![]()
![]()
自动诊断是智能医学应用领域的一个重要方向,其多阶段的症状选择询问和疾病诊断推理的难题依旧是目前的巨大挑战。当前大多数工作使用强化学习方法,并将自动诊断视为一个策略优化问题,从而存在学习效率低和 Reward 函数难以确定等问题。
针对以上问题,本期 AI Drive 嘉宾——哈尔滨工业大学深圳智能计算研究中心的李东方、陈俊颖——分享了他们的工作“Diaformer”。
![]()
论文标题:
Diaformer: Automatic Diagnosis via Symptoms Sequence Generation
https://arxiv.org/abs/2112.10433
https://github.com/zxlzr/Diaformer
![]()
该工作将自动诊断形式化为序列生成任务,提出了一个症状注意力生成架构去直接学习症状询问选择和疾病诊断之间的潜在关联,并提出三种无序训练机制来有效减小序列生成的有序性与患者症状本身的无序性偏差;实验结果表明,Diaformer 模型在三个公开自动诊断数据集上都取得了目前最好的结果,并且有着更高的学习效率。
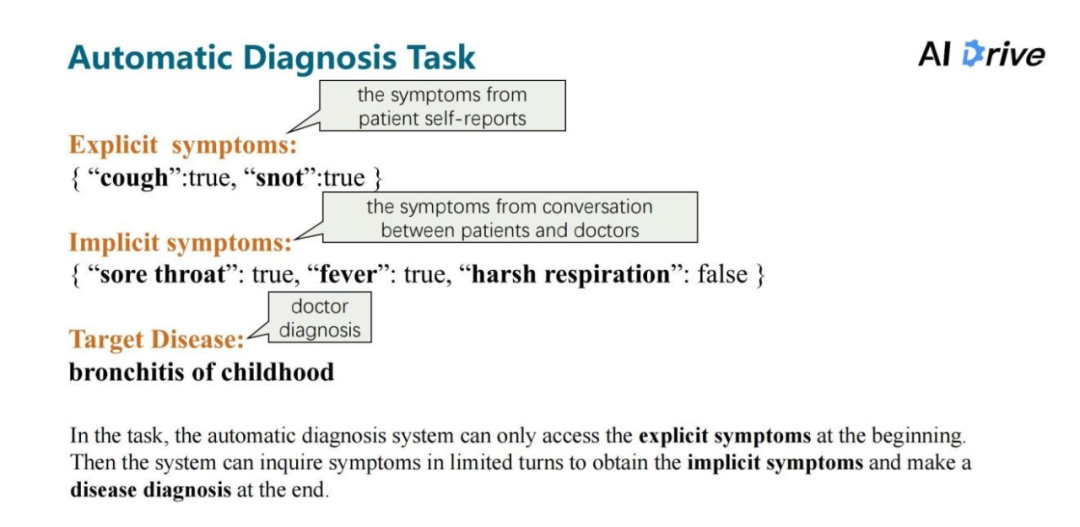
近来,自动诊断引起了研究人员越来越多的关注,因为它能够简化诊断程序、帮助做出更好的诊断决定,甚至具有帮助建立诊断对话系统的潜力。但是自动诊断系统是建立在机器和病人之间的对话上的,所以需要允许机器通过不断询问病人的症状来做出相应诊断。
比如,在上图中,每个数据集会有两个序列症状集合,分别为隐性症状集合和显性症状集合。机器首先获得显性症状集合后,机器会一轮一轮地询问系统是否存在某个隐性症状,机器通过询问隐性症状获得附加的隐性症状的值和已经给到的显性症状,来结合并预测目标的疾病。
