开发 | 谷歌对无监督解耦方法进行了大规模评估,还开源了用来实验的开发库!

AI 科技评论按:如何能够以无监督的方式去理解高维数据,并进一步将这些知识提炼为有用的表示仍然是深度学习中的一个关键难题。该问题的一种解决方法便是解耦表示(disentangled representation),来自谷歌的研究人员不仅深入研究了目前最流行的解耦模型和多个解耦表示数据集,进行了大量实验,还开源了他们的实验库「disentanglement_lib」。此外,与该实验库同时开源的还有一万多个预训练模型与完整的训练测试流程。下面是雷锋网(公众号:雷锋网) AI 科技评论针对这篇博客的部分编译。
解耦模型能够捕捉场景中互相独立的特征,即某种特征不会由于其他特征的改变而受到影响,实现特征之间的解耦。如果能够成功完成特征的解耦表示,现实世界中机器学习系统(如自动驾驶汽车或者机器人)能够将物体的属性与其周围环境分离,从而使得模型能够泛化到其没有见过的场景中。举一个简单的例子,一辆汽车在不同的天气,光线条件或者地理位置等环境中,它的特征应该是不变的,如果一个模型能够将汽车的特征与其背景环境的特征解耦,那么有理由认为,将这个汽车放在一个模型在训练时完全没见到过的环境中时,模型仍然能针对汽车捕捉到不变的特征,这就意味着模型的泛化能力较强。尽管以无监督的方式进行解耦表示学习已经被用于好奇心驱动的探索(curiosity driven exploration)、抽象推理(abstract reasoning)、视觉概念学习 (visual concept learning),以及强化学习中的域适应 (domain adaptation for reinforcement learning) 等领域中,但是目前并没有对比不同方法的有效性和局限性的研究。
在「挑战无监督解耦表示中的常见假设」(Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations,ICML 2019 ) 这篇文章中,谷歌的研究人员对最近的无监督解耦方法进行了大规模评估,对一些常见假设进行了实验验证,同时也对解耦学习的未来工作提出了一些改进建议。这次评估共训练了超过 12,000 个模型,涵盖了大多数主流模型和评价指标,在七个不同数据集上进行可重复的大规模实验。同时,谷歌的研究人员也开源了此次研究中的代码和超过 10,000 个预训练模型。开源的 disentanglement_lib 库能够帮助研究人员轻松地复现和验证他们的实验结果。
论文地址:
https://arxiv.org/abs/1811.12359
「disentanglement_lib」开源库:
https://github.com/google-research/disentanglement_lib
理解解耦
