腾讯优图10篇AAAI论文解析,涉及数学速算批改、视频识别和语义分割 | 附下载
雷刚 发自 凹非寺
量子位 报道 | 公众号 QbitAI
AI顶会AAAI开幕在即,入选论文悉数披露。
今日介绍10篇论文,来自腾讯旗下视觉研发平台腾讯优图,涉及数学速算批改、视频识别、语义分割等技术领域,跨越识别、交通、教育和医疗等场景,是腾讯优图最新研发成果。
作为人工智能领域最悠久、涵盖内容最广泛的学术会议之一,AAAI会议的论文内容涉及AI和机器学习所有领域,关注的传统主题包括但不限于自然语言处理、深度学习等,同时大会还关注跨技术领域主题,如AI+行业应用等。

AAAI 2020将于2月7日-2月12日在美国纽约举办,根据目前披露的信息,最终收到有效论文8800篇,接收1591篇,接受率20.6%。
而腾讯优图这10篇入选论文,详情如下:

具体解读
1. 从时间和语义层面重新思考时间域融合用于基于视频的行人重识别(Oral)
Rethinking Temporal Fusion for Video-based Person Re-identification on Semantic and Time Aspect (Oral)
关键词:行人重识别、时间和语义、时间融合
论文链接:
https://arxiv.org/abs/1911.12512
解析:近年来对行人重识别(ReID)领域的研究不断深入,越来越多的研究者开始关注基于整段视频信息的聚合,来获取人体特征的方法。
然而,现有人员重识别方法,忽视了卷积神经网络在不同深度上提取信息在语义层面的差别,因此可能造成最终获取的视频特征表征能力的不足。
此外,传统方法在提取视频特征时没有考虑到帧间的关系,导致时序融合形成视频特征时的信息冗余,和以此带来的对关键信息的稀释。
为了解决这些问题,本文提出了一种新颖、通用的时序融合框架,同时在语义层面和时序层面上对帧信息进行聚合。
在语义层面上,本文使用多阶段聚合网络在多个语义层面上对视频信息进行提取,使得最终获取的特征更全面地表征视频信息。
而在时间层面上,本文对现有的帧内注意力机制进行了改进,加入帧间注意力模块,通过考虑帧间关系来有效降低时序融合中的信息冗余。
实验结果显示本文的方法能有效提升基于视频的行人识别准确度,达到目前最佳的性能。
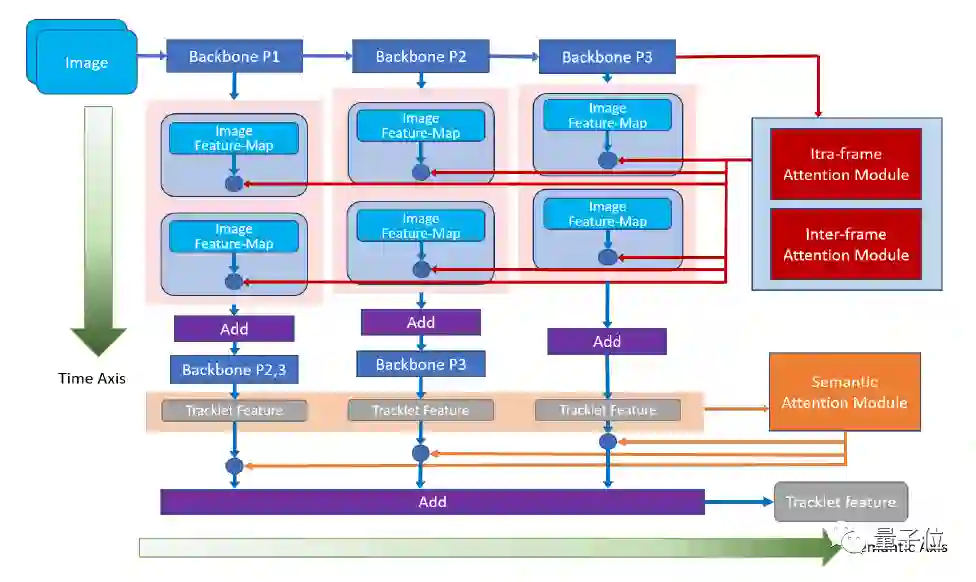