这里给定一个严格的定义,使机器和用户互动,在获得用户自我报告的基础上询问用户显性症状以外的其他症状,并且最后给出疾病诊断。当询问额外的症状时,自动诊断系统只能获得隐性症状集合中的症状值,对于其他外部症状(就是不相关的症状),用户回答 not sure 。因此,疾病诊断任务可以被定义为在有限的交互集合和交互回合中来逐步询问隐性症状,然后根据显性症状和所询问的附加症状来诊断疾病。
自动诊断任务也可以应用到以下两种应用中。第一种是 Symptom checking,症状检查工具基于患者给定的症状询问有关的症状,然后尝试诊断一些潜在的疾病,可以用于帮助患者的自我诊断以及用作医生的辅助诊断。
还有第二种应用就是 Dialogue management,就是医患关系的对话系统的对话管理器,用于诊断对话系统的负责症状询问以及疾病诊断的决策模块。
做这个系统的出发点是:由于隐性症状的存在,这个任务可以被视为一个多步骤的推理问题。它的挑战是在于如何捕捉推理过程中的基本动态和不确定性,并且在很少的标记数据和有限的轮毂中来查询准确的症状。
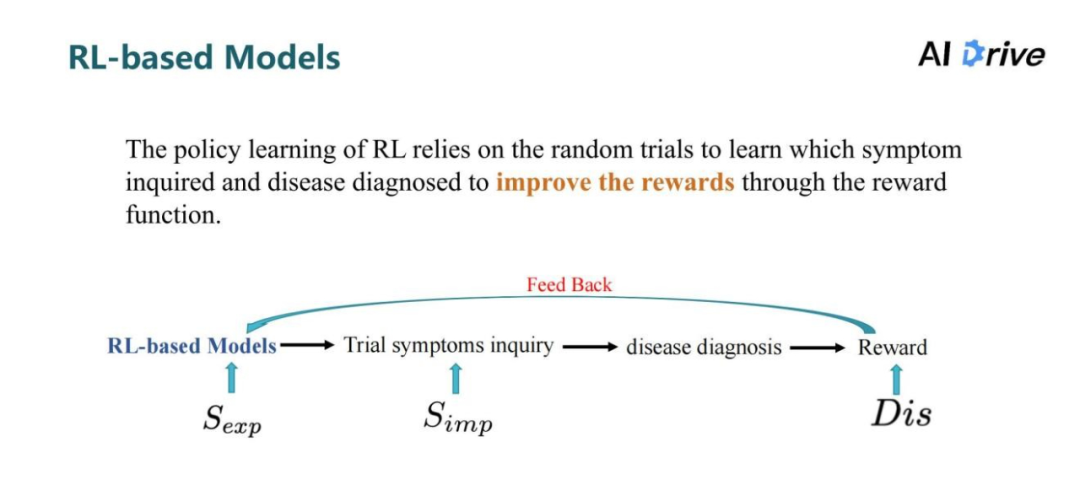
以前的大多数方法通常把这个问题作为一个连续的决策过程来处理(马尔可夫决策过程),并采用强化学习进行策略学习。
但是强化学习如何查询症状,并在最后的准确率的奖励下才会做出这种疾病诊断,这其中存在偏差,也在一定程度上偏离了医生的实际诊断流程。
在真实的诊临床诊断场景中,医生会仔细的询问相关的问题,并用医疗诊断的逻辑来询问病人。这其实是一个序列化的决策过程;但是强化学习的策略主要是试图学习哪种症状询问能提高奖励,而不是直接去学习医生的诊断逻辑。
因此,强化学习是依靠随机的试验去学习如何提高奖励,这只是预测了疾病诊断的相关性。它通过采样序列来学习决策,而不是直接学习症状和标准诊断范式之间的相关性,这就导致了进行症状查询决策的学习效率低下。
