数据不平衡问题成“千年”难题,看ACL新方法Dice Loss如何有效解决!


自然语言处理中的“不平衡”数据集
-
训练与测试失配。占据绝大多数的负例会支配模型的训练过程,导致模型倾向于负例,而测试时使用的F1指标需要每个类都能准确预测; -
简单负例过多。负例占绝大多数也意味着其中包含了很多简单样本,这些简单样本对于模型学习困难样本几乎没有帮助,反而会在交叉熵的作用下推动模型遗忘对困难样本的知识。
-
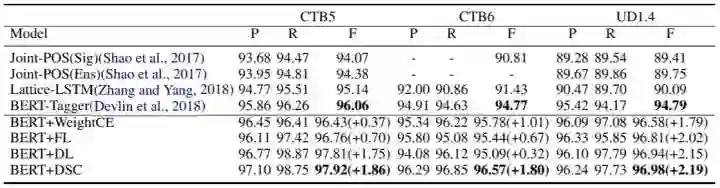
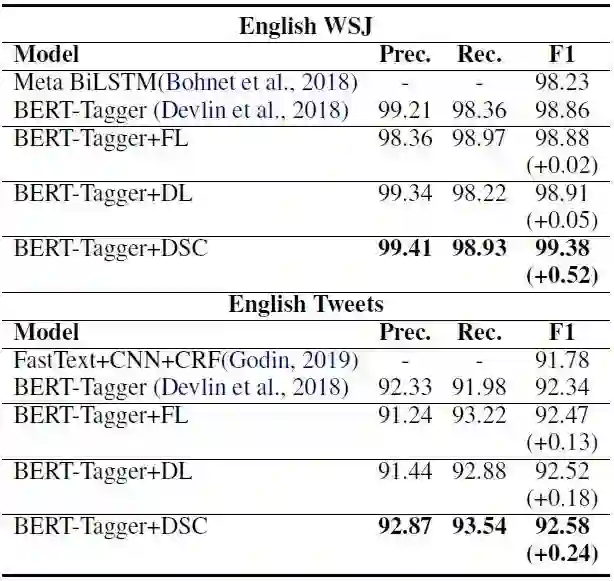
对词性标注,我们能在CTB5上达到97.92的F1,在CTB6上达到96.57的F1,在UD1.4上达到96.98,在WSJ上达到99.38,在Tweets上达到92.58,显著超越基线模型。 -
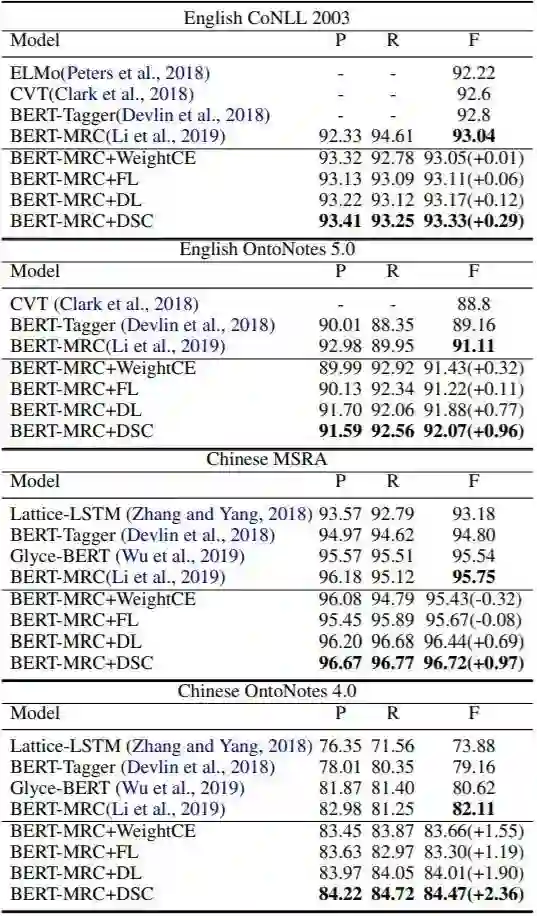
对命名实体识别,我们能在CoNLL2003上实现93.33,在OntoNotes5上实现92.07,在MSRA上实现96.72,在OntoNotes4上实现84.47的F1值,接近或超过当前最佳。 -
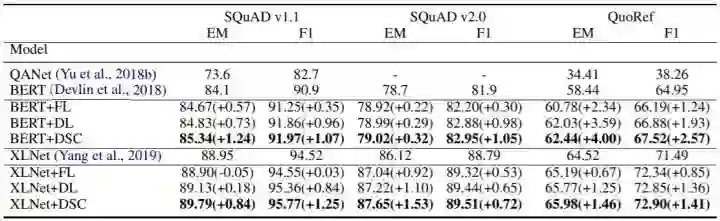
对问答,我们能在SQuAD1/2和QuoRef上超过基线模型约1个F1值。 -
对段落识别,我们的方法也能显著提高最终结果。
从Cross Entropy到Dice Losses
1、交叉熵损失(CE)
 ,输出为一个二值概率
,输出为一个二值概率
 ,并且有一个二元真值
,并且有一个二元真值
 。
。