2.速算批改中的带结构文本识别
Accurate Structured-Text Spotting for Arithmetical Exercise Correction
关键字:速算批改,算式检测与识别
对于中小学教师而言,数学作业批改一直是一项劳动密集型任务,为了减轻教师的负担,本文提出算术作业检查器,一个自动评估图像上所有算术表达式正误的系统。
其主要挑战是,算术表达式往往是由具有特殊格式(例如,多行式,分数式)的印刷文本和手写文本所混合组成的。
面临这个挑战,传统的速算批改方案在实际业务中暴露出了许多问题。本文在算式检测和识别两方面,针对实际问题提出了解决方案。
针对算式检测中出现的非法算式候选问题,文中在无需锚框的检测方法CenterNet的基础上,进一步设计了横向边缘聚焦的损失函数。
CenterNet通过捕捉对象的两个边角位置来定位算式对象,同时学习对象内部的信息作为补充,避免生成 ”中空“的对象,在算式检测任务上具有较好的适性。
横向边缘聚焦的损失函数进一步把损失更新的关注点放在更易产生、更难定位的算式左右边缘上,避免产生合理却不合法的算式候选。该方法在检测召回率和准确率上都有较为明显的提升。
在算式识别框方面,为避免无意义的上下文信息干扰识别结果,文中提出基于上下文门函数的识别方法。
该方法利用一个门函数来均衡图像表征和上下文信息的输入权重,迫使识别模型更多地学习图像表征,从而避免无意义的上下文信息干扰识别结果。
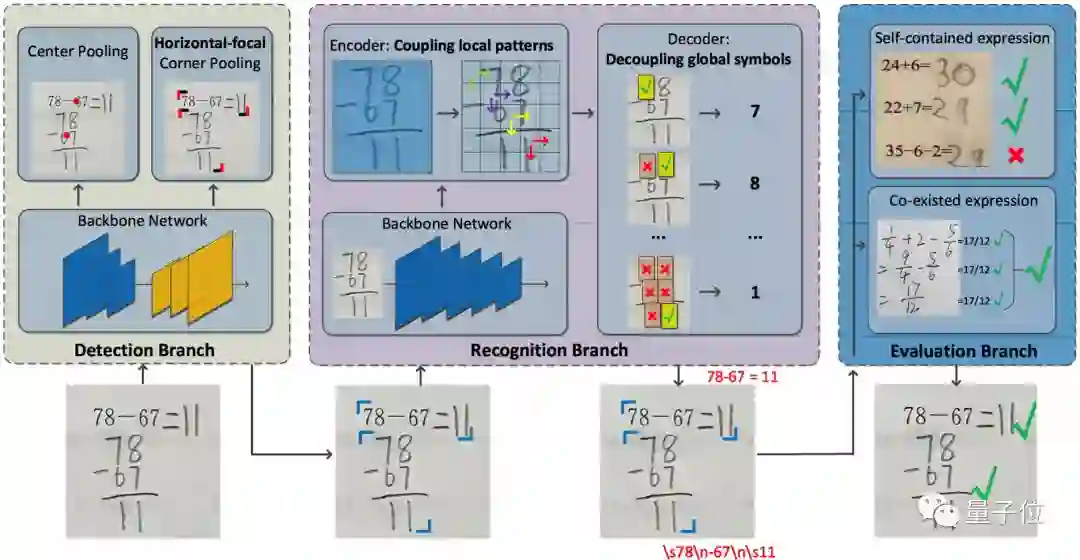
3. 基于稠密边界生成器的时序动作提名的快速学习
Fast Learning of Temporal Action Proposal via Dense Boundary Generator
关键词:DBG动作检测法、算法框架、开源
论文链接:
https://arxiv.org/abs/1911.04127
视频动作检测技术是精彩视频集锦、视频字幕生成、动作识别等任务的基础,随着互联网的飞速发展,在产业界中得到越来越广泛地应用,而互联网场景视频内容的多样性也对技术提出了很多的挑战,如视频场景复杂、动作长度差异较大等。
针对这些挑战, 本文针对DBG动作检测算法,提出3点创新:
(1)提出一种快速的、端到端的稠密边界动作生成器(Dense Boundary Generator,DBG)。该生成器能够对所有的动作提名(proposal)估计出稠密的边界置信度图。
