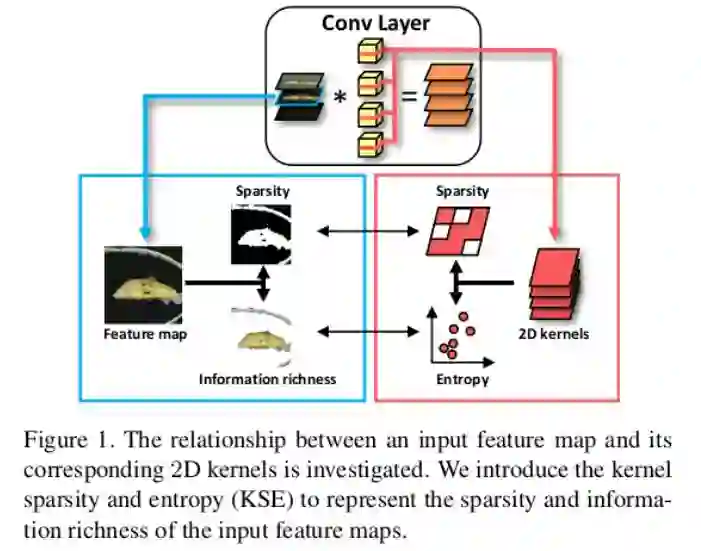
3.在此基础上,提出一种核聚类的方法取代以往的普通核剪枝方法,提高了压缩率。
结果:对于ResNet-50,4.7x FLOPs, 2.9x Size,ImageNet上Top-5准确率减少0.35%作为牺牲。
2.Towards Optimal Structured CNN Pruning via Generative Adversarial Learning [2]
机构:厦门大学,北航,上海腾讯优图,布法罗大学(和上面是同一个团队)
笔记:
1.本文厉害之处是采用生成对抗网络(GAN)来指导剪枝。如下图,其中,生成器用来对网络剪枝,判别器用来判断得到的输出是来自于生成器生成的剪枝网络还是剪枝前的原始网络,从而促使生成器生成更强大的网络,以便下次让判别器判别不出来。循环往复,这样的话,当判别器很难进行判断的时候,生成器基本就训练完成,从而得到对应的剪枝网络。
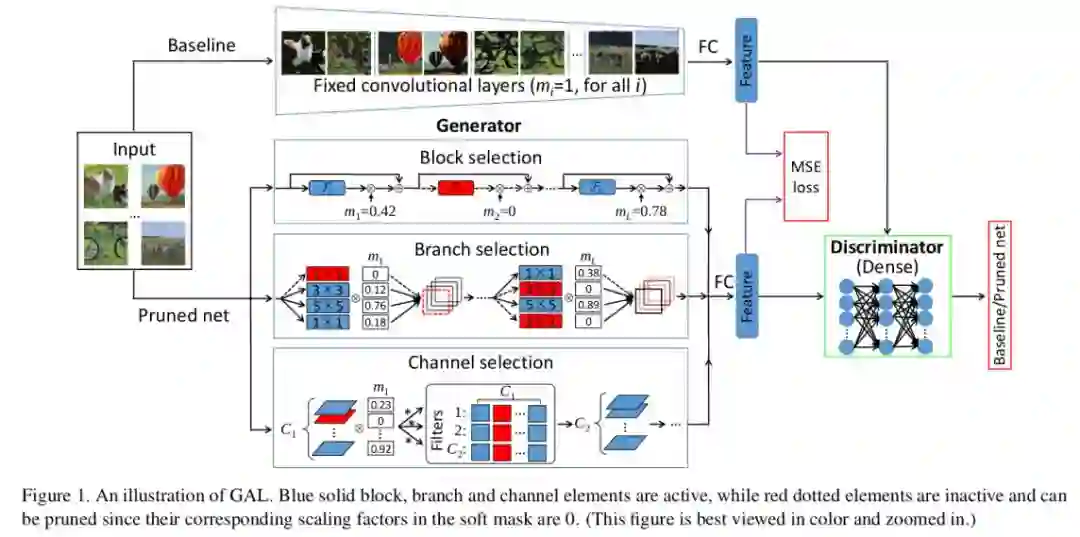
2.对于生成器来说,需要用到一种软掩膜(soft mask)的方式对剪枝过程进行数学建模;对于判别器来说,判断指标为基于L1正则化的目标函数。
3.由于上述过程并不需要用到样本的标注信息,因此是一种无监督剪枝方法。
结果:RestNet-50, 3.7x speedup, 3.75%的Top-5准确度损失。所以相对来说,没有上面第一种效果好。
3.RePr: Improved Training of Convolutional Filters [3]
机构:布兰戴斯大学,微软研究院
笔记:
1. 卷积神经网络剪枝的理论基础是剪枝前的原始网络有信息冗余,从而把冗余的那部分剪掉,达到减小模型大小的目的,同时又要尽量保证模型的性能不受影响。本文发现,不管网络多大多小,甚至对于那些本来就参数很少的网络(under-parameterized networks),他们都会偏向于计算出一些冗余信息。所以说,网络中的冗余卷积核的存在并不单单是因为网络的过参数化(over-parameterized)导致,其中也是因为网络缺少有效的训练。
2. 依据第一点的基础,本文提出了一种有效的网络训练方法:首先完整地训练模型,当训练一段时间后把一部分卷积核给去掉,接着训练其他的部分;再训练一段时间,又把之前去掉的卷积核放回来并重新赋初值,又继续完整地训练整个模型。这样不断往复,最后模型的效果要比从头至尾就完整地训练要好。见下图(右边在测试集上的准确率)。