2、Sørensen–Dice系数(DSC)





 实际上充当了缩放系数,对于简单样本(
实际上充当了缩放系数,对于简单样本(
 趋于1或0),
趋于1或0),
 使得模型更少地关注它们。从导数上看,一旦模型正确分类当前样本(刚刚经过0.5),DSC就会使模型更少关注它,而不是像交叉熵那样,鼓励模型迫近0或1这两个端点,这就能有效避免因简单样本过多导致模型训练受到简单样本的支配。
使得模型更少地关注它们。从导数上看,一旦模型正确分类当前样本(刚刚经过0.5),DSC就会使模型更少关注它,而不是像交叉熵那样,鼓励模型迫近0或1这两个端点,这就能有效避免因简单样本过多导致模型训练受到简单样本的支配。

3、Dice Loss(DL)与Tversky Loss(TL)
 的变体,分别是下述的Dice Loss(DL)和Tversky Loss(TL):
的变体,分别是下述的Dice Loss(DL)和Tversky Loss(TL):

 ,它就退化到了DSC。
,它就退化到了DSC。
4、损失总结



实验
1、词性标注
2、命名实体识别
3、问答
4、段落识别
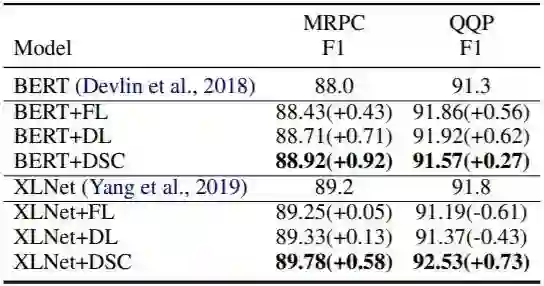
5、不平衡程度的影响
-
+positive:使用同义词替换等方式增加正类数量,使数据分布平衡(50:50) -
+negative:使用同义词替换等方式增加负类数量,使数据分布更加不平衡(21:79) -
-negative:随机删除负类,使数据分布平衡(50:50) -
+positive&+negative:同时增加正类和负类,使数据分布平衡(50:50)

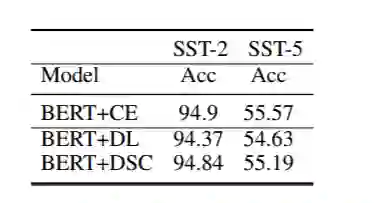
6、对以准确率为指标的任务的影响
小结

ACL 2020原定于2020年7月5日至10日在美国华盛顿西雅图举行,因新冠肺炎疫情改为线上会议。为促进学术交流,方便国内师生提早了解自然语言处理(NLP)前沿研究,AI 科技评论将推出「ACL 实验室系列论文解读」内容,同时欢迎更多实验室参与分享,敬请期待!
![]()
点击"阅读原文",直达“ACL 交流小组”了解更多会议信息。

登录查看更多
相关内容
专知会员服务
33+阅读 · 2019年11月24日



相关VIP内容
专知会员服务
33+阅读 · 2019年11月24日
相关资讯
相关论文