(2)引入额外的时序上的动作分类损失函数来监督动作概率特征(action score feature,asf),该特征能够促进动作完整度回归(Action-aware Completeness Regression,ACR)。
(3)设计一种高效的动作提名特征生成层(Proposal Feature Generation Layer,PFG),该Layer能够有效捕获动作的全局特征,方便实施后面的分类和回归模块。
其算法框架主要包含视频特征抽取(Video Representation),稠密边界动作检测器(DBG),后处理(Post-processing)三部分内容。
目前腾讯优图DBG的相关代码已在GitHub上开源,并在ActivityNet上排名第一。
传送门:
https://github.com/TencentYoutuResearch/ActionDetection-DBG
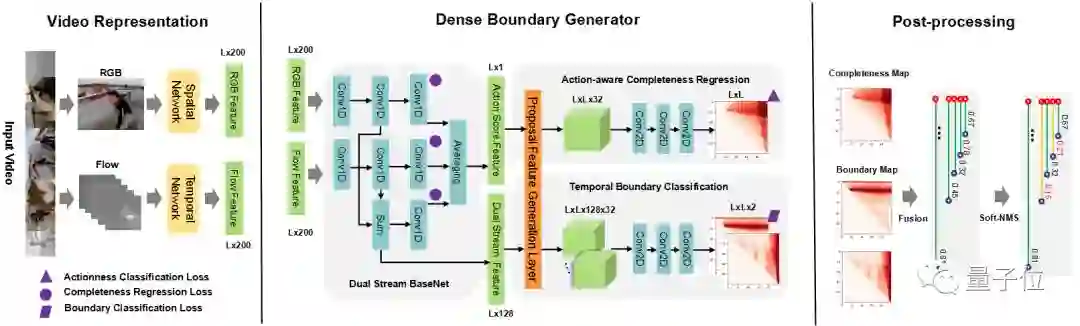
4. TEINet:迈向视频识别的高效架构
TEINet: Towards an Efficient Architecture for Video Recognition
关键词:TEI模块、时序建模、时序结构
论文链接:
https://arxiv.org/abs/1911.09435
本文提出了一种快速的时序建模模块,即TEI模块。
该模块能够轻松加入已有的2D CNN网络中。与以往的时序建模方式不同,TEI通过channel维度上的attention以及channel维度上的时序交互来学习时序特征。
首先,TEI所包含的MEM模块能够增强运动相关特征,同时抑制无关特征(例如背景),然后TEI中的TIM模块在channel维度上补充前后时序信息。
这两个模块不仅能够灵活而有效地捕捉时序结构,而且在inference时保证效率。本文通过充分实验在多个benchmark上验证了TEI中两个模块的有效性。
5. 通过自监督特征学习重新审视图像美学质量评估
Revisiting Image Aesthetic Assessment via Self-Supervised Feature Learning
关键词:美学评估、自我监督、计算机视觉