此外,目前还没有寻找理想的 Reward 函数的有效方法,导致基于强化学习的方法难以权衡疾病诊断和症状查询之间的决策选择。
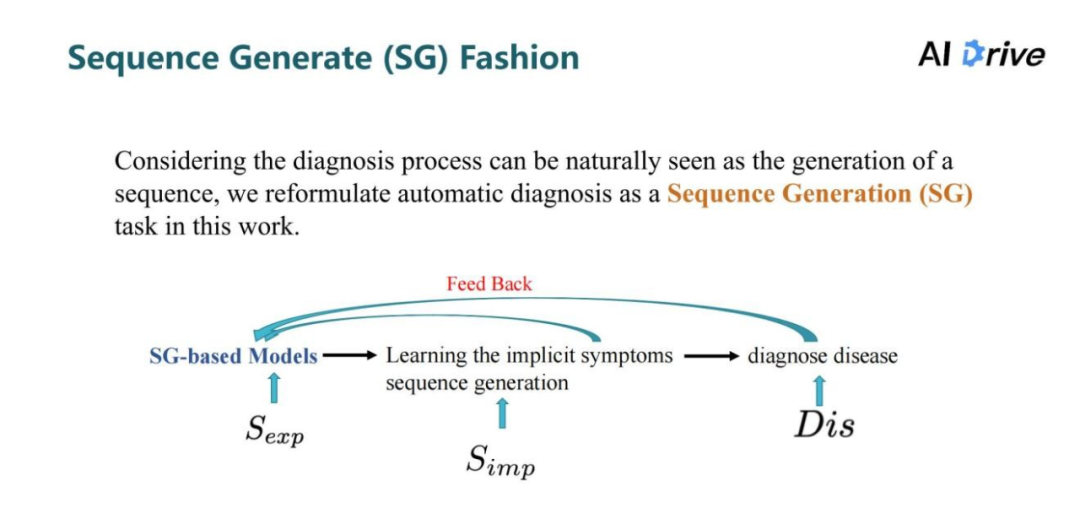
考虑到疾病诊断过程可以自然地被看作是一个序列的生成,在本工作中把自动诊断重新表述为序列生成的任务,与之前的强化学习方法不同,多步骤的查询过程被明确的建模为:生成包含症状和诊断的序列。这可以提高多步骤推理过程的效率和可解释性。
此外,由于以前的显性症状和当前的症状之间的潜在关系可以被学习,对于隐性症状的准确查询,将有助于提高疾病诊断的准确性。当然这与医生的诊断逻辑也是类似的,最终在数据集上的结果也证明这种方法提高了最终任务(预测疾病)的准确率。
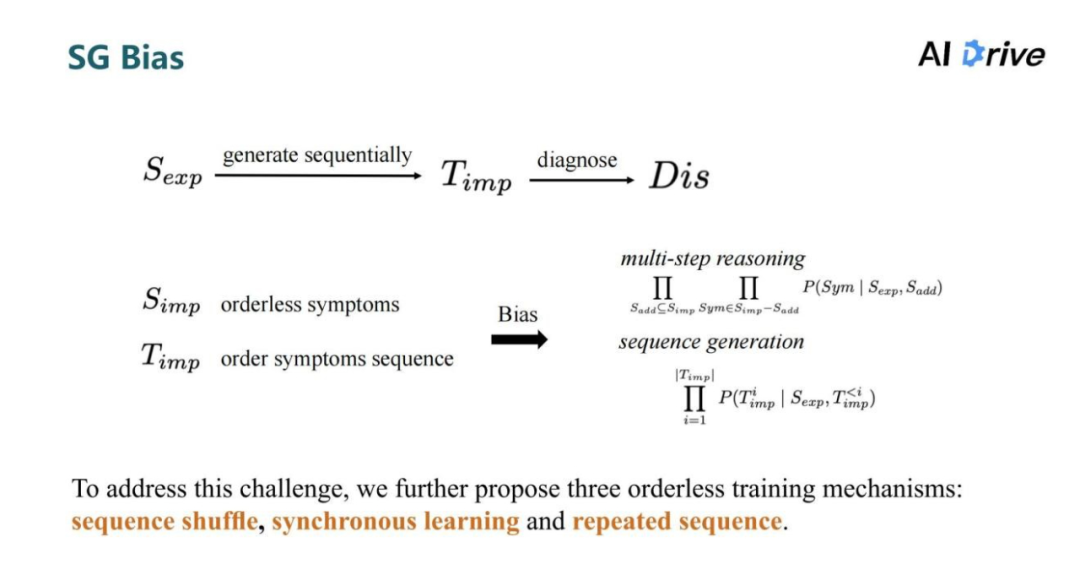
但是,这种学习一个症状序列的方法存在一个问题,它给到的隐性症状它是一个集合,并不存在一个明确被询问的先后顺序。
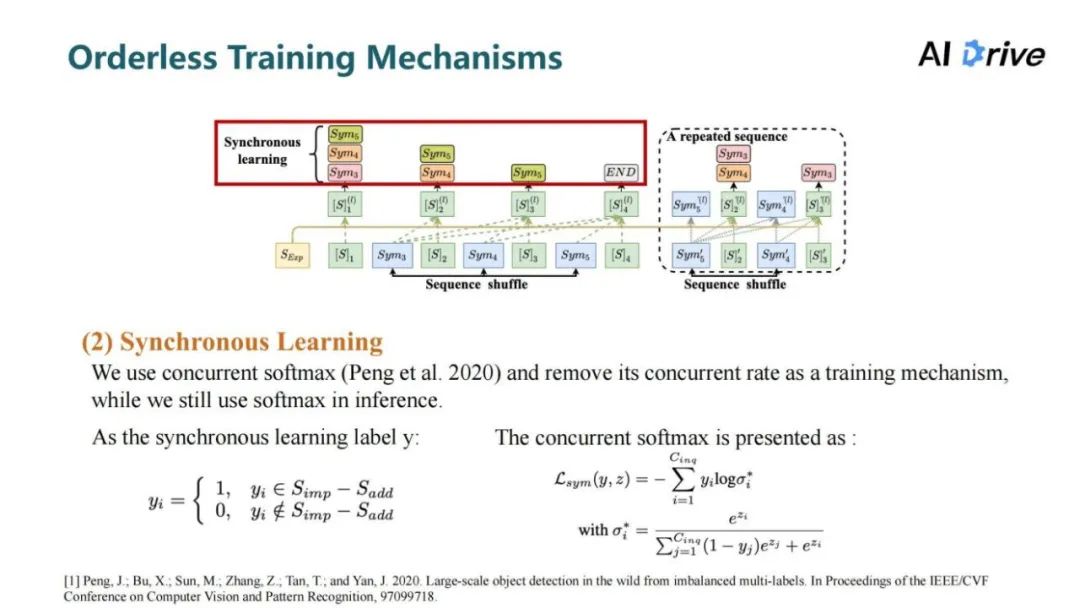
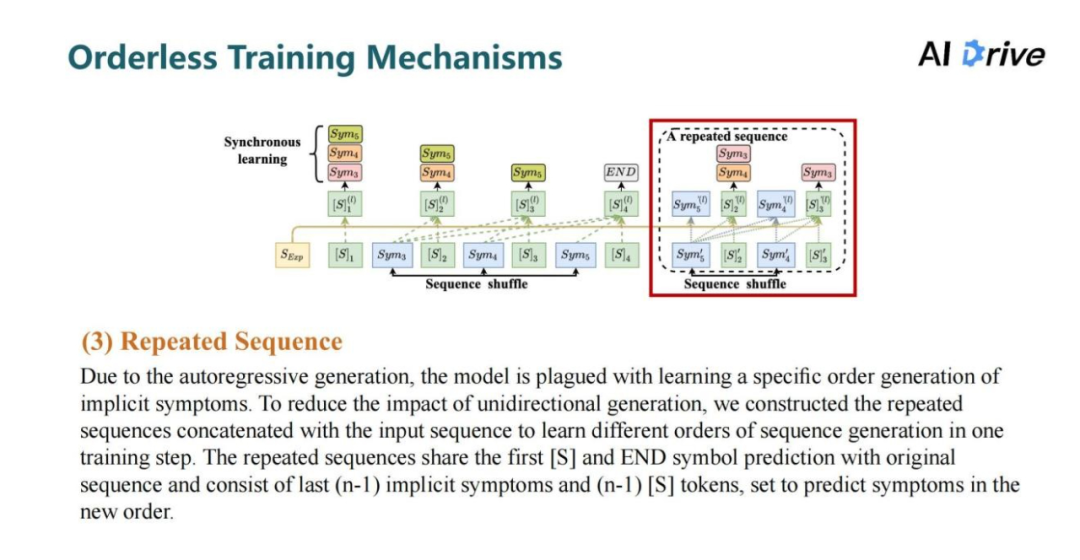
当系统学习序列生成的模型时,会产生偏差,为了解决这一难题,进一步地提出上图这三种无序训练机制。它的主要的思路是鼓励模型以无序,但是准确的方式查询序列,把所有可能的序列进行组合排列,从而提高推理时的泛化性。
上图是本论文的一个贡献点,该论文是首次采用虚症状序列生成的模型做自动诊断的方法,因为之前大部分模型大多采用强化学习的方法,还有一些基于 SVM、基于逻辑回归、基于随机森林的方法,进一步展示了模型,可以在有限的论述中,能比其它基线模型要好。
之后,进一步提出了三种无序训练机制,以此减小序列生成与给定的症状无序性之间的偏差。最后的实验数据表明,这种无序机制很好地缩减了偏差,且模型能够有效提升下游疾病诊断的准确率,同时提高模型的训练效率。
