【结巴分词】浅谈结巴分词算法原理
作者:小占同学
前言
本文详细阐述了结巴分词的分词原理,主要包括分词的具体过程和对未登录词的分词。本文主要参考https://blog.csdn.net/rav009/article/details/12196623中的内容,感谢原作者!
本文如有不正确的地方,恳请各位读者指出。
结巴分词算法原理
-
基于 前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的 有向无环图 (DAG) -
采用了动态规划查找 最大概率路径, 找出基于词频的最大切分组合 -
对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
下面逐条来解释。
一、基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
结巴分词自带了一个叫做dict.txt的词典,里面有349046条词,其每行包含了词条、词条出现的次数(这个次数是于作者自己基于人民日报语料等资源训练得出来的)和词性,如下图所示。

在基于词典的中文分词方法中,词典匹配算法是基础。为了保证切分速度,需要选择一个好的查找词典算法。这里介绍词典的Tre树组织结构。基于前缀词典实现的词图扫描,就是把这34万多条词语,放到一个trie树的数据结构中,trie树也叫前缀树或字典树,也就是说一个词语的前面几个字一样,就表示他们具有相同的前缀,就可以使用trie树来存储,具有查找速度快的优势。一个搜索数字的trie树的一个节点只保留一个字符。如果一个单词比一个字符长,则包含第个字符的节点有指针指向下一个字符的节点,以此类推。这样组成一个层次结构的树,树的第一层包括所有单词的第一个字符,树的第二层包括所有单词的第二个字符,以此类推。很显然,trie树的最大高度是词典中最长单词的长度。
査询的过程对于查询词来说,从前往后一个字符一个字符的匹配。对于trie树来说,是从根节点往下匹配的过程。
一些人可能会想到把dict.txt中所有的词汇全部删掉,然后再试试结巴能不能分词。结果会发现,结巴依然能够分词,不过分出来的词,大部分的长度为2。这个就是第三条的任务,基于HMM来预测分词了,我们得会儿再说。
DAG有向无环图,就是后一句中的生成句子中汉字所有可能成词情况所构成的有向无环图,这个是说,给定一个待分词的句子,将它的所有词匹配出来,构成词图,即是一个有向无环图DAG,如下图所示:
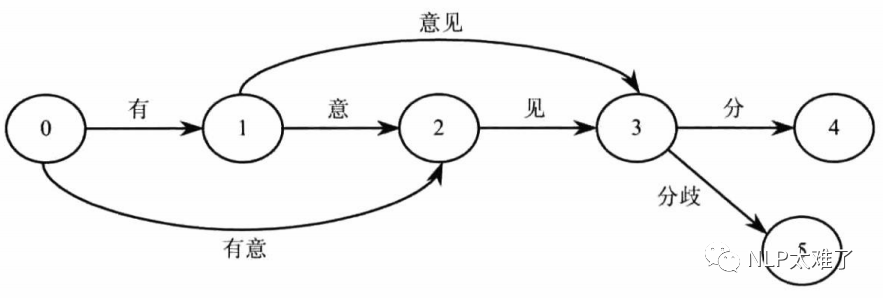
那么具体是怎么做的呢?分为两步:1. 根据dict.txt词典生成trie树;2. 对待分词句子,根据trie树,生成DAG。实际上,通俗的说,就是对待分词句子,根据给定的词典进行查词典操作,生成几种可能的句子切分,形成类似上图所示的DAG图。
对于DAG的实现,在源码中,作者记录的是句子中某个词的开始位置,从0到n-1(n为句子的长度),设置一个python的字典,每个开始位置作为字典的键,value是个python的list,其中保存了可能的词语的结束位置(通过查字典得到词,然后将词的开始位置加上词语的长度得到结束位置)。例如:{0:[1,2,3]}这样一个简单的DAG,就是表示0位置开始,在1,2,3位置都是某个词的结束位置,就是说0 ~ 1, 0 ~ 2,0 ~ 3这三个位置范围之间的字符,在dict.txt中都是词语。
二、采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
作者的代码中将字典在生成trie树的同时,也把每个词的出现次数转换为了频率。频率其实也是一个0~1之间的小数,是事件出现的次数/实验中的总次数,因此在试验次数足够大的情况下,频率约等于概率,或者说频率的极限就是概率。
动态规划中,先查找待分词句子中已经切分好的词语,对该词语查找该词语出现的频率(次数/总数),如果没有该词(既然是基于词典查找,应该是有可能没有该词),就把词典中出现频率最小的那个词语的频率作为该词的频率。也就是说,P(某词语)=FREQ.get(‘某词语’, min_freq), 然后根据动态规划查找最大概率路径。对句子从右往左反向计算最大概率(也可以是从左往右,这里反向是因为汉语句子的重心经常落在后面,就是落在右边,主要是因为在通常情况下形容词太多,后面的才是主干,因此,从右往左计算,正确率要高于从左往右计算,类似于逆向最大匹配的分词方法),P(NodeN)=1.0, P(NodeN-1)=P(NodeN)*Max(P(倒数第一个词)),依次类推,最后得到最大概率路径,即得到最大概率的切分组合。
三、对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
