刘群:基于深度学习的自然语言处理,边界在哪里?

来源:AI科技评论

自然语言处理的范式迁移:从规则、统计到深度学习
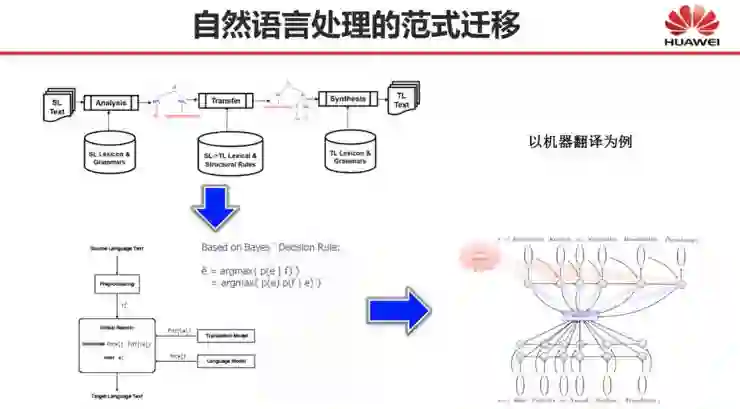
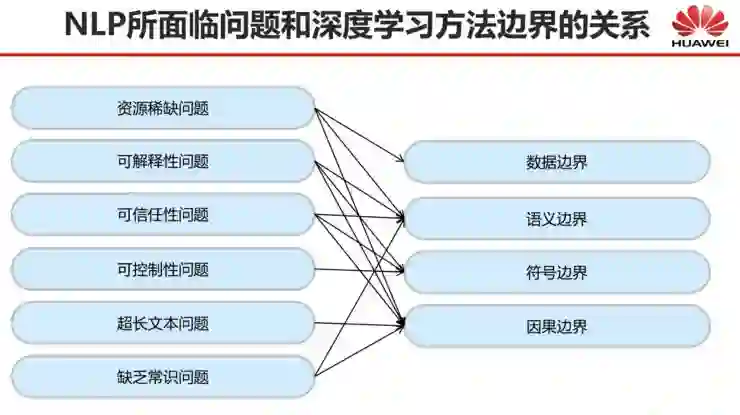
深度学习解决了自然语言处理的哪些问题?
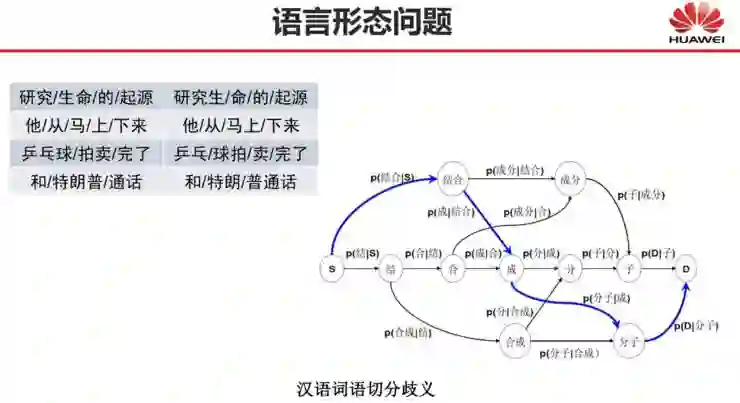
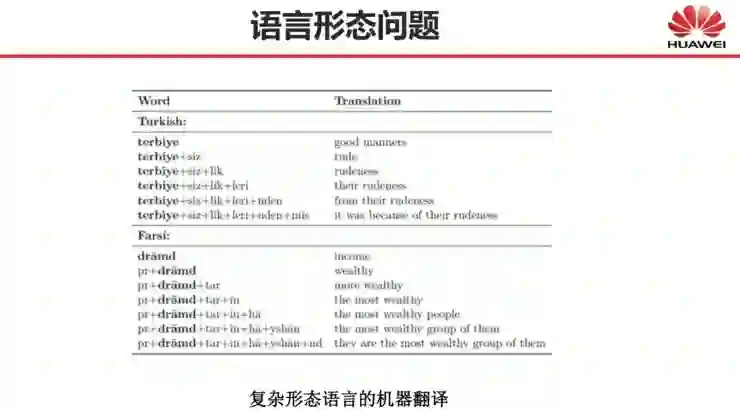