论文链接:
https://arxiv.org/abs/1911.11419
图像美学质量评估是计算机视觉领域中一个重要研究课题。近年来,研究者们提出了很多有效的方法,在美学评估问题上取得了很大进展。这些方法基本上都依赖于大规模的、与视觉美学相关图像标签或属性,但这些信息往往需要耗费巨大人力成本。
为了能够缓解人工标注成本,“使用自监督学习来学习具有美学表达力的视觉表征”是一个具有研究价值的方向。
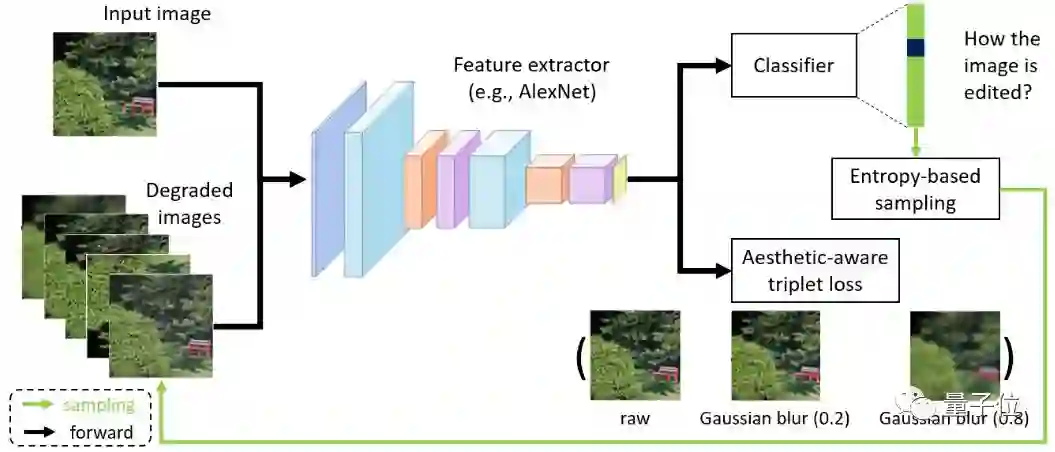
本文在这个方向上提出了一种简单且有效的自监督学习方法。我们方法的核心动机是:若一个表征空间不能鉴别不同的图像编辑操作所带来的美学质量的变化,那么这个表征空间也不适合图像美学质量评估任务。
从这个动机出发,本文提出了两种不同的自监督学习任务:一个用来要求模型识别出施加在输入图像上的编辑操作的类型;另一个要求模型区分同一类操作在不同控制参数下所产生的美学质量变动的差异,以此来进一步优化视觉表征空间。
为了对比实验的需要,本文将提出的方法与现有的经典的自监督学习方法(如,Colorization,Split-brain,RotNet等)进行比较。
实验结果表明:在三个公开的美学评估数据集上(即AVA,AADB,和CUHK-PQ),本文的方法都能取得颇具竞争力的性能。而且值得注意的是:本文的方法能够优于直接使用 ImageNet 或者 Places 数据集的标签来学习表征的方法。
此外,我们还验证了:在 AVA 数据集上,基于我们方法的模型,能够在不使用 ImageNet 数据集的标签的情况下,取得与最佳方法相当的性能。
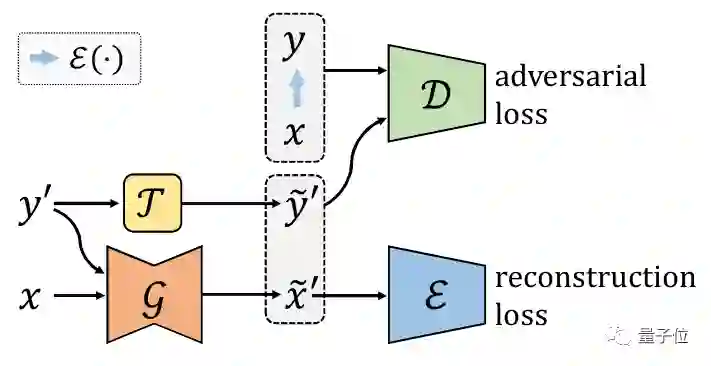
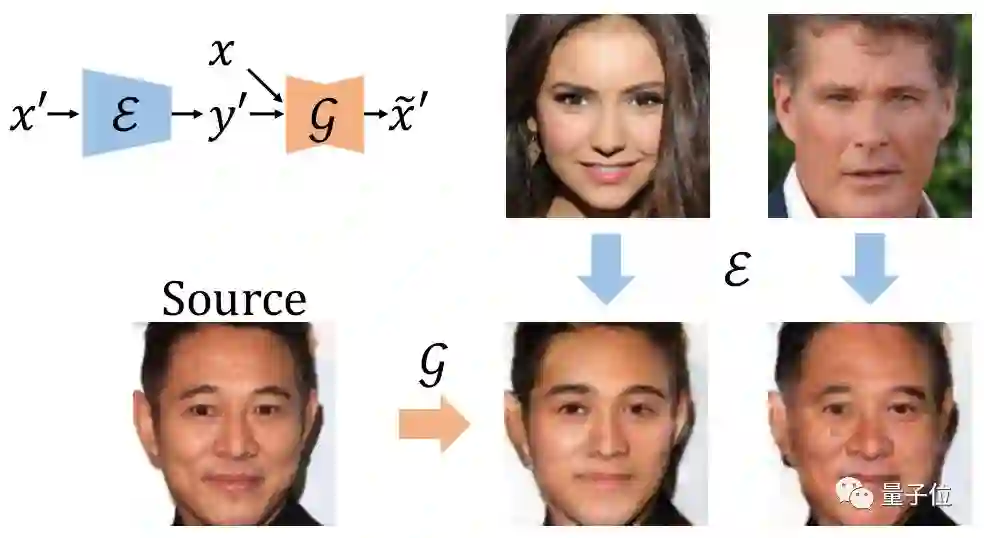
6. 基于生成模型的视频域适应技术
Generative Adversarial Networks for Video-to-Video Domain Adaptation
关键字:视频生成,无监督学习,域适应
来自多中心的内窥镜视频通常具有不同的成像条件,例如颜色和照明,这使得在一个域上训练的模型无法很好地推广到另一个域。域适应是解决该问题的潜在解决方案之一。但是,目前很少工作能集中在视频数据域适应处理任务上。