未登录词(Out Of Vocabulary word, OOV word),在这里指词典dict.txt中没有记录的词。上面说了,把dict.txt中的所有词语都删除了,结巴分词一样可以分词,就是说的这个。怎么做到的? 这个就基于作者采用的HMM模型了,中文词汇按照BEMS四个状态来标记,B是开始begin位置,E是是结束end位置,M是中间middle位置,S是single,单独成词的位置。也就是说,他采用了状态为(B,E,M,S)这四种状态来标记中文词语,比如北京可以标注为 BE, 即北/B京/E,表示北是开始位置,京是结束位置。中华民族可以标注为BMME,就是开始,中间,中间,结束。
经过作者对大量语料的训练,得到了finalseg目录下的三个文件(来自结巴项目的issues(https://github.com/fxsjy/jieba/issues/7#issuecomment-9692518)):
要统计的主要有三个概率表:
1)位置转换概率,即B(开头),M(中间),E(结尾),S(独立成词) 四种状态的转移概率,该表存放于prob_trans.py中,下面为表中内容;
{'B': {'E': 0.8518218565181658, 'M': 0.14817814348183422},
'E': {'B': 0.5544853051164425, 'S': 0.44551469488355755},
'M': {'E': 0.7164487459986911, 'M': 0.2835512540013088},
'S': {'B': 0.48617017333894563, 'S': 0.5138298266610544}}
例如,P(E|B) = 0.851, P(M|B) = 0.149,说明当我们处于一个词的开头时,下一个字是结尾的概率。要远高于下一个字是中间字的概率,符合我们的直觉,因为二个字的词比多个字的词更常见。
2)位置到单字的发射概率,比如P("和"|M)表示一个词的中间出现"和"这个字的概率,该表存放于prob_emit.py中;
3)词语以某种状态开头的概率,其实只有两种,要么是B,要么是S,该表存放于prob_start.py。这个就是起始向量,就是HMM系统的最初模型状态
实际上,BEMS之间的转换有点类似于2元模型,就是2个词之间的转移。二元模型考虑一个单词后出现另外一个单词的概率,是N元模型中的一种。例如:一般来说,中国之后出现北京的概率大于中国之后出现北海的概率,也就是:中国北京比中国北海出现的概率大些,更有可能是一个中文词语。
将一个给定的待分词的句子视为一个观察序列,对HMM(BEMS)四种状态的模型来说,就是为了找到一个最佳的BEMS隐状态序列,这个就需要使用Viterbi算法来得到这个最佳的隐藏状态序列。通过提前训练好的HMM转移概率、发射概率,使用基于动态规划的viterbi算法的方法,就可以找到一个使概率最大的BEMS序列。按照B打头,E结尾的方式,对待分词的句子重新组合,就得到了分词结果。
比如,对待分词的句子全世界都在学中国话得到一个BEMS序列 [S,B,E,S,S,S,B,E,S]这个序列只是举例,不一定正确,通过把连续的BE凑合到一起得到一个词,S为一个单独的词,就得到一个分词结果了:上面的BE位置和句子中单个汉字的位置一一对应,得到全/S 世界/BE 都/S 在/S 学/S 中国/BE 话/S,从而将句子切分为词语。
总结
结巴分词的过程:
-
加载字典, 生成trie树;
-
给定待分词的句子,使用正则获取连续的中文字符和英文字符,切分成短语列表,对每个短语使用DAG(查字典)和动态规划,得到最大概率路径,对DAG中那些没有在字典中查到的字,组合成一个新的片段短语,使用HMM模型进行分词,也就是作者说的识别新词,即识别字典外的新词;
-
使用python的yield语法生成一个词语生成器,逐词语返回。
结巴分词的分词功能的实现,首先是在大语料上人工对其中的词语进行统计其出现的频率,然后对切分的句子形成DAG词图,并使用动态规划的方法找到DAG词图中的最短路径(概率最大),选取该最短路径为切分方法。对于OOV词,使用了HMM,将BEMS视为隐藏状态,待切分句子为观测状态,同样通过一种动态规划的算法来找出是概率最大的路径,该路径即为最佳切分组合。
参考
-
https://github.com/fxsjy/jieba -
对Python中文分词模块结巴分词算法过程的理解和分析( https://blog.csdn.net/rav009/article/details/12196623) -
中文分词的基本原理以及jieba分词的用法( https://blog.csdn.net/John_xyz/article/details/54645527) -
jieba中文分词源码分析(一)( https://blog.csdn.net/daniel_ustc/article/details/48195287) -
结巴分词原理讲解( https://houbb.github.io/2020/01/08/jieba-source-01-overview) -
《解密搜索引擎技术实战 LUCENE & JAVA精华版 第3版》 -
https://zhuanlan.zhihu.com/p/66904318 -
https://zh.wikipedia.org/wiki/Trie






