【谷歌大脑团队GAN生态权威报告】6种优化GAN模型对比,最优秀的仍是原始版本
新智元AI World 2017世界人工智能大会开场视频
中国人工智能资讯智库社交主平台新智元主办的 AI WORLD 2017 世界人工智能大会11月8日在北京国家会议中心举行,大会以“AI 新万象,中国智能+”为主题,上百位AI领袖作了覆盖技术、学术和产业最前沿的报告和讨论,2000多名业内人士参会。新智元创始人兼CEO杨静在会上发布全球首个AI专家互动资讯平台“新智元V享圈”。
全程回顾新智元AI World 2017世界人工智能大会盛况:
新华网图文回顾
http://www.xinhuanet.com/money/jrzb20171108/index.htm
爱奇艺
上午:http://www.iqiyi.com/v_19rrdp002w.html
下午:http://www.iqiyi.com/v_19rrdozo4c.html
阿里云云栖社区
https://yq.aliyun.com/webinar/play/316?spm=5176.8067841.wnnow.14.ZrBcrm
新智元编译
来源:arXiv
编译:刘小芹
【新智元导读】谷歌大脑团队的研究者发表题为《Are GANs Created Equal? A Large-Scale Study》的论文,对MM GAN、NS GAN、WGAN、WGAN GP、LS GAN、DRAGAN、BEGAN等近期出现的优秀GAN模型进行了客观的性能比较,发现这些模型并没有像它们声称的那样优于原始GAN。
GAN的发明人Ian Goodfellow在推特评论此工作:ML的研究人员,审稿人和有关ML的新闻报道需要对结果的统计稳健性和超参数的效果进行更认真的研究。这项研究表明,过去一年多的很多论文只是观察抽样误差,而不是真正的改进。
论文:https://arxiv.org/pdf/1711.10337.pdf


摘要
生成对抗网络(GAN)是生成模型的一个强大的子类。尽管这一领域的研究活动非常丰富,产生了许多有趣的GAN算法,但仍然很难评估哪个(哪些)算法比其他算法更好。在本研究中,我们对那些声称state-of-the-art的模型和评估方法进行了一个中立的、多角度的大规模实证研究。我们发现,大多数模型可以通过足够的超参数优化和随机重启获得差不多的得分。这表明,改进可能是来自更高的计算预算和比基本的算法变化更多的调参。为了克服当前的指标(metric)的一些限制,我们还提出了几个可以计算精度(precision)和召回率(recall)的数据集。我们的实验结果表明,未来的GAN研究应该建立在更系统、客观的评估程序基础上。最后,我们没有发现本研究所测试的任何一个算法一直优于原始算法的证据。
生成对抗网络(GAN)是生成模型的一个强大的子类,并且已经成功地应用于图像生成和编辑,半监督学习和域适应(domain adaptation)。在GAN框架中,模型学习一个简单分布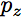
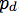
最近很多研究者提出了各种不同的GAN,包括无监督的(如Wasserstein GAN、BEGAN)以及有条件的(如CGAN)。 虽然这些模型在特定的领域取得了令人瞩目的成果,但是客观地看,哪些GAN算法比其他算法性能更好,这仍然没有明确的共识。这在一定程度上是由于缺乏强大和一致的指标(metric),以及很少有比较能够将所有算法放在相同的条件上,包括用于在所有超参数上进行搜索的计算预算。这为什么重要?首先,能够帮助实践者从很多算法中选择一个更好的算法。其次,为了得到更好的算法和算法理解,清楚地评估哪些修改是关键的,哪些修改只是在论文层面表现好,但在实践中并没有太大的差别,这样的研究很有帮助。
评估的主要问题是由于不能明确地计算概率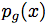
在本研究中,我们提出了两个评估指标来定量评估GAN的性能。两个指标都假定可以访问预训练的分类器。Inception Score(IS)[20]基于这样一个事实:一个好的模型应该生成这样样本,当被分类器评估时,类分布的熵要低。同时它应该生成各种各样的样本,涵盖所有的类。相反,通过考虑真实数据和假数据的嵌入差异,可以计算Frechet Inception Distance(FID)。假设编码层遵循多变量高斯分布,则分布之间的距离被减小到相应高斯之间的Frechet距离。
本研究的主要贡献:
我们对state-of-the-art的一些GAN模型进行了公平、全面的比较,并且根据经验证明,在有足够高的计算预算的情况下,几乎所有这些GAN都可以达到相似的FID值。
我们提供了强有力的实验证据(重现这些实验的计算预算大约是60K P100 GPU小时),证明为了比较GAN的性能,有必要报告其结果分布的一个summary,而不是只报告最好的结果,因为优化过程存在随机性和模型不稳定性。
我们评估了FID对mode dropping的鲁棒性,使用了不同的编码网络,并提供了在经典数据集上可实现的最佳FID估计。
我们提出了一系列难度增加的任务,可以近似计算广为接受的度量,例如精确度和召回率。
我们将很快开源我们的实验设置和模型实现。
具体的相关研究背景和实验过程请查阅原论文。