对于疾病查询预测的进一步分析表明,应用疾病症状序列生成是自动诊断任务的一种可行的方法。
根据前面的介绍,模型采用了序列生成的方式来做自动症状,对此我们了提出一个简单但非常有效的模型:Diaformer,它包含了两个部分,第一是症状注意力框架,它采用序列生成的方法实现自动诊断,第二是无序的训练机制,它是用于减小序列生成的有序性和隐性症状本身无序性的偏差。
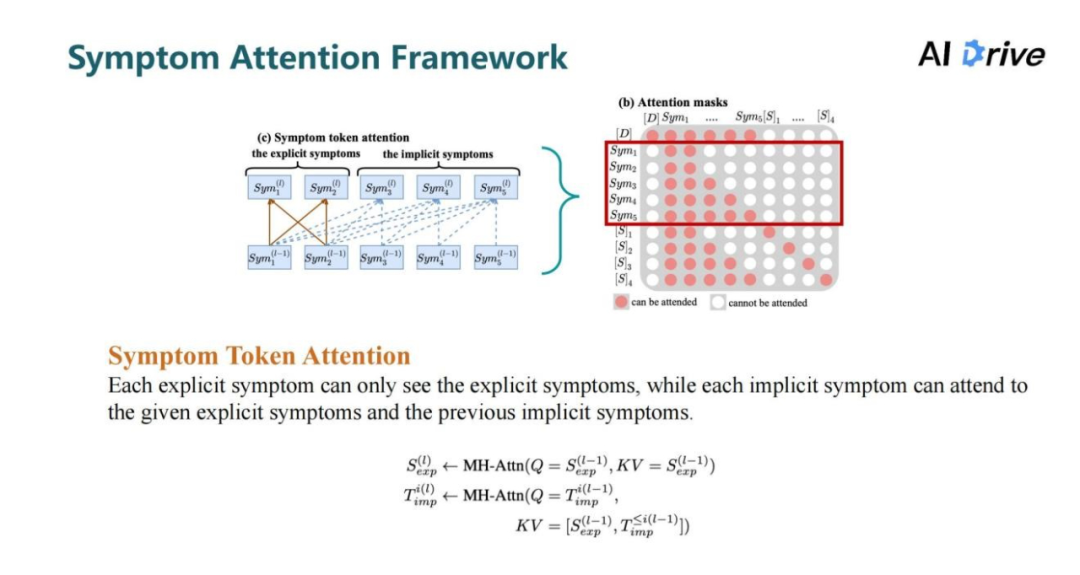
上图是症状注意力框架,模型将用户的症状作为输入,训练生成隐性症状序列,其中“END”符号表示结束信号,指示结束症状生成并转至疾病推理。对于模型的输入,将每个症状作为单一的 token,以此学习每个症状特定的表示,相比于 Transformer,去掉了位置编码,但加上了另外两种类型编码,分别是症状状态的 embedding 去表示症状的阴性或阳性,再加上症状的类型 embedding,表示它是显性症状或者隐性症状。
上图的右侧指的是 transformer 中的 Attention Masks,其主要用来控制它每个位置上的表示能否看到其他位置上的表示来进行交互的注意力机制的计算。
对此,让显性症状能够互相看到所有显性症状,而让隐性症状能看到自己以及前面的所有隐性症状和显性症状,从而可以实现自回归的隐性症状序列生成。
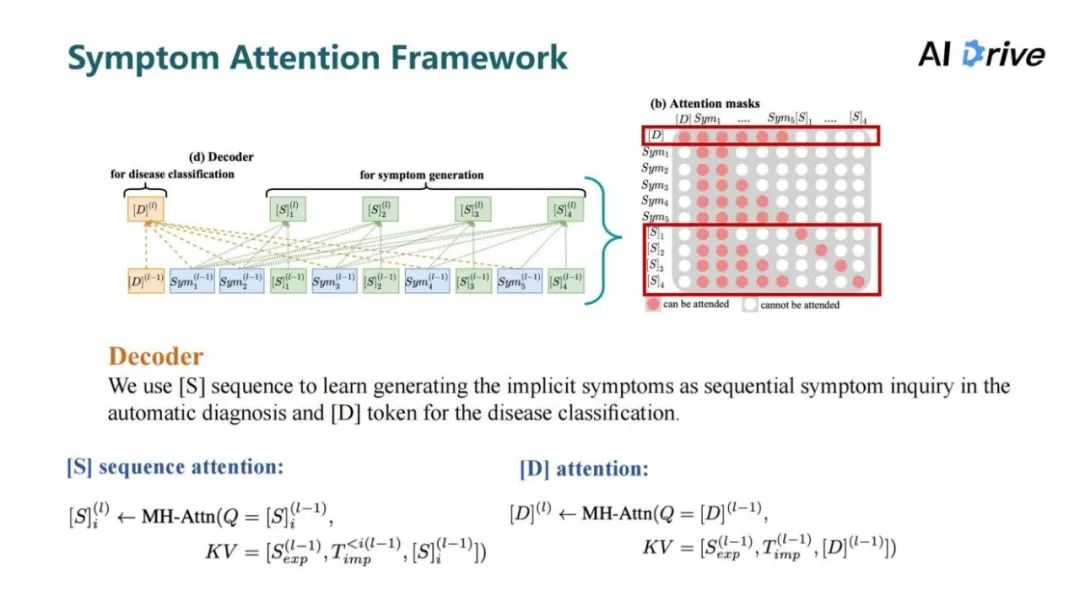
对于解码器,使用了两个人工符号,一个是症状预测的符号,另一个是疾病预测的符号。在训练过程中,利用症状预测符号序列来实现隐性症状序列的自回归生成,可视为一次学习多个阶段的症状推理;疾病预测符号则基于所有症状信息学习生成目标疾病。
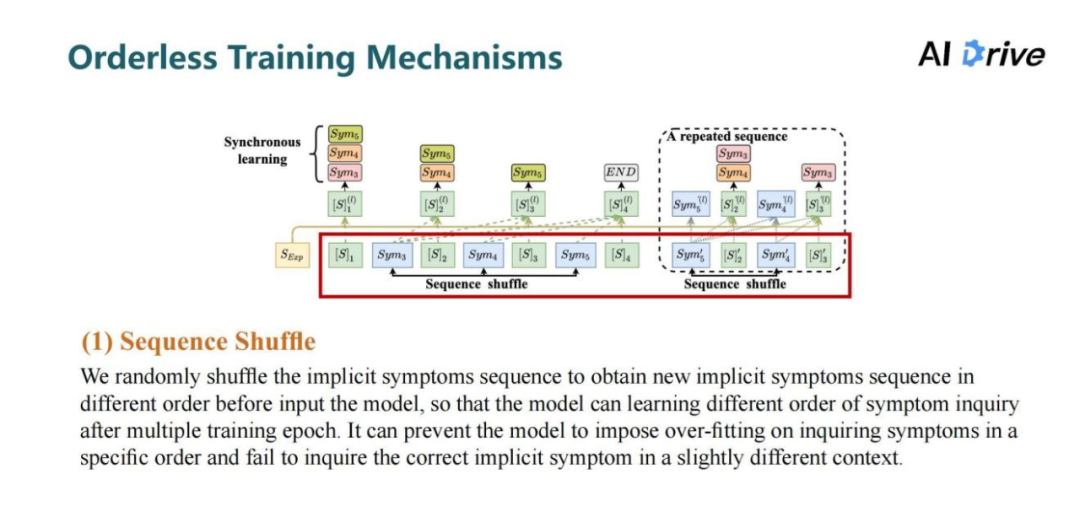