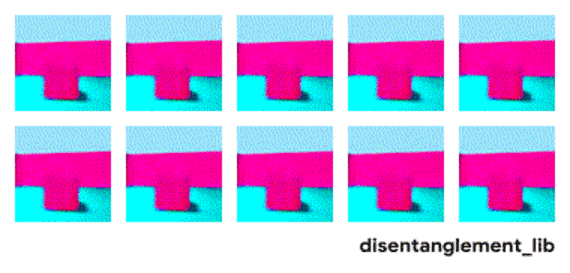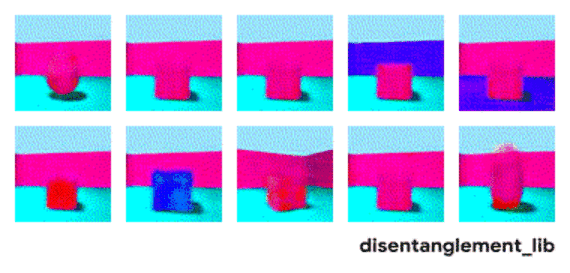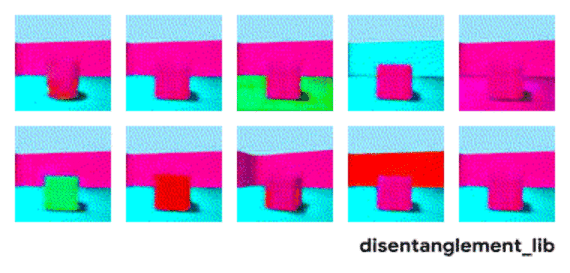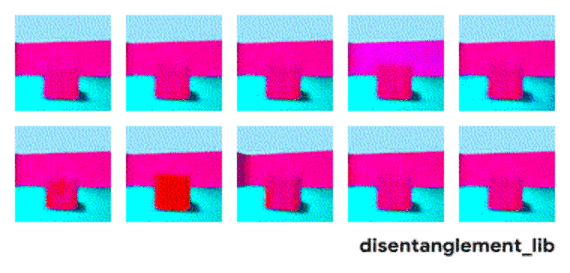
为了更好的理解如何将图像的真实属性以解耦的方式编码为特征,不妨先来看 Shapes3D 数据集中图像的真值因素。在这个数据集里,如下图所示,每一个图代表了可能会被编码进最终图像的表示向量的一个因素,共有六种,分别是地板颜色、墙壁颜色、物体颜色、物体大小、物体形状,以及观察物体的角度。
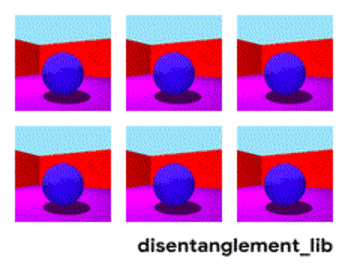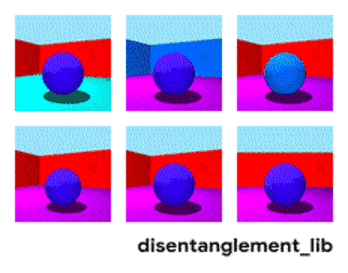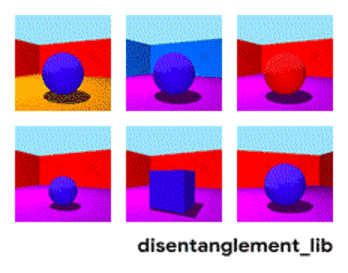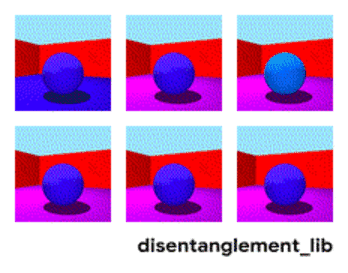
Shapes3D 数据集真值因素的可视化:地板颜色(上左),墙壁颜色(上中)、物体颜色(上右)、物体大小(下左)、物体形状(下中)以及观察物体的角度(下右)。
解耦表示的目标是构建一个能够捕捉这些解释因素并将之编码为一个向量的模型。下图展示了一个具有 10 维表示向量的 FactorVAE 模型的结果。这 10 个图可视化了十维向量每个维度所捕捉到的信息。从第一行的第三到第五张图可以看到,模型成功地解耦了地板和墙壁颜色这一属性,而左下方的两个图表明物体颜色和大小两个属性仍然纠缠在一起。
FactorVAE 模型学到的潜在维度的可视化(见下文)。模型成功地解耦了地板和墙壁颜色以及观察物体的角度这三项真值因素(上右、上正中间以及下正中间),而物体颜色、物体大小、物体形状三项真值因素(上左、下左两张图)则仍旧纠缠在一起。
大规模实验的主要结果
尽管研究界已经提出了各种基于变分自动编码器的无监督方法来学习解耦的表示,同时也设计了很多的度量标准来量化模型解耦的效果的好坏,但并没有大规模的实验研究以统一的标准评估这些方法。因此谷歌的研究者通过六种不同的最先进模型(BetaVAE,AnnealedVAE,FactorVAE,DIP-VAE I/II 和 Beta-TCVAE)和六种解耦评价指标(BetaVAE 评分,FactorVAE 评分,MIG,SAP,Modularity 和 DCI 解耦),提出了一个公平的,可复现的评价基准方案。此次评估,共在 7 个数据集上训练和测试了 128,000 个这样的模型。
此次研究的主要发现包括:
谷歌研究团队没有发现证据表明这些模型能够以无监督的方式,可靠地学习到解耦的表示,由于随机种子和超参数似乎比模型选择更重要。换句话说,研究者即使训练大量的模型,其中一些模型能够学到解耦的特征,这些解耦表示似乎无法在没有真实标签的情况下被识别出来。此外,在此次研究中,良好的超参数值并不适用于不同的数据集。这些结果与论文中提出的定理一致,该定理指出,如果没有数据集和模型的归纳偏差(inductive biases),则无法通过无监督的方式学到解耦的特征(即,必须对数据集做出假设,并融合到模型中去)
