EMNLP2019奖项出炉:华人一作获最佳论文,导师是NLP大神

新智元报道
新智元报道
编辑:肖琴
【新智元导读】自然语言处理顶会EMNLP 2019昨天在中国香港闭幕,最佳论文也重磅出炉!今年虽然中国人投稿论文和录取论文都很多,然而基本无缘奖项。最佳论文一作是约翰霍普金斯大学的华人学生,她的导师Jason Eisner是NLP界大神级人物。来新智元 AI 朋友圈获取4篇获奖论文下载地址~
自然语言处理顶会EMNLP 2019 的最佳论文重磅出炉了!
EMNLP-IJCNLP 2019 于11月3日到7日联合在中国香港举办,在昨晚的闭幕式上,颁发了本年度的最佳论文奖项。
今年共有四个奖项,分别是最佳论文奖、最佳论文提名奖、最佳资源奖和最佳Demo奖。
其中,最佳论文一作是约翰霍普金斯大学的华人学生Xiang Lisa Li,以及她的导师Jason Eisner。Jason Eisner是NLP界大神级人物,在语言结构的概率模型和算法方面做出了许多重要贡献。
最佳论文提名奖获奖者来自斯坦福大学,最佳资源奖由Facebook、索邦大学和约翰霍普金斯大学的联合团队摘得,最佳Demo奖获得者来自艾伦人工智能研究所和加州大学欧文分校。遗憾的是,虽然中国投稿论文最多、也不乏录取为Oral、Poster的论文,但国内师生基本无缘奖项。
获奖论文分别是:
最佳论文奖:Specializing Word Embeddings (for Parsing) by Information Bottleneck
作者:Xiang Lisa Li,Jason Eisner (约翰霍普金斯大学)
最佳论文提名奖:Designing and Interpreting Probes with Control Tasks
作者:John Hewitt,Percy Liang(斯坦福大学)
最佳资源奖:Two New Evaluation Datasets for Low-Resource Machine Translation: Nepali-English and Sinhala-English
作者:Francisco Guzmán, Peng-Jen Chen, Myle Ott, Juan Pino, Guillaume Lample, Philipp Koehn, Vishrav Chaudhary, Marc'Aurelio Ranzato
作者机构:Facebook AI Research、索邦大学、约翰霍普金斯大学
最佳Demo奖:AllenNLP Interpret: A Framework for Explaining Predictions of NLP Models
作者:Eric Wallace, Jens Tuyls, Junlin Wang, Sanjay Subramanian, Matt Gardner, Sameer Singh
作者机构:艾伦人工智能研究所、加州大学欧文分校
打开新智元小程序,点击“进入空间站”,可获取4篇EMNLP获奖论文PDF:
在介绍最佳论文前,让我们回顾一下今年EMNLP的相关数据:今年提交论文2914篇,比2018年的EMNLP增加了约30%,使EMNLP-IJCNLP 2019成为有史以来最大规模的NLP会议。
有38篇论文因为各种原因被拒,因此最终评审的论文是2876篇,录取论文683篇,录取率为23.7%。其中,录取为Oral论文的有212篇。