以上症状注意力框架是一个序列生成模型,它只能学习特定顺序的症状序列的生成,模型会在症状序列的次序下学习症状推理。但是在数据集或是在现实生活中,患者的隐性症状本身是没有次序关系,所以这导致了序列生成的有次序询问的学习逻辑与隐形症状推理的无序性的偏差。对此提出了三个无序的训练机制,让模型不依赖于特定的症状次序推理,从而学习显性症状到隐性症状以及隐性症状之间的推理。
第一个机制是序列打乱。在每次输入模型训练的序列时,会对隐性症状序列进行重新打乱,防止模型过度依赖于特定顺序的症状序列预测。
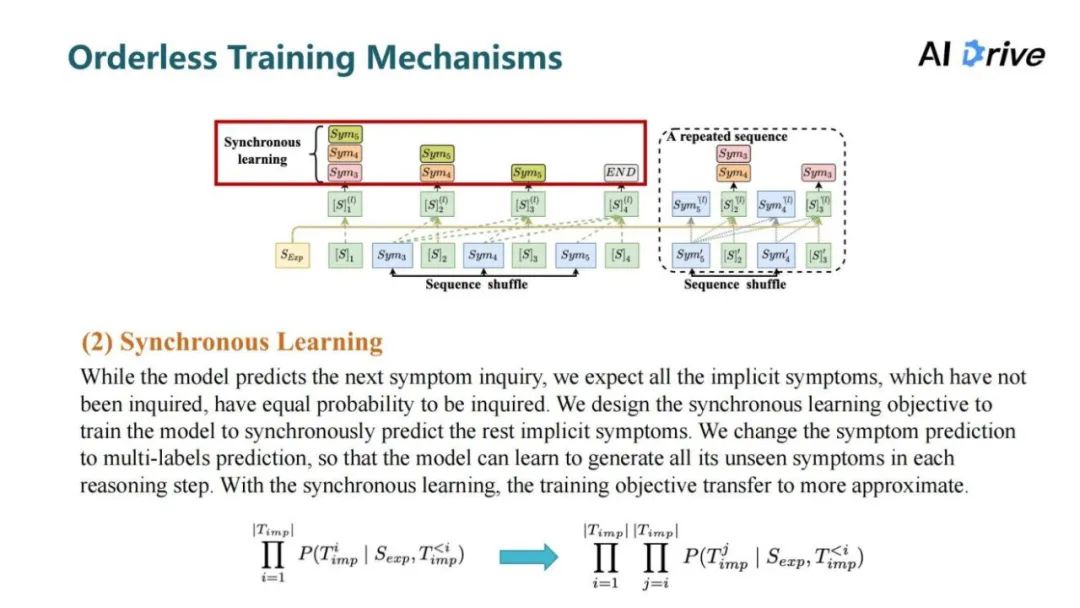
第二个机制是同步学习,对于每一阶段的症状询问预测,不应该是未被询问的症状里的某个症状,因为在未被询问的隐性症状里面,每个症状都应该是被预测的,所以在每一阶段让模型去学习预测出所有未被询问的隐形症状。由此将序列生成过程转变为多标签的序列生成过程。
由于是采用了多标签预测,所以采用了 concurrent softmax 替代了原本的 softmax,来训练多标签的症状序列生成。
第三个机制是重复序列,因为采用自回归生成的训练方式,每一个症状只能看到其前面症状的信息,模型在一条训练数据里只能学习到单一方向的症状预测,比如症状五能看到症状四和症状三的信息,如果先去学习预测症状五,再去预测症状四的时候就会导致信息的泄露。
对此利用插入症状子序列的方式,让模型能够在同一训练语句里面学习到不同顺序的症状生成,每个子序列都会共享主序列信息用于训练不同次序的症状序列生成。由于症状序列通常较短,在一定程度上扩展序列的长度,也有助于提示模型的训练效率。
以上便是模型的训练机制和过程。接下来是模型应用到推理的过程。
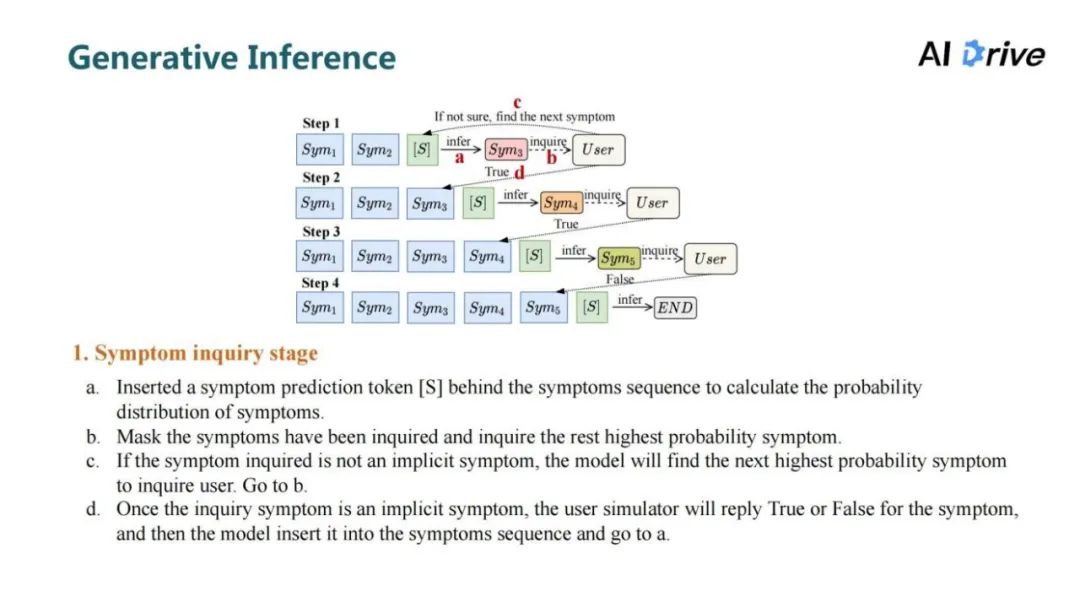