鉴于实验中用到的模型和数据集,谷歌研究团队无法验证这种解耦表示是否对下游任务有用,比如利用解耦表示来使用更少的有标注数据进行学习。
下图展示了实验中的一些发现。不同运行中随机种子的选择对解耦评价指标的影响大于模型选择和正则化强度。使用差的超参数但有较好随机种子模型的运行结果可以轻易超过有良好超参数但随机种子模型较差的运行结果。
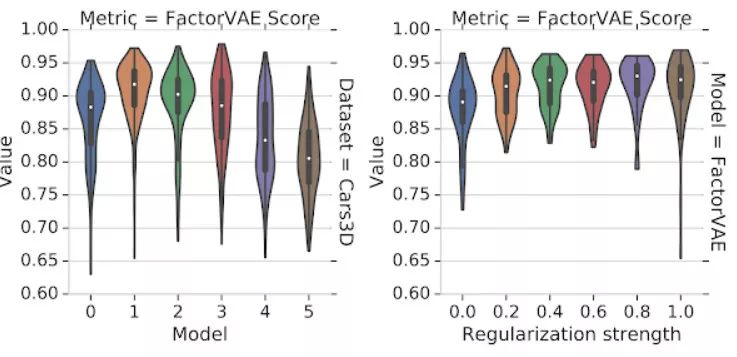
左侧的图展示了不同解耦模型不同模型在 Cars3D 数据集上的 FactorVAE 分数分布。右侧的图展示了 FactorVAE 模型在不同正则化强度下的分数分布。主要的结论为这些提琴图有很大程度的交叉,即所有的模型都很依赖于随机种子的选择。
基于这些观察结果,谷歌的研究者提出了四个与未来研究相关的建议:
由于无归纳偏差的无监督解耦特征学习是不可能的,未来的工作应该更清楚地描述所加入的归纳偏差,以及加入隐性或显性监督的作用。
如何找到适用于多个数据集和无监督模型的归纳偏差仍是一个重要问题。
需要展示出学习到解耦特征的具象化的实际好处。比较可行的方向包括机器人技术、抽象推理 (abstract reasoning) 和公平性分析 (fairness)。
需要在更多数据集上设计可复现的实验。
开源的 disentanglement_lib
为了能够让其他人验证此次实验的结果,谷歌研究团队还开源了用来进行实验的开发库:disentanglement_lib。它包含了上述涉及到的解耦方法、评价指标的开源实现、标准化训练测试流程以及更好理解模型的可视化工具。
disentanglement_lib 有三个方面的优点:
首先,只需不到四个 shell 命令,disentanglement_lib 即可复现上述研究的任何模型。
其次,研究人员可以很容易的基于此研究进行修改,来验证其他假设。
第三,disentanglement_lib 易于拓展,是一个好的入门解耦表示的方法,同时能够很容易的使用这个库来实现新模型,并将之与其他模型进行比较。
从头训练此次研究中的所有模型需要大概 2.5GPU 年的时间,对于一般研究者来说这可能是不现实的,因此谷歌同时开源了超过 10,000 个预训练模型,可以与 disentanglement_lib 一起使用。
disentanglement_lib 允许其他研究人员将他们的新模型与的预训练模型进行对比,并在各种模型上测试新的解耦度量标准和可视化方法,有望能够推动该领域进一步向前发展。
via:
https://ai.googleblog.com/2019/04/evaluating-unsupervised-learning-of.html

点击阅读原文,查看谷歌其他相关文章