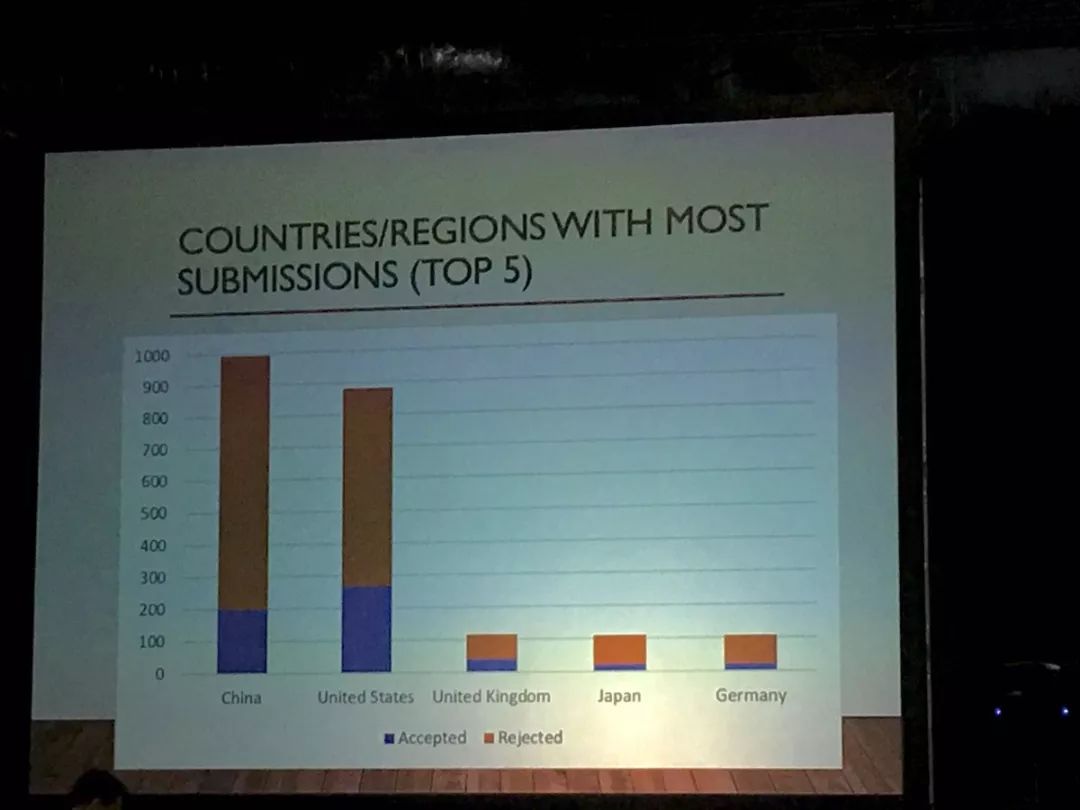
下图是提交论文最多的5个国家/地区,中国提交的论文最多,接近1000篇,其次是美国,但美国被录取的论文更多。
录取论文的分数区间如下图所示:

会上同时也公布了未来几个NLP重要的举办城市:
ACL 2021将在泰国曼谷举办
EMNLP 2020将在多米尼加共和国的普塔卡纳举办。
COLING 2020:西班牙巴塞罗那
AACL 2020:中国苏州
ACL 2020:美国西雅图
华人一作摘获最佳论文:变分信息瓶颈的新颖应用和理论证明
最佳论文奖:Specializing Word Embeddings (for Parsing) by Information Bottleneck
作者:Xiang Lisa Li,Jason Eisner (约翰霍普金斯大学)

摘要:
ELMo和BERT这类的预训练词嵌入包含了丰富的语法和语义信息,从而在各种任务中获得最先进的性能。
我们提出一种非常快速的变分信息瓶颈(variational information bottleneck, VIB)方法来对这些嵌入进行非线性压缩,只保留有助于判别解析器的信息。我们将嵌入词压缩为离散标签或连续向量。
在离散标签版本中,我们的自动压缩标签形成了一个备选标签集:我们通过实验证明,这些标签可以捕获传统POS标签注释中的大部分信息,但是在相同的标签粒度级别上,我们的标签序列能够被更准确地解析。
在连续向量版本中,我们通过实验证明,通过我们的方法适当地压缩词嵌入,可以在9种语言中的8种语言中生成更精确的解析器,而不像简单的降维那样。
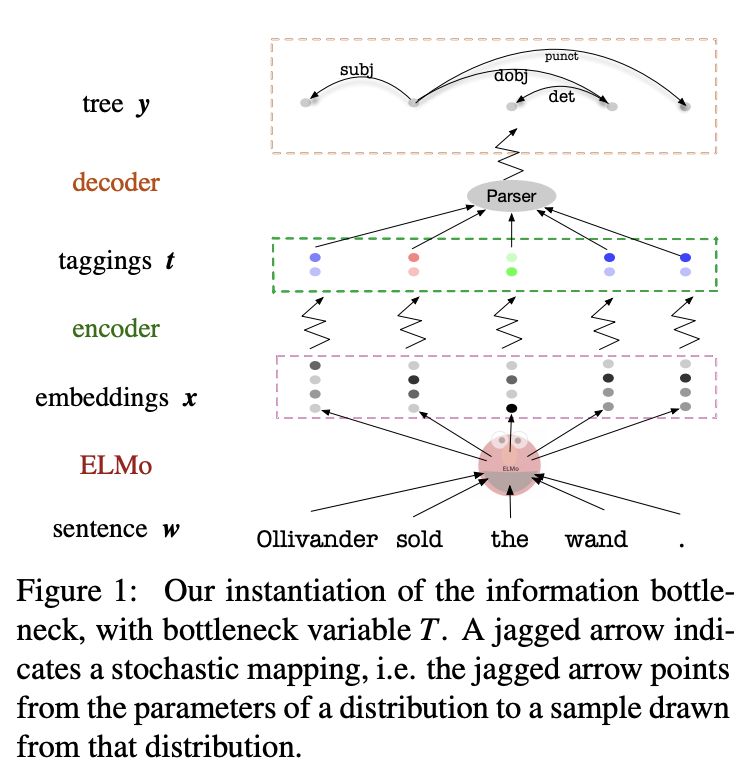
我们用瓶颈变量t来实例化信息瓶颈。锯齿形箭头表示一个随机映射,即锯齿形箭头从一个分布的参数指向从该分布抽取的样本。
最佳论文提名奖:Designing and Interpreting Probes with Control Tasks
作者:John Hewitt,Percy Liang(斯坦福大学)