在推理时,需要一个用户的模拟器(图中“User”),它包含了所有的隐性症状信息,模型一开始获得显性症状;通过拼接症状预测符号,计算得到症状的概率分布。接着 Mask 已经询问过的症状,询问剩下症状中概率最高的症状。
在询问用户模拟器时,分为两种情况,第一种询问的症状不在隐性症状中,它会回复不确定,对于不确定信息会继续重复上述步骤,找到下一个最高概率的症状询问用户模拟器。
第二种,如果询问的症状在其隐性症状中,它会回复 True 或者 False 来作为回答。根据用户的回答,将新获得到的隐形症状做拼接,再使用症状预测符号去预测下一个症状。
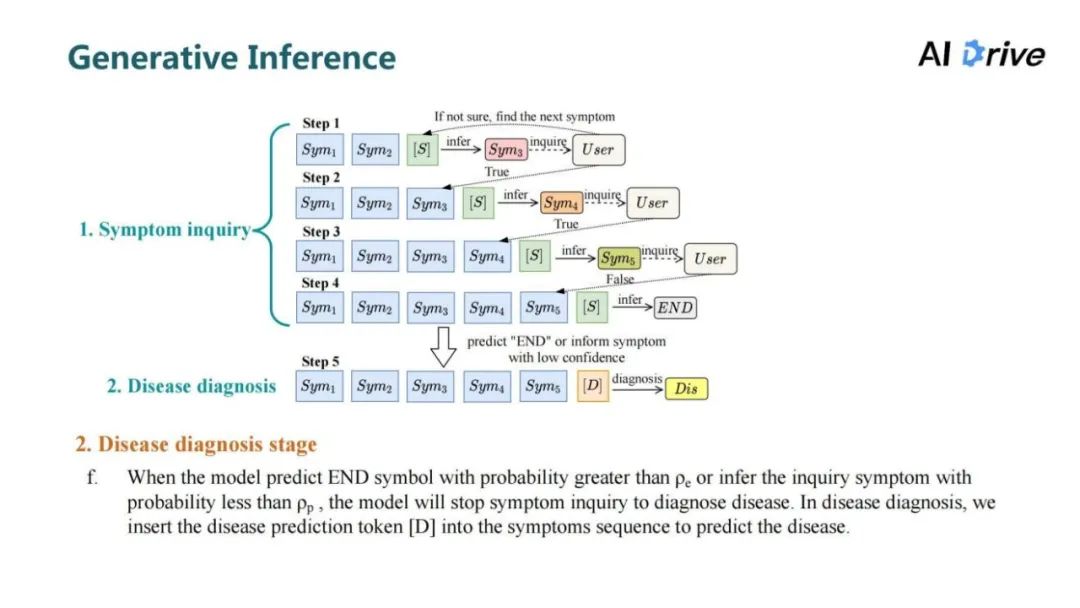
推理分为两个阶段,第一阶段就是询问用户的症状信息;第二阶段会根据询问的症状信息及其本身它的显性症状做疾病推理。
当由症状符号推理出结束信号,或者当预测症状概率的自信度低于阈值时,模型会停止症状询问从而进行疾病诊断,拼接疾病预测符号预测出目标疾病。
实验结果
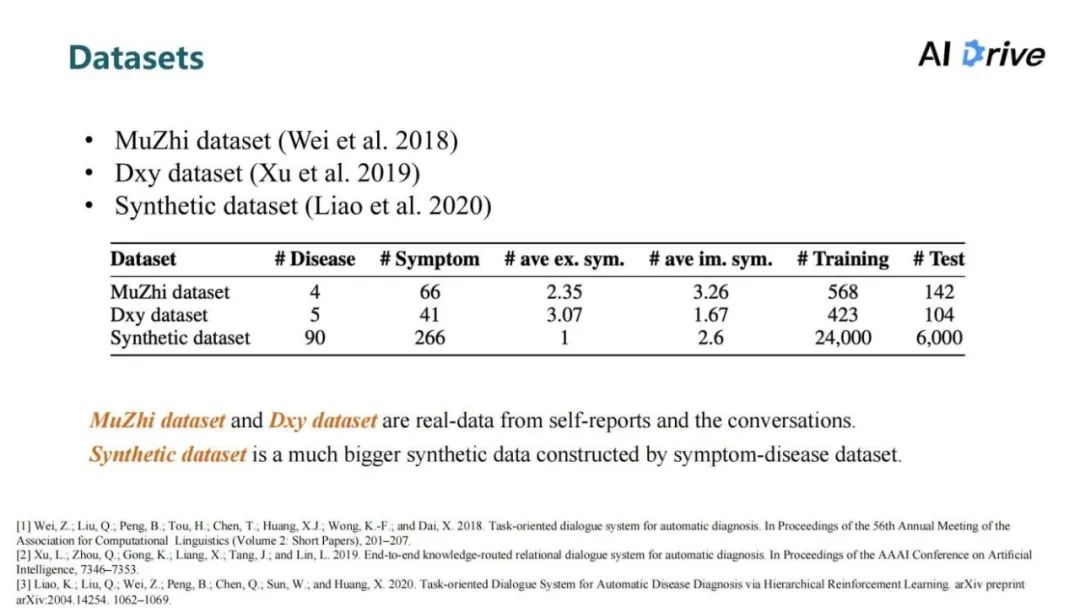
实验使用了三个公开的数据集。前两个数据集来源于真实数据,基于患者的自我报告以及患者和医生的对话流程构建。第三个数据集是基于症状到疾病的知识库构建的合成数据。合成数据集的数据规模明显大于前面两个真实数据,它的症状和疾病种类也明显更多。
对于对比模型,使用 SVM 直接做疾病分类(即不经过症状询问,直接通过显性症状来进行疾病诊断)来作为最基础的 Baselines。对于强化学习模型,主要选择了五个较新且具备代表性的强化学习模型。
此外还设置了两个序列生成的对比模型,它们都是基于症状注意力框架,使用了两个典型的序列生成模型作为它的训练目标;一个是 GPT2,另一个是 UniLM。这两个变体模型都会采用在输入的时候打乱序列的方式来对抗序列生成的偏差,也使用了与 Diaformer 相同的超参数。