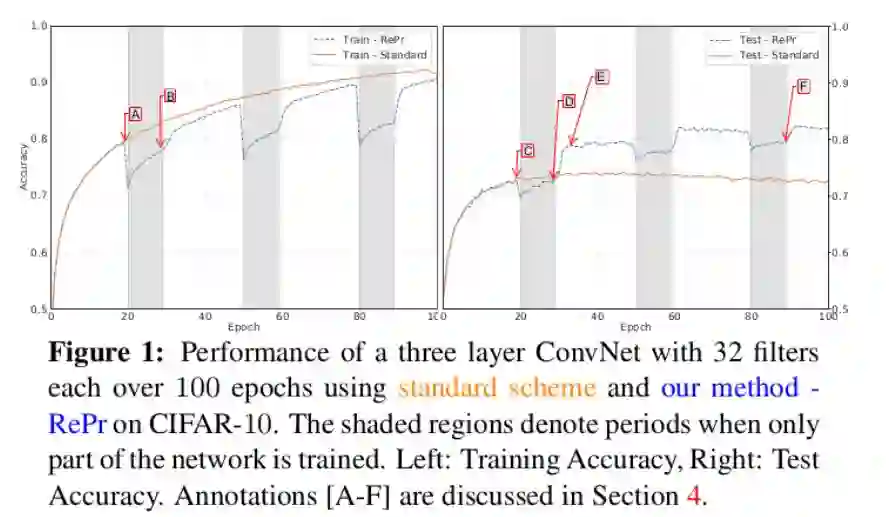
3. 因此,本文也提出了一种卷积核选择指标来筛选出那些没用的卷积核并在中途把它们去掉再重新赋值。
4. 个人感觉,这就有点像之前的Dropout,同样是给网络的训练过程引入一定的正则成分,来提高网络的泛化性能。但我的疑问是,为啥这种“淘汰+再引入”的方式能够帮助网络更好地训练呢?我们可以把这个过程来想象一下:首先,淘汰部分的再引入可以看成是对剩下的精华部分构成的子网络的Capacity的一种扩大;另一方面,通过对那些没用的卷积核采取这种淘汰加再引入的机制,可以给它们一个新的机会让它们变得有用起来。就像在选秀节目中,队员们为了返场,会比之前更加努力,加入之后甚至超过之前没有被淘汰的选手。而这里也是在那些淘汰的卷积核重新赋值的时候会和整个网络正交来保证最小化网络的冗余,使它们能更好地发挥作用。
4.Fully Learnable Group Convolution for Acceleration of Deep Neural Networks [4] (FLGC)
机构:中科院旗下
笔记:
1. 本文的介绍部分写得相当精彩,对网络压缩(从量化,剪枝,紧性模型设计,稀疏表达和数据蒸馏等)做了一个非常好的概述和总结。非常值得一读。稍微有点不协调的是介绍的绝大部分内容跟后面提出的方法好像没有太大的关系。
2. 后面的算法部分重点提出了一种新的组卷积(group convolution)策略,可以看成是ShuffleNet的升级。与ShuffleNet的不同之处在于,在ShuffleNet中,输入通道是固定的,而与输入通道相连的卷积核是不固定的。但是在本文算法中,输入通道和卷积核都不是固定的。啥意思?结合下图,也就是说,对于任意一个输入通道,我连接哪个卷积核都可以,并且对于任意一个卷积核,我也可以连上不同数量的输入通道。
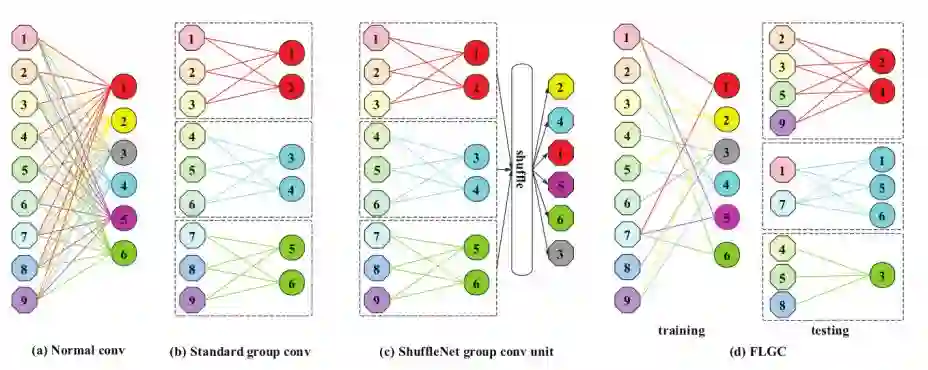
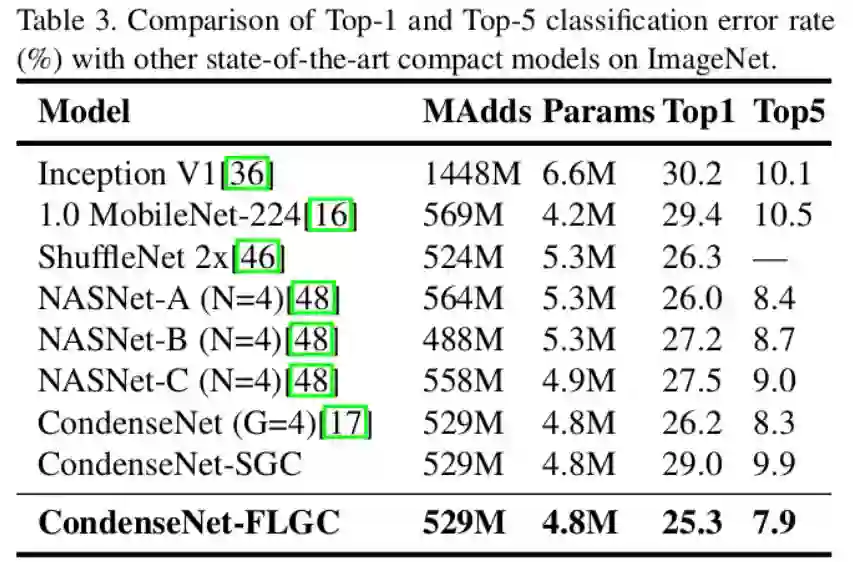
结果:(下图为在ImageNet上的Top-1, Top-5实验结果)
5.A Main/Subsidiary Network Framework for Simplifing Binary Networks [5]
机构:浙江大学,哈佛大学,加州大学圣地亚哥分校,中国电子科技大学
笔记:
1. 论文证明了即使是二值化的网络,同样存在结构冗余。这一点很重要,因为一般的剪枝都是在高精度浮点型网络上剪枝的。