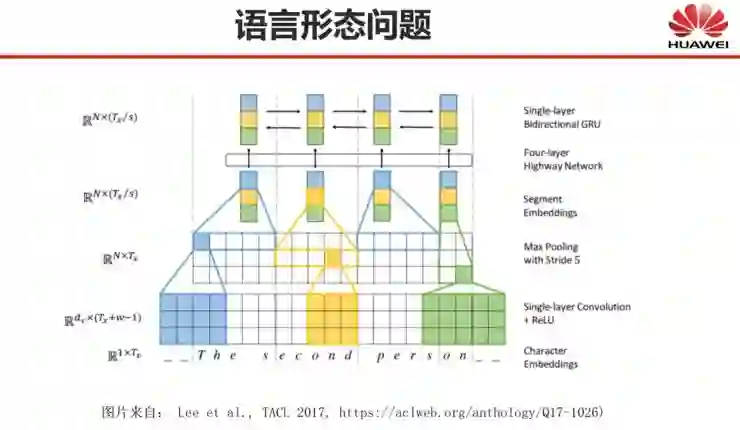
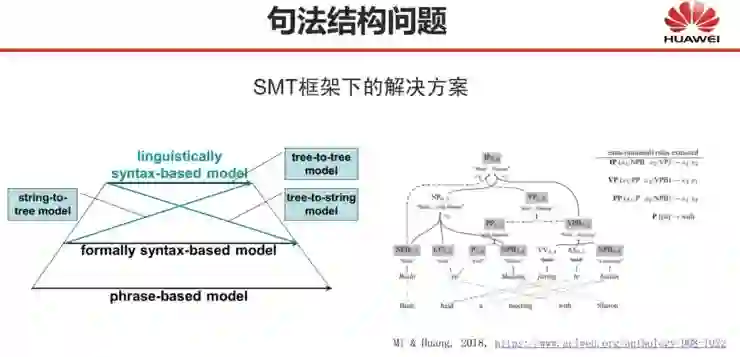

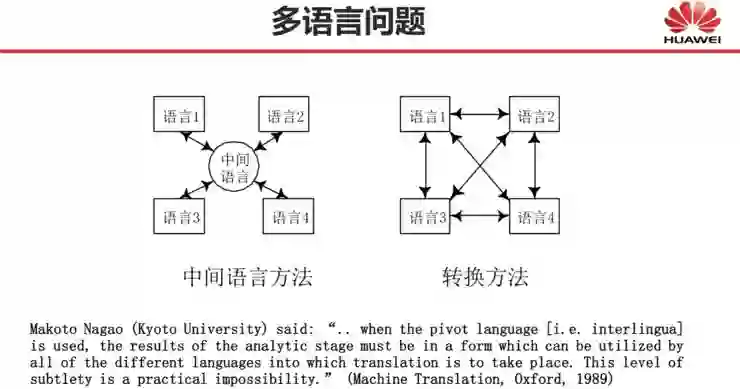
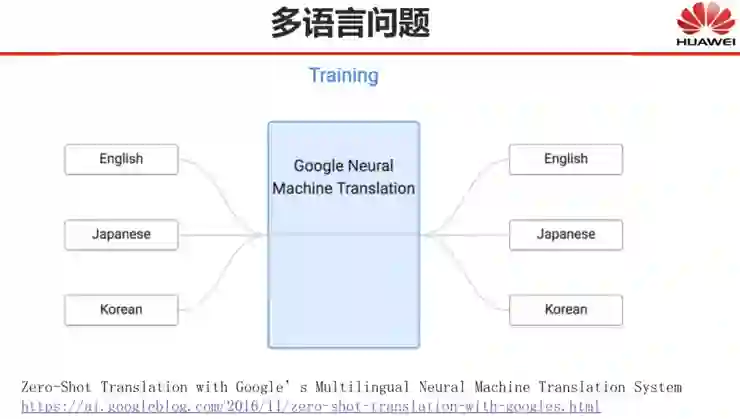