评价机制主要有四个:Dacc 是诊断的准确率;SRec 是隐性症状的召回率;Aturn 是症状询问的平均轮数;Ttime 是模型的训练时间。
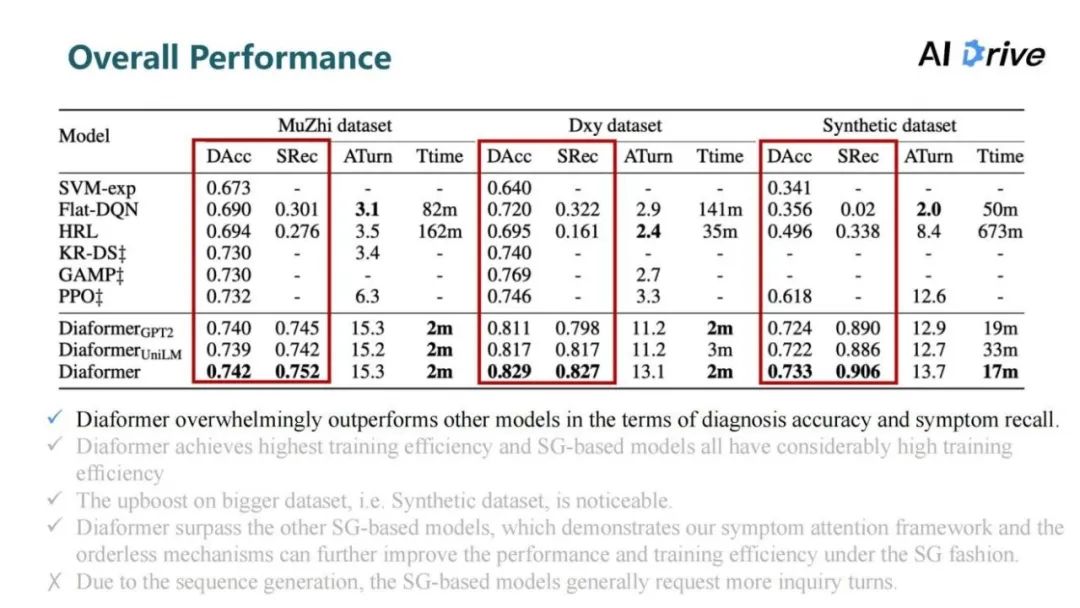
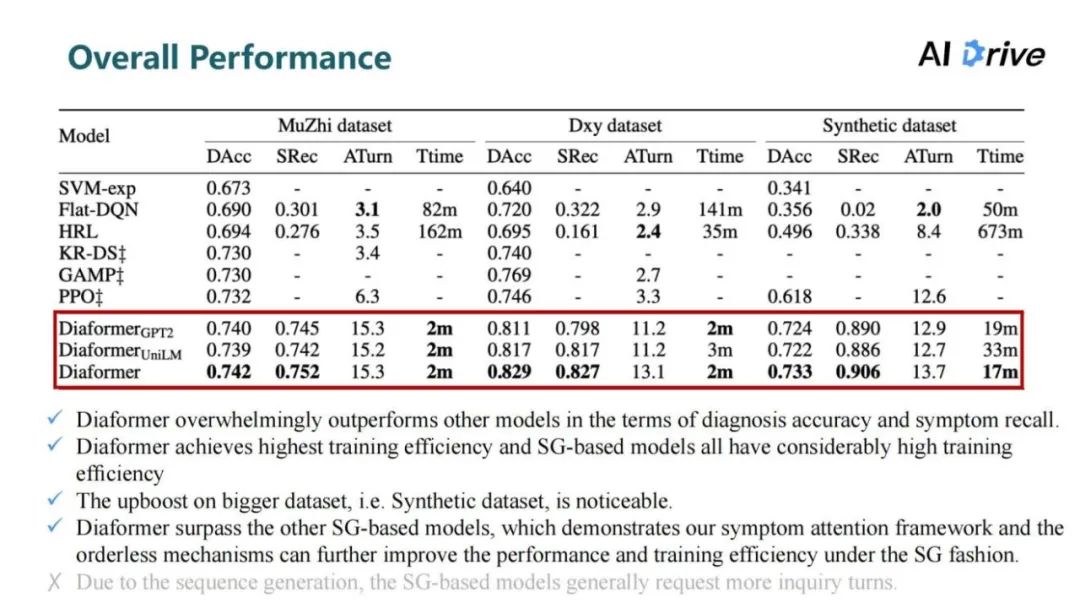
上图是模型的总体对比结果。可以看到,模型在两项重要的指标上,即疾病的准确率和召回率,都取得了最好的结果。
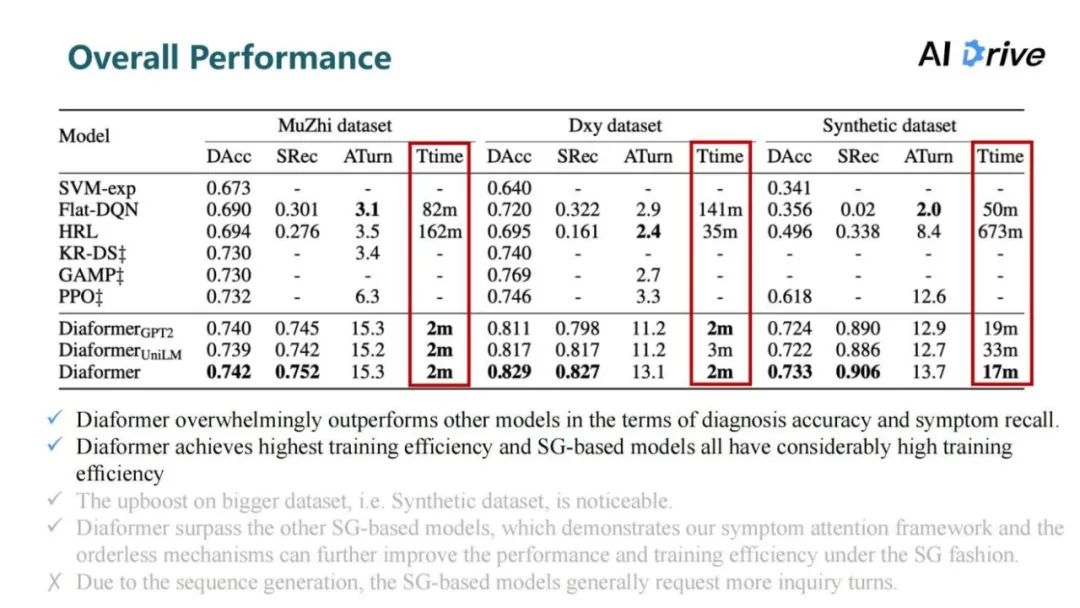
在训练时间上,序列生成模型的训练效率都是高于强化学习方法,在两个比较小的数据集上,只需要训练两分钟就可以达到非常好的效果。
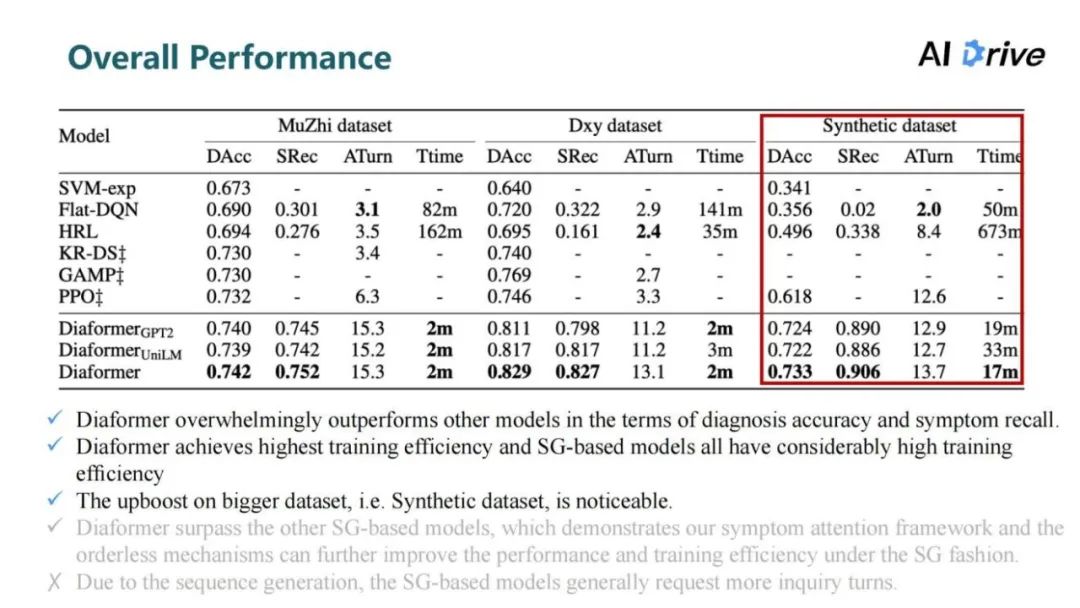
在比较大的合成数据集上(Synthetic dataset)提升是最为明显的,在诊断准确率上比强化学习的方法提升了 11%。
在序列生成模型对比上,Diaformer 也取得了各项更好的结果,这也说明了模型的有效性。
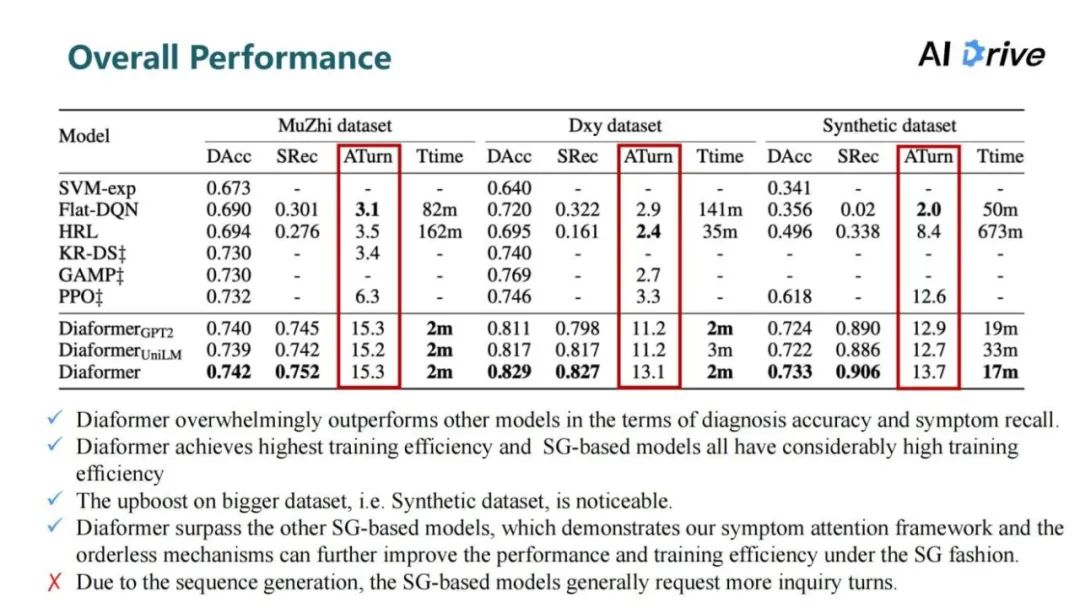
尽管如此,虽然实验模型都是在任务设定的最大询问轮数(20)的限制下,但其相比于强化学习的方法,序列生成的方法需要更多的询问次数。
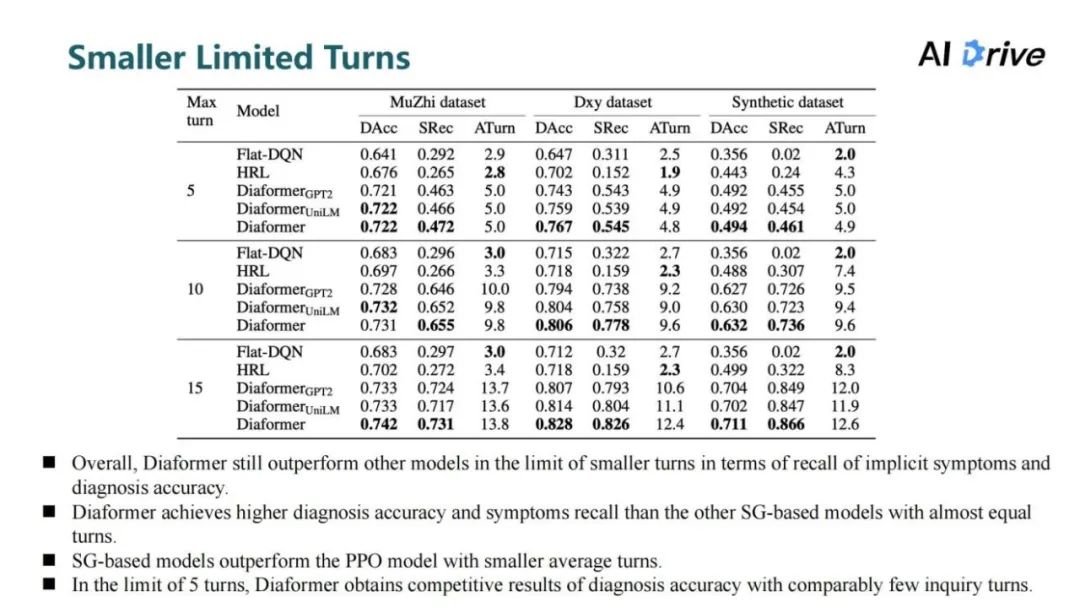
对此,设计了更小的限制轮数实验,测验序列生成模型在更低的询问次数情况下的表现。在原本 20 轮的基础上,增设了 5、10、15 的最多询问次数。在合成数据集的 10 轮询问的性质下,Diaformer 相比于强化学习最好的方法疾病诊断诊断准确率更高、所需询问轮数更少;在限制 5 轮的情况下,模型依旧能取得比较好的症状召回率和疾病预测的准确性。结果说明在更少的询问次数下,序列生成模型也能获得比较好的结果。