2. 所以说,本文就是直接去对二值化网络进行剪枝。
结果:对于二值化的ResNet-18,通过剪枝后只保留了原来78.6%的卷积核,在ImageNet上,取得了比剪枝前更好的效果。错误率从50.02%降到49.87%。
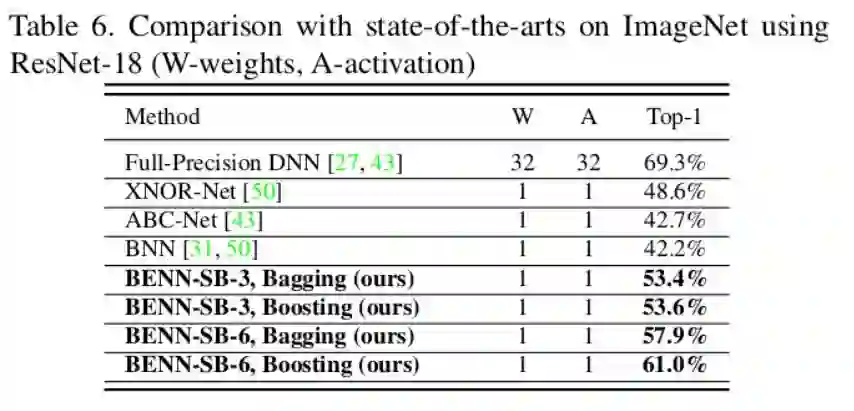
6.Binary Ensemble Neural Network: More Bits per Network or More Networks per Bit? [6]
机构:加州大学圣地亚哥分校,哈佛大学 (和上面又是同一批人)
笔记:
1. 本文的一个亮点是通过一系列的实验,分析了二值网络的表达能力,稳定性和鲁棒性等,并探究了当网络参数二值化后,尤其是如果进一步对激活值二值化,整个网络为什么会有严重的性能下降。他们认为这种性能下降是不能单独从改善网络优化算法入手来解决的。
2. 进一步,他们发现了二值化网络造成高错误率的重要原因是内在不稳定性(Intrinsic Instability)和非鲁棒性(Non-robustness)。所以说,他们采取了一种集成学习的方式来增强二值化网络的性能。
3. 通过集成学习,得到的模型更加的快速和鲁棒,有时甚至比全精度浮点型网络还要好(只是有时,在下图没有反映出来)。
结果:
7.ESPNet v2: A light-weight, Power Efficient, and General Purpose Convolutional Neural Network[7]
机构:华盛顿大学,Allen Institute for AI, XNOR.AI
笔记:
简单一句话:基于ESPNet [8],采用Group point-wise and depth-wise dilated separable convolutions,青出于蓝而胜于蓝。
8.Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration [9] (FPGM)
机构:悉尼科技大学,京东,CETC,华为,百度研究院 (大佬荟萃,巨头云集)
笔记:
1. 之前的基于范数(norm-based)的剪枝指标有两个方面的要求:卷积核的范数要有很大的方差;最小的卷积核范数要小。这两个方面限制了剪枝算法的性能。
2. 本文提出的FPGM算法能有效地避开这两个要求,去剪掉那些可以替代的带有冗余信息的卷积核。
3. 理论可以参考[10]。
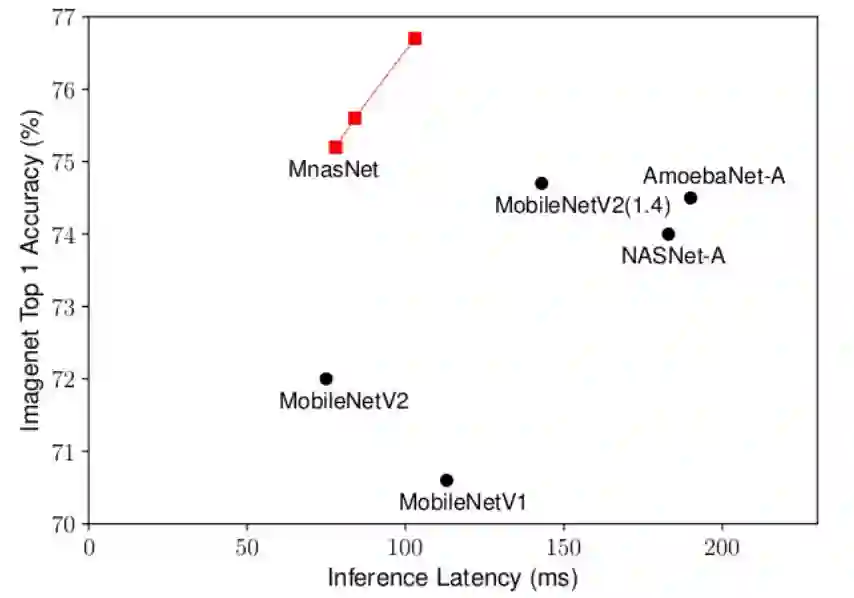