“探针”(Probes)是一类监督模型,用于从表示(如ELMo)中预测属性(如词性),它们在一系列语言任务中取得了很高的准确性。但这是否意味着表示对语言结构进行了编码,还是仅仅意味着探针模型已经学会了语言任务?
在这篇论文中,我们提出控制任务(control tasks),即把单词类型和随机输出联系起来,从而对语言任务进行补充。这些任务只能通过探针本身来学习。因此,一个好的探针应该是有选择性的,能够实现较高的语言任务准确性和较低的控制任务准确性。探针的选择性将语言任务的准确性与探针记忆单词类型的能力联系起来。
我们构造了英文词性标注和依赖项边缘预测的控制任务,并证明了常用的ELMo表示的探针是没有选择性的。我们还发现,通常用于控制探针复杂度的dropout对提高MLP的选择性无效,但其他形式的正则化是有效的。最后,我们发现在ELMo的第一层上的探针比第二层上的探针产生的词性标记精度稍好一些,而在第二层上的探测具有更强的选择性,这就提出了一个问题,即哪个层能更好地表示词性。
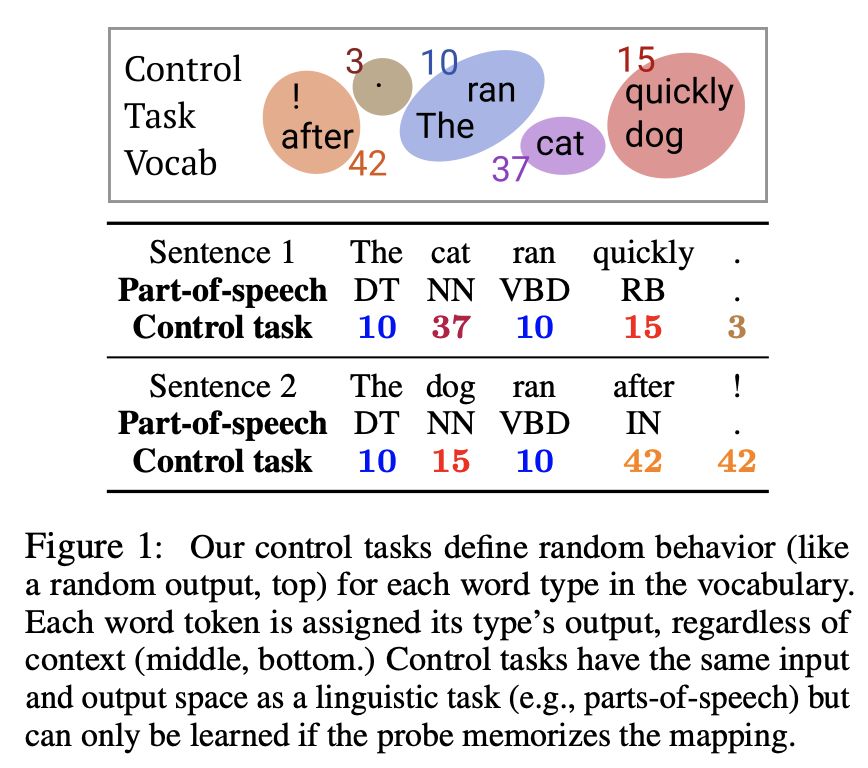
控制任务为词汇表中的每个单词类型定义随机行为(如随机输出)。无论上下文如何,每个单词标记都被分配其类型的输出。控制任务与语言任务(例如,词性任务)具有相同的输入和输出空间,但是只在探针记住映射时才能学习。
最佳资源奖:Two New Evaluation Datasets for Low-Resource Machine Translation: Nepali-English and Sinhala-English
作者:Francisco Guzmán, Peng-Jen Chen, Myle Ott, Juan Pino, Guillaume Lample, Philipp Koehn, Vishrav Chaudhary, Marc'Aurelio Ranzato
作者机构:Facebook AI Research、索邦大学、约翰霍普金斯大学