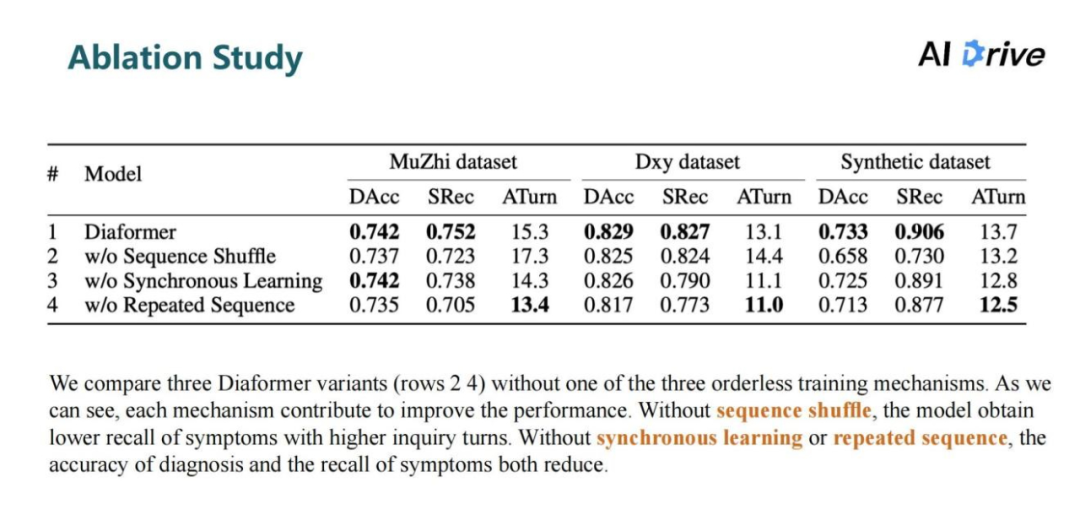
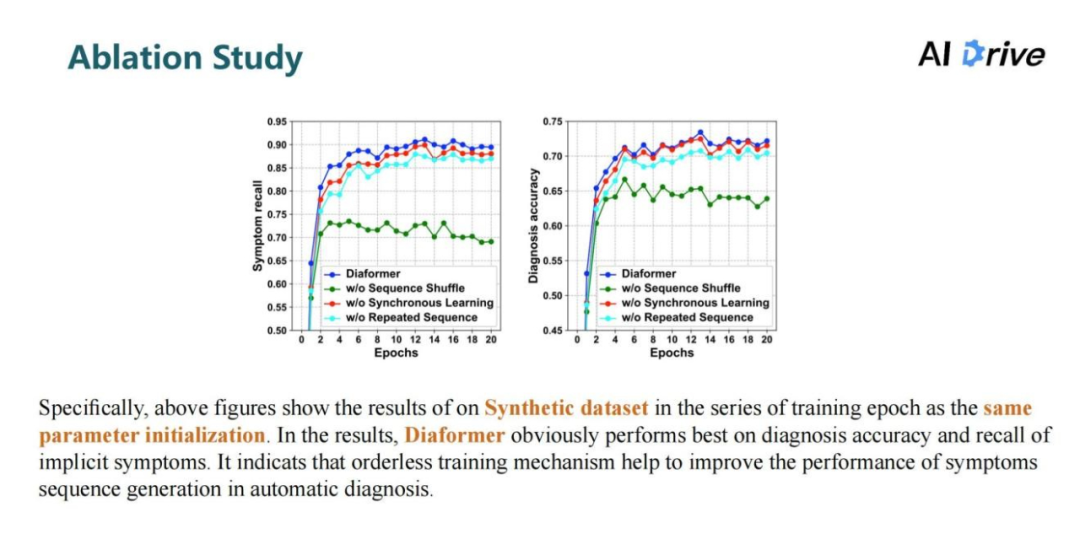
对三个的无序训练机制设定了一个消融实验,结果表明在缺少任何一种无序训练机制的情况下,症状的召回率还有疾病预测的准确率都会出现不同程度的下降,尤其是在比规模较大的合成数据集上,其性能下滑最为明显。
在合成数据集下,采用相同参数的初始化,对比每个的训练轮数下的结果比较。可以看出无论是症状的召回率或者是疾病预测的准确率上,使用了三个无序训练机制的模型,都能达到更高的学习效率以及取得更好的结果。
该工作将自动诊断任务形式化为序列生成任务,并提出了症状的注意力框架来实现序列生成的方式做自动诊断。此外提出了三个无序的训练机制,去减小训练生成的有序性与症状推理的无序性的偏差。这三个机制第一个是序列打乱,用来避免过度依赖于特定的测序的症状的询问;第二个是同步学习,即改成多标签的序列生成过程,预测所有的未被询问的隐性症状;第三个是重复序列,让模型在一个训练数据里学习序列不同次序的生成。结果表明,症状序列生成在自动诊断中是可行的。
最后是对未来工作的展望。第一是将自动诊断模型 Diaformer 整合到自动诊断的对话系统中,或者是一些任务导向型的对话系统中。因为对话系统本身是比如依赖于生成模型,而采用序列生成的方式,相比于强化学习方式,能更好的融入到对话生成里。第二个是找到更好的方法去有效减少序列生成的询问次数,第三是挖掘 Transformer 在决策推理问题上的潜力。
以上便是本期的全部内容,感兴趣的读者可以扫描上图的二维码,阅读相关论文还有代码。
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()