9.MnasNet: Platform-Aware Neural Architecture Search for Mobile [11]
机构:谷歌
笔记:
1. 用网络搜索的方式寻找高效高性能的卷积神经网络
2. 摆脱以往的采用FLOP来评价网络速度的方式(因为这些方式往往不太准确),直接把网络放在硬件(如移动设备)上测试,并把反馈回来的运行速度作为网络的评价指标。
3. 实现了两大权衡:
3.1. 准确度和运行效率的权衡:通过采取一种多任务的方式,在构造损失函数时,同时考虑准确率和从硬件上反馈回来的运行时间。
3.2. 网络搜索空间和网络多样性的权衡:提出了一种层级搜索空间。具体来说,网络由多个块堆砌而成,块与块的内部结构可以不一样(比如包含多少层,每个层是什么),但每个块里面的层需要一致,比如都采取3x3的卷积核。
结果:(ImageNet)
10.HAQ: Hardware-Aware Automated Quantization with Mixed Precision [12]
机构:麻省理工 (韩松团队)
笔记:
1. 传统的模型量化算法将网络的所有层量化到固定的比特数。但是由于不同层包含有不同程度的冗余信息,以及不同层之间的计算属性(比如不同上限的计算能力和内存),这种方式并不是最优的量化方式。随着现在越来越多的硬件支持混合比特数的运算(比如苹果的A12 Bionic芯片,英伟达近期推出的图灵GPU等),所以采取不同层设定不同比特数的量化方法很有必要。
2. 由于每一层的权重和激活值量化的策略不同(量化的策略是指量化到几个比特数),因此量化一个模型存在无数种策略组合。因此,本文通过借助强化学习来决定具体的策略,并且同上文讲到的MnasNet类似,直接用网络在具体硬件上反馈的的运行速度、能量消耗和占据的内存空间等作为衡量指标融入到算法当中。这样,就避免了以往的代理指标,比如FLOP和模型大小等,而是直接针对具体硬件和在该硬件上的运行速度,从而产生出更好更实际的结果。
结果:和固定8-bit的量化模型比较,运行速度:1.4~1.95x, 能量消耗:1.9x,准确率损失可忽略不计(negligible)。
ICLR 2019
1.The lottery ticket hypothesis: finding sparse, trainable neural networks [13]
机构:麻省理工 (CSAIL)
笔记:
提出一种彩票理论,认为原始网络中存在某些子网络(中奖网络),直接训练这些子网络可以达到和原始网络同样的性能。这篇文章很厚,内容很多,还得仔细赏析一番。