还有哪些自然语言处理问题深度学习尚未解决?
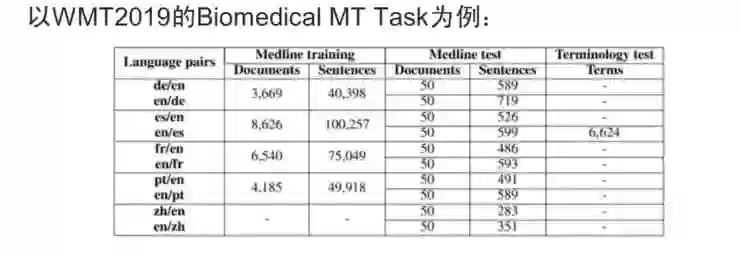
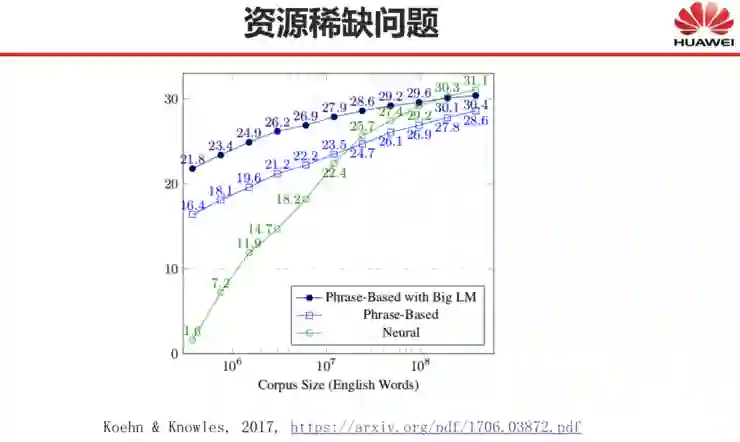
-
一个是基于篇章的机器翻译问题,不光是我们,学术界还有很多同行都在研究这个问题。基于篇章的机器翻译实验证明,对改进翻译质量起作用的上下文只有前1-3个句子,更长的上下文反倒会降低当前句子的翻译质量。按理来说,上下文更长,机器翻译的效果应该是更好的,那为什么反而翻译得更差呢?这是不合理的。 -
另一个是预训练语言模型问题。现在机器翻译的训练长度一般是几百字到上千字,然而实际处理的文本可能不止一千字,比如说一篇八页的英文论文,起码都两三千字了。因此预训练语言模型在实际处理更长文本的时候,还是会遇到很多问题,这种情况下,语言模型消耗计算资源巨大,计算所需时空消耗会随着句子长度呈平方或者三次方增长,所以现有模型要想支持更长的文本,还有很多问题尚待解决。
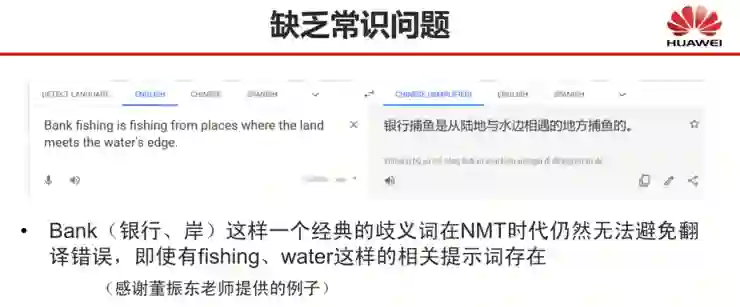

基于深度学习的自然语言处理,其边界在哪里?
附:问答部分
编辑:于腾凯
校对:杨学俊

登录查看更多
相关内容

Arxiv
6+阅读 · 2018年2月20日




相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2018年2月20日