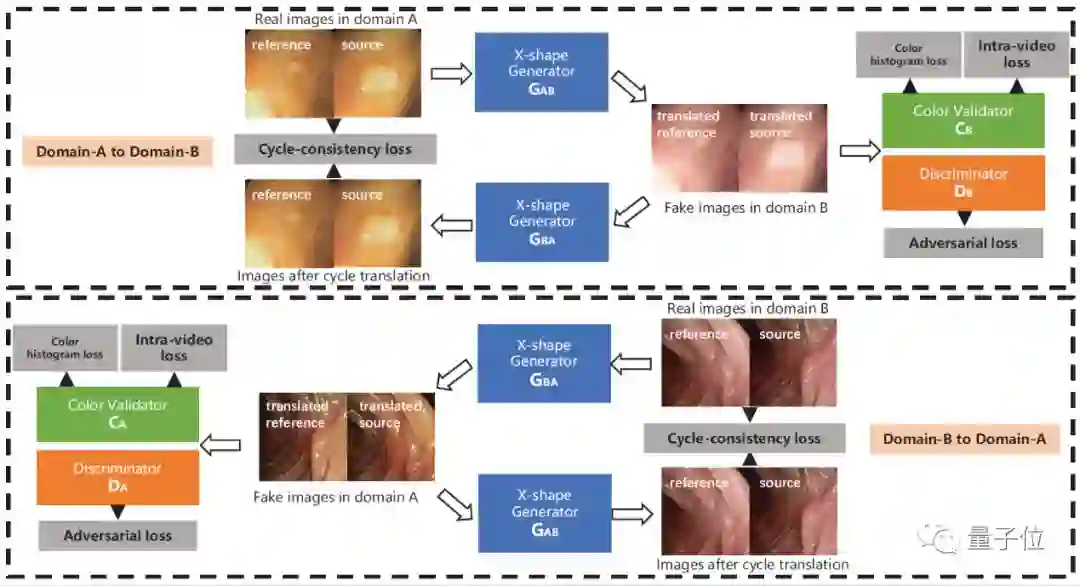
为解决上述问题,本文提出了一种新颖的生成对抗网络(GAN)即VideoGAN,以在不同域之间转换视频数据。
实验结果表明,由VideoGAN生成的域适应结肠镜检查视频,可以显著提高深度学习网络在多中心数据集上结直肠息肉的分割准确度。
由于我们的VideoGAN是通用的网络体系结构,因此本文还将CamVid驾驶视频数据集上进行了测试。实验表明, 我们的VideoGAN可以大大缩小域间差距。
7. 非对称协同教学用于无监督的跨领域行人再识别
Asymmetric Co-Teaching for Unsupervised Cross-Domain Person Re-Identification
关键词:行人重识别、非对称协同教学、域适应
论文链接:
https://arxiv.org/abs/1912.01349
行人重识别由于样本的高方差及成图质量,一直以来都是极具挑战性的课题。虽然在一些固定场景下的re-ID取得了很大进展(源域),但只有极少的工作能够在模型未见过的目标域上得到很好的效果。
目前有一种有效解决方法,是通过聚类为无标记数据打上伪标签,辅助模型适应新场景,然而,聚类往往会引入标签噪声,并且会丢弃低置信度样本,阻碍模型精度提升。
本文通过提出非对称协同教学方法,更有效地利用挖掘样本,提升域适应精度。具体来说,就是使用两个网络,一个网络接收尽可能纯净的样本,另一个网络接收尽可能多样的样本,在“类协同教学”的框架下,该方法在滤除噪声样本的同时,可将更多低置信度样本纳入到训练过程中。多个公开实验可说明此方法能有效提升现阶段域适应精度,并可用于不同聚类方法下的域适应。

8. 带角度正则的朝向敏感损失用于行人再识别
Viewpoint-Aware Loss with Angular Regularization for Person Re-Identification
关键词:行人重识别、朝向、建模
论文链接:
https://arxiv.org/abs/1912.01300
近年来有监督的行人重识别(ReID)取得了重大进展,但是行人图像间巨大朝向差异,使得这一问题仍然充满挑战。
大多数现有的基于朝向的特征学习方法,将来自不同朝向的图像映射到分离和独立的子特征空间当中。
这种方法只建模了一个朝向下人体图像的身份级别的特征分布,却忽略了朝向间潜在的关联关系。