2.An empirical study of binary Neural Networks’ optimization [14]
机构:牛津大学
笔记:
1. 以往的方法训练一个二值网络时,往往采取某种近似的方法(比如Straight-Through-Estimator,简称STE)来计算梯度。但这种方法往往不太能站住脚,因为前向梯度传播和后向参数更新并不能对应。
2. 本文通过实验分析了二值网络优化过程中的种种技巧,比如STE,优化器等,从而得到为未来二值网络更好地进行优化的指导意见。
3.Rethinking the value of Network pruning [15]
机构:加州大学伯克利分校,清华大学
笔记:
1. 一个字:此文很牛。基本上是对以往所有结构性剪枝方法的一个颠覆。所谓结构性剪枝,就是以卷积核/层级别的粗粒度剪枝,而不是只剪去卷积核中的某些参数(这个叫非结构性剪枝或细粒度剪枝)。以往的结构性剪枝,分为三步走:训练(training)à剪枝(pruning)à微调(fine-tuning),但是这种方法似乎缺乏必要的理论依据。
2. 那到底为什么缺乏理论依据?以往的方法认为一个拥有更少参数的模型如果从头训练(train from scratch),是不能达到通过以上三步走得到的拥有同等参数数量的模型的效果的。而这篇文章证明了:能。为什么会和以往的结论矛盾呢?原因来自于在从头训练时,对模型的超参数设置不恰当,数据增强不恰当,以及赋予不公平的计算资源的预算。
3. 那么以往的结构性剪枝方法就没用了?不,以往的方法其实更重要的是在做类似于网络搜索的工作,通过剪枝来寻找出潜在的子网络来。而这恰恰就是下面麻省理工这篇ProxylessNAS的思想之一。
4.ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware [16]
机构:麻省理工 (韩松团队)
笔记:
1. 首先,什么是Proxy-base NAS? 中文可以翻译成基于代理的网络结构搜索。这种方式往往基于一些代理任务,比如在一个比目标数据集相对小的数据集上搜索,或者构建更少的网络块,或者只用少量的迭代次数。
2. 那之前的网络搜索为什么要基于代理?因为如果不那样的话,会带来完全承受不住的计算量,需要无数的计算资源。因为搜索空间如此之大,每次衡量一个网络都要跑一个特别大的数据集,那么基本上就废了。
3. 虽然如此,基于代理的方式却无法保证找到了最优解。