图1:在mode dropping下,FID快速下降
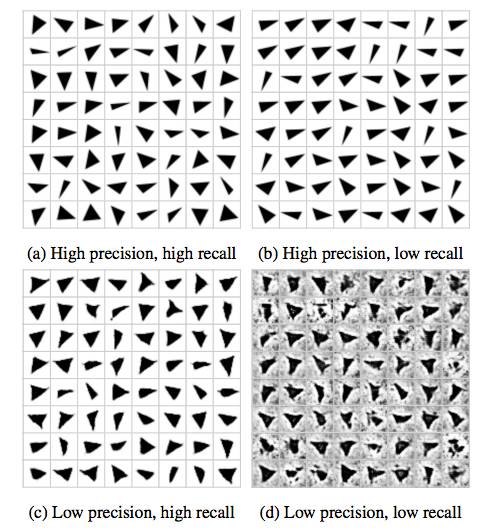
图3:不同精确度和召回率下的模型的样本
综合考虑各维度,以下是该研究的实验选择:
架构:我们对所有模型使用相同的架构,该架构足够实现良好的性能。
超参数:对于训练超参数(例如学习率)以及特定模型的(例如gradient penalty multiplier),有两种有效的方法:(i)对每个数据集执行超参数优化,或(ii) 在一个数据集上执行超参数优化,并推断在其他数据集上使用的超范围参数。
随机种子:即使其他条件都固定,改变随机种子也可能对结果产生很大的影响。我们研究这个特定影响,并报告了相应的置信区间。
数据集:我们从各种GAN文献中选择了四个流行的数据集,并对每个数据集分别报告结果。
计算预算:根据预算来优化参数,不同的算法可以达到最好的结果。我们探索了不同计算预算下结果的变化。

表2:数据集
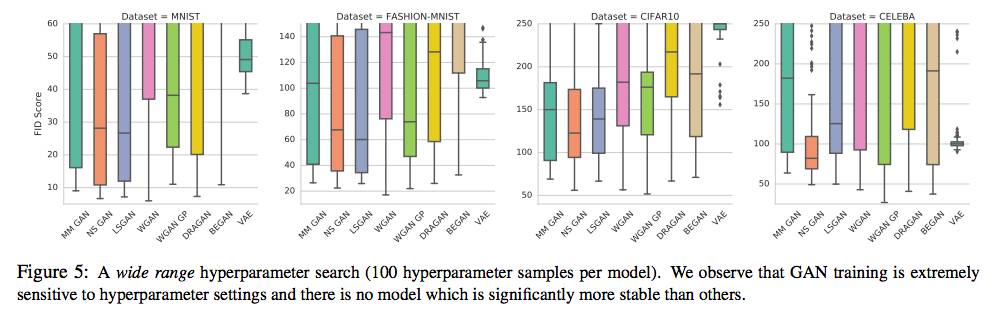
图5:大范围超参数搜索(每个模型100个超参数样本)。我们观察到,GAN训练对超参数设置是非常敏感的,没有特别稳定的模型。
在这个研究中,作者就如何中立、公平地比较GAN进行了讨论。本研究主要关注两个评估指标:Frechet Inception Distance(FID)和(ii)精确度、召回率以及F₁。我们提供的实证表明,FID是一个合理的指标,因为它在mode dropping和编码网络选择方面有鲁棒性。
基于FID的比较。
我们的主要观点是,在比较模型时,报告实现的最小FID是没有意义的。相反,应该比较固定计算预算的FID分布。实际上,本文提供的实证表明,当计算预算增加时,各种最优的GAN的在算法上的差异变得不那么重要。此外,由于预算有限(例如只有一个月的计算时间),“好”算法可能会比“差”算法的表现更好。
基于精确度,召回率和F₁ score的比较。
我们这个简单的三角形数据集使我们能够计算很好理解的精度和召回指标,从而得出F₁ score。我们观察到,即使对于这个看起来很简单的任务,许多模型也很难获得高的F₁得分。在提高F₁ 得分时,NS GAN和WGAN同时有高精度和高召回率。其他的模型,例如DRAGAN和WGAN GP未能达到高召回值。最后,我们观察到在这个任务上可以实现高精度和高召回率(参见附录E)。
与原始GAN的比较。
虽然很多算法都声称优于原始GAN模型,但我们在所有数据集上都没有发现支持这种声称的实验证据。实际上,NS GAN与大多数其他模型的性能相当,在MNIST上达到了最好的总体FID。 而且,它在三角形数据集的F₁得分优于其他模型。
在更彻底地改变编码的情况下,例如使用在不同任务上训练的网络,FID是否稳定还有待检验。另外,FID不能检测训练数据集的过拟合,而只需要记住所有训练样本,算法就能表现得非常好。最后,FID很可能被嵌入网络未检测到的伪像所“欺骗”。
三角形数据集可以通过以下方式变得更加复杂:(i)同时引入多个凸多边形,(ii)在多边形中加上颜色或纹理,以及(iii)逐渐提高分辨率。尽管假如由更多的训练时间和更大的模型容量,现有模型的性能可能会得到提高,但是我们认为,算法改进能够带来更好的性能提升。有了这些更复杂的任务,将会大大有利于研究界。
正如在论文第4章所讨论的那样,在比较不同的模型时,必须考虑多个维度,而这项工作只探讨了一部分选择。我们不能排除在目前尚未探索的条件下某些模型显着优于其他模型的可能性。
最后,这项研究有力地表明,未来的GAN研究应该更注重实验上的系统性,应该在中立的基础上进行模型比较。
论文地址:https://arxiv.org/pdf/1711.10337.pdf
号外:欢迎加入新智元读者群交流讨论,请加微信:aiera2015(备注姓名+学校/企业+研究领域)