对于机器翻译,世界上绝大多数语言对都是低资源的,因为它们几乎没有可用的并行数据。除了在有限的监督下学习这一技术挑战之外,由于缺乏自由和公开的基准,很难评估在低资源语言对上训练的方法。
在这项工作中,我们基于从维基百科翻译的句子,提出了尼泊尔语-英语和僧伽罗语-英语的FLORES评估数据集。与英语相比,这些语言具有非常不同的形态和语法,而且很少有领域外的并行数据可用。
我们描述了收集和交叉检查翻译质量的过程,并使用几种学习设置报告了基准性能:完全监督、弱监督、半监督和完全无监督。我们的实验表明,目前最先进的方法在这个基准上表现相当差,这对研究低资源机器翻译的社区提出了挑战。
实验的数据和代码已经在GitHub公布:
https://github. com/facebookresearch/flores.
最佳Demo奖:AllenNLP Interpret: A Framework for Explaining Predictions of NLP Models
作者:Eric Wallace, Jens Tuyls, Junlin Wang, Sanjay Subramanian, Matt Gardner, Sameer Singh
作者机构:艾伦人工智能研究所、加州大学欧文分校

摘要:
Neural NLP模型越来越精确,但并不完美,而且不透明——它们的方式是反直觉的,让最终用户对它们的行为感到困惑。模型解释方法通过为特定的模型预测提供解释来改善这种不透明性。遗憾的是,现有的解释代码库很难将这些方法应用到新的模型和任务中,这阻碍了从业者采用这些方法,并给可解释性研究人员带来了负担。
我们提出了一个用于解释NLP模型的灵活框架——AllenNLP Interpret。该工具包能为任何AllenNLP模型和任务提供了解释原语(例如,输入梯度)、一套内置的解释方法和一个前端可视化组件库。
我们通过在各种模型和任务上演示了五种解释方法(例如,显著性映射和对抗性攻击),展示了该工具包的灵活性和实用性。
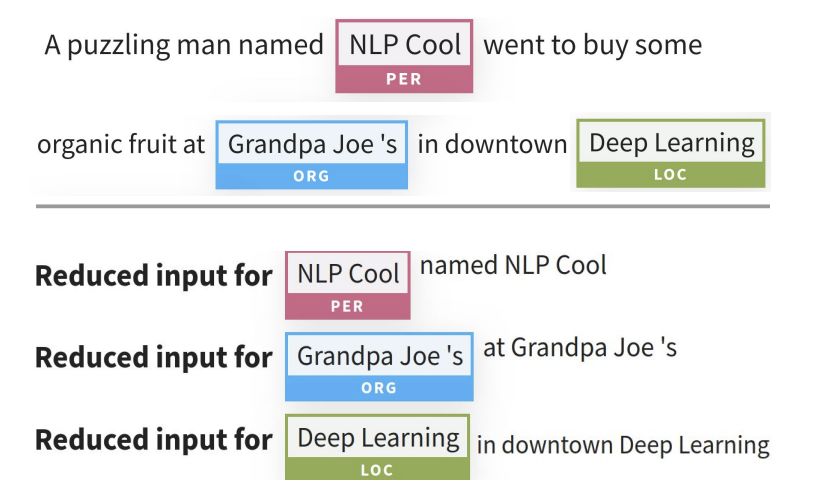
使用AllenNLP Interpret为NER生成的解释。该模型为一个输入(顶部)预测三个标签,我们分别解释每个标签。
这些demo,以及代码和教程,都已经在GitHub上开源:
https://allennlp. org/interpret.