4. 那么如何构造一个不基于代理的有效的方法呢?也就是说我直接在目标任务和目标硬件上搜索而又能高效准确 (见下图)。解决办法如下:

4.1 为了减少GPU时间,本文首先直接构造了一个超级无敌大的网络,它包含了所有可能的路径,然后通过剪枝的方式进行搜索(有没有和上文的思想如出一辙?)。
4.2 为了减少GPU内存消耗,作者将网络的所有参数进行了二值化,然后用一种近似方法来进行梯度计算与传播(基于BinaryConnect [17])。
4.3 由于在硬件上直接跑得到的如运行速度的反馈是不可微的,所以本文的另一个贡献是构造了一个针对硬件反馈的可微目标函数作为网络损失函数的一部分。
结果:With only 200 GPU hours, got same top-1 accuracy as MobileNet v2 1.4, while 1.8x faster.
从这里就渐渐看出趋势了:直接利用硬件的反馈来指导网络压缩。但是文章中有个问题,基于代理的方式不能找到最优解,那么采取BinaryConnect的方式做梯度运算去训练二值网络就能找到最优解了?毕竟这种梯度运算也是一种近似方式。
5.Defensive Quantization: When Efficiency meets Robustness [18]
机构:麻省理工 (韩松团队)
笔记:
1. 作者观察到量化的模型往往易受一些轻微干扰的攻击,比如改变输入图片一点点,就能让量化网络得到截然不同的结果。
2. 以上的观察有点反意识(counter-intuitive),也就是说量化本来应该可以在某些程度上抵制噪音的(这里让我想起了LBP算子),因为通过量化,可以把原来浮点数中存在的噪音给去掉。但是为什么实际的量化网络中却不这样呢?原因来自于噪音在深度网络的传播过程中,可能会被放大。
3. 为什么会放大?因为当噪音比较小时,其实是可以通过量化消除的,但是一旦某些噪音超过了一定阈值,那么这些噪音非但不会消除,反而会随着网络的深入一直往后传递下去,变得越来越大。基于此,本文提出了防御型量化策略,来控制Lipschitz常数,从而让噪音在网络传递的过程中一直保持较小的值,最后达到抵御干扰的效果。
4. 本文中提出的防御型量化策略也能让量化的优化过程变得更加容易,值得借鉴。
ICML 2019
1.Collaborative Channel Pruning for Deep Networks [19]
机构:腾讯AI实验室,中科院,University of Texas at Arlington
笔记:
1. 非常不幸,本文提出的方式恰好是上面说的三步走的方式~