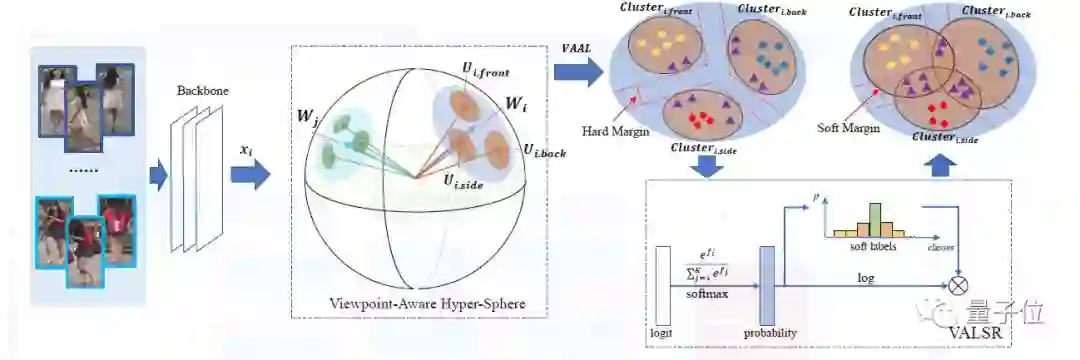
为解决这一问题,本文提出了一种新的方法,叫带角度正则的朝向敏感损失(VA-ReID)。
相比每一个朝向学习一个子空间,该方法能够将来自不同朝向的特征映射到同一个超球面上,这样就能同时建模身份级别和朝向级别的特征分布。在此基础上,相比传统分类方法将不同的朝向建模成硬标签,本文提出了朝向敏感的自适应标签平滑正则方法(VALSR)。这一方法能够给予特征表示自适应的软朝向标签,从而解决了部分朝向无法明确标注的问题。
大量在Market1501和DukeMTMC数据集上的实验证明了本文的方法有效性,其性能显著超越已有的最好有监督ReID方法。
9. 如何利用弱监督信息训练条件对抗生成模型
Robust Conditional GAN from Uncertainty-Aware Pairwise Comparisons
关键词:CGAN、弱监督、成对比较
论文链接:
https://arxiv.org/abs/1911.09298
条件对抗生成网络(conditinal GAN, CGAN)已在近些年取得很大成就,并且在图片属性编辑等领域有成功的应用。
但是CGAN往往需要大量标注。为了解决这个问题,现有方法大多基于无监督聚类,比如先用无监督学习方法得到伪标注,再用伪标注当作真标注训练CGAN。
然而,当目标属性是连续值而非离散值时,或者目标属性不能表征数据间的主要差异,那么这种基于无监督聚类的方法就难以取得理想效果。
本文进而考虑用弱监督信息去训练CGAN,在文中我们考虑成对比较这种弱监督。成对比较相较于绝对标注具有以下优点:
更容易标注;
更准确;
不易受主观影响。
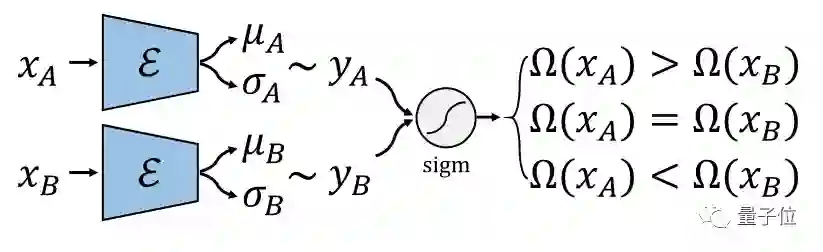
我们提出先训练一个比较网络来预测每张图片的得分,再将这个得分当做条件训练CGAN。第一部分的比较网络我们受到国际象棋等比赛中常用的等级分(Elo rating system)算法的启发,将一次成对比较的标注视为一次比赛,用一个网络预测图片的得分,我们根据等级分设计了可以反向传播学习的神经网络。
我们还考虑了网络的贝叶斯版本,使网络具有估计不确定性的能力。对于图像生成部分,我们将鲁棒条件对抗生成网络(RObust Conditional GAN, RCGAN)拓展到条件是连续值的情形。具体的,与生成的假图对应的预测得分在被判别器接收之前会被一个重采样过程污染。这个重采样过程需要用到贝叶斯比较网络的不确定性估计。