2. 通过对通道内部之间关系的研究来指导剪枝过程。
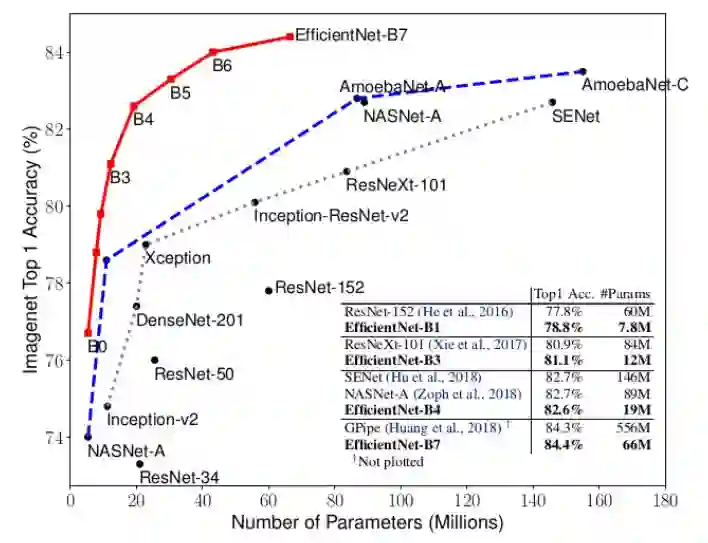
2. EfficientNet: Rethinking Model Scaling for Convolutional Neural Network[20]
机构:Google Research, Brain Team, Mountain View, CA
笔记:
1. 为了改变模型性能,通常在三个维度上做变换:网络深度,网络宽度(即每一层中卷积核的数量)和输入图像分辨率。以往的方法通常只是对其中一种做变换,而作者认为需要同时做变换。可以这样来解释:当输入图像分辨率变大时,我们需要更多的网络层来增加感受野,同样需要更多的卷积核和通道来捕捉更多细粒度的特征。
2. 本文的方式是结合网络搜索和上述变换,得到最终的EfficientNet。其结果完爆state-of-art。见下图:
Others in 2019
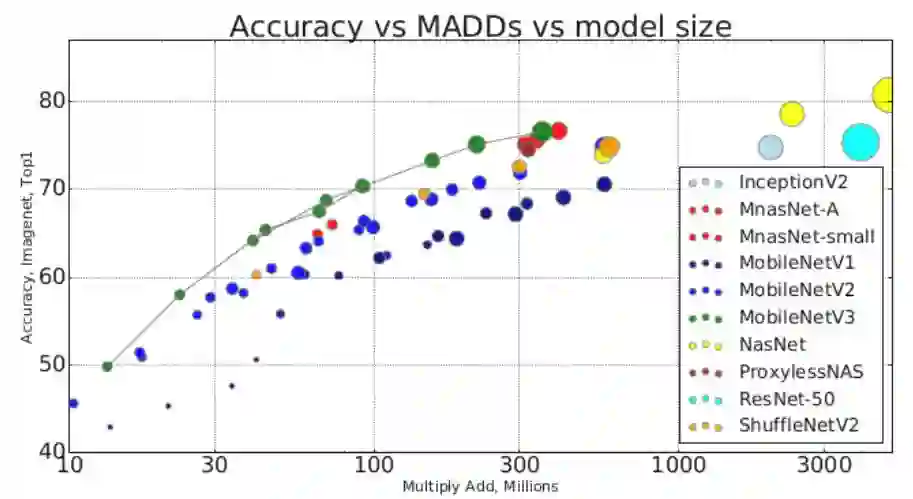
Searching for MobileNetV3 [21]
机构:Google AI, Google Brain
笔记:
简单来说,结合网络搜索和网络设计(比如加入组卷积等高效单元)来生成高效网络。
结果:
总结
目前2019年的模型就讲到这里,我想应该还有很多相关的论文没有涉及到,这点以后再补充。后面会有对其中某些方法更为精细的品读。网络压缩发展的步伐确实快得不得了,而且对于普通高校来说,硬件资源确实是一大硬伤,比如文中某些方法直接将移动硬件的反馈融入到训练过程,又比如网络搜索需要的各种GPU。但是总的来说,重点还是要提出新颖且高效的算法。
另外,欢迎访问我的个人博客:https://zhuogege1943.com
参考文献:
[1] Li, Yuchao, et al. “Exploiting Kernel Sparsity and Entropy for Interpretable CNN Compression.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[2] Lin, Shaohui, et al. “Towards Optimal Structured CNN Pruning via Generative Adversarial Learning.” arXiv preprint arXiv:1903.09291 (2019).
[3] Prakash, Aaditya, et al. “RePr: Improved Training of Convolutional Filters.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[4] Wang, Xijun, et al. “Fully Learnable Group Convolution for Acceleration of Deep Neural Networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[5] Xu, Yinghao, et al. “A Main/Subsidiary Network Framework for Simplifying Binary Neural Networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[6] Zhu, Shilin, Xin Dong, and Hao Su. “Binary Ensemble Neural Network: More Bits per Network or More Networks per Bit?.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[7] Mehta, Sachin, et al. “ESPNetv2: A Light-weight, Power Efficient, and General Purpose Convolutional Neural Network.” arXiv preprint arXiv:1811.11431 (2018).
[8] Watanabe, Shinji, et al. “Espnet: End-to-end speech processing toolkit.” arXiv preprint arXiv:1804.00015 (2018).
[9] He, Yang, et al. “Filter pruning via geometric median for deep convolutional neural networks acceleration.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[10] Ye, Jianbo, et al. “Rethinking the smaller-norm-less-informative assumption in channel pruning of convolution layers.” arXiv preprint arXiv:1802.00124 (2018).
[11] Tan, Mingxing, et al. “Mnasnet: Platform-aware neural architecture search for mobile.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[12] Wang, Kuan, et al. “HAQ: Hardware-Aware Automated Quantization with Mixed Precision.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[13] Frankle, Jonathan, and Michael Carbin. “The lottery ticket hypothesis: Finding sparse, trainable neural networks.” arXiv preprint arXiv:1803.03635 (2018).
[14] Milad Alizadeh and Javier Fernández-Marqués and Nicholas D. Lane and Yarin Gal. “An empirical study of binary Neural Networks’ optimization.” ICLR. 2019.
[15] Liu, Zhuang, et al. “Rethinking the value of network pruning.” ICLR. (2019).
[16] Cai, Han, Ligeng Zhu, and Song Han. “ProxylessNAS: Direct neural architecture search on target task and hardware.” arXiv preprint arXiv:1812.00332 (2018).
[17] Courbariaux, Matthieu, Yoshua Bengio, and Jean-Pierre David. “Binaryconnect: Training deep neural networks with binary weights during propagations.” Advances in neural information processing systems. 2015.
[18] Lin, Ji, Chuang Gan, and Song Han. “Defensive quantization: When efficiency meets robustness.” arXiv preprint arXiv:1904.08444 (2019).
[19] Hanyu Peng, Jiaxiang Wu, Shifeng Chen, Junzhou Huang ; Proceedings of the 36th International Conference on Machine Learning, PMLR 97:5113-5122, 2019.
[20] Mingxing Tan, Quoc Le ; Proceedings of the 36th International Conference on Machine Learning, PMLR 97:6105-6114, 2019.
[21] Howard, Andrew, et al. “Searching for mobilenetv3.” arXiv preprint arXiv:1905.02244 (2019).
CVer-模型剪枝&压缩群
扫码添加CVer助手,可申请加入CVer-剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如模型压缩+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!