我们在四个数据集上进行了实验,分别改变人脸图像的年龄和颜值。
实验结果表明提出的弱监督方法和全监督基线相当,并远远好于非监督基线。
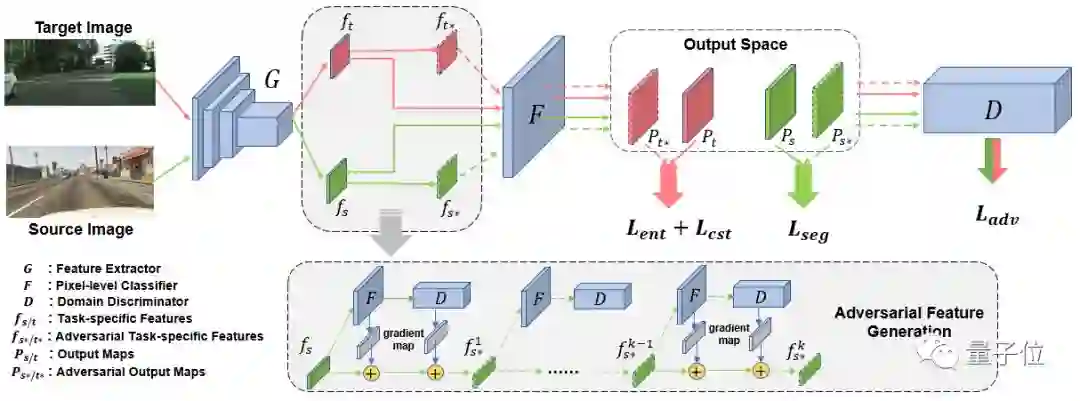
10. 基于对抗扰动的无监督领域自适应语义分割
An Adversarial Perturbation Oriented Domain Adaptation Approach for Semantic Segmentation
关键词:无监督领域自适应、语义分割、对抗训练
论文链接:
https://arxiv.org/pdf/1912.08954.pdf
如今神经网络借助大量标注数据已经能够达到很好的效果,但是往往不能很好的泛化到一个新的环境中,而且大量数据标注是十分昂贵的。因此,无监督领域自适应就尝试借助已有的有标注数据训练出模型,并迁移到无标注数据上。
对抗对齐(adversarial alignment)方法被广泛应用在无监督领域自适应问题上,全局地匹配两个领域间特征表达的边缘分布。
但由于语义分割任务上数据的长尾分布(long-tail)严重且缺乏类别上的领域适配监督,领域间匹配的过程最终会被大物体类别(如:公路、建筑)主导,从而导致这种策略容易忽略尾部类别或小物体(如:红路灯、自行车)的特征表达。
本文提出了一种生成对抗扰动并防御的框架。
首先该框架设计了几个对抗目标(分类器和鉴别器),并通过对抗目标在两个领域的特征空间分别逐点生成对抗样本。这些对抗样本连接了两个领域的特征表达空间,并蕴含网络脆弱的信息。然后该框架强制模型防御对抗样本,从而得到一个对于领域变化和物体尺寸、类别长尾分布都更鲁棒的模型。
本文提出的对抗扰动框架,在两个合成数据迁移到真实数据的任务上进行了验证。该方法不仅在图像整体分割上取得了优异的性能,并且大大提升了模型在小物体和类别上的精度,证明了其有效性。
— 完 —
AI内参|把握AI发展新机遇
拓展优质人脉,获取最新AI资讯&论文教程,欢迎加入AI内参社群一起学习~

跟大咖交流 | 进入AI社群


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !


