【DeepMind最新论文】新AlphaZero出世称霸棋界 ,8小时搞定一切棋类!自对弈通用强化学习无师自通!
点击上方“专知”关注获取专业AI知识!

【导读】从AlphoGo Zero 到AlphaZero只是少了一个词“围棋”(Go), 但是背后却代表着Hassabis将和他的DeepMind继续朝着“创造解决世界上一切问题的通用人工智能”这一目标道路上迈出了巨大的一步。今天DeepMind在arXiv发表论文表示其开发的通用强化学习程序AlphaZero,使用蒙特卡洛树搜索(MCTS)和深度神经网络,和强大的算力,同时在国际象棋,日本将棋和围棋中战胜各自领域的最强代表。而且这一切都是通过自我对弈完成的,在训练中除了游戏规则,不提供任何额外的领域知识。
DeepMind CEO, Demis Hassabis曾表示Deepmind的实名就是“破解智能难题,然后用其来解决一切问题”的使命而奋斗时又格外认真。其他任何人说出这句话,听起来都十分可笑,但这句话从他的口中说出就另当别论了。39岁的Hassabis是一位前国际象棋大师、游戏设计员,他的人工智能研究创业公司DeepMind在2014年被谷歌以6.25亿美元收购。
▌论文简介
Mastering Chess and Shogi by Self-Play with a GeneralReinforcement Learning Algorithm

摘要:国际象棋是人工智能史上研究最广泛的项目。目前最强大的国际象棋程序都是基于多种策略的组合,比如复杂的搜索技术,对特定领域的改进和人类专家几十年来人工不断完善的评估函数。相比之下,AlphaGo Zero仅仅使用一无所知的(tabula rasa)强化学习进行游戏的自我对弈,就在最近的围棋游戏中实现了超过人类水平的表现 。
在本文中,我们将这种方法推广到一个单一的AlphaZero算法中,该算法可以从一张白纸开始(译注:无需先验知识,比如历史的对弈记录)在许多具有挑战性的领域实现人类能力所不能及的性能。从随机玩游戏开始,除了游戏规则,不提供任何额外的领域知识,AlphaZero在24小时内实现了在象棋和日本将棋以及围棋中的超人类水平,并且令人信服地击败了每种游戏中的世界冠军。
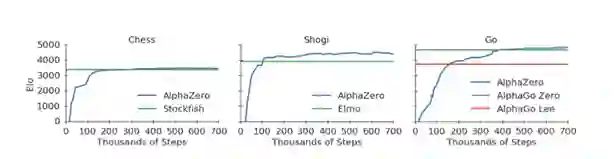
图1:AlphaZero训练过程的700000次迭代。(a)在国际象棋中与2016年TCEC世界冠军程序Stockfish相比,评估AlphaZero的性能。(b)在将棋(日本象棋)中与2017年CSA世界冠军程序Elmo相比,评估AlphaZero的性能。(c)在Go(围棋)中与AlphaGo Lee和AlphaGo Zero(三天20个block)(29)相比,评估AlphaZero的性能。
从图中可以看出AlphaZero从零开始训练
4小时(300k步)就打败了国际象棋的最强程序Stockfish
2小时(110k steps)就打败了日本将棋的最强程序Elmo!
8小时(165k steps))就打败了与李世石对战的AlphaGo Lee!
随着训练的继续深入,我们可以看到它面对Stockfish保持不败。而且最终比之前的AlphaGo Zero也更为强大。
目前最强大的国际象棋程序都是基于多种策略的组合,比如复杂的搜索技术,对特定领域的改进和人类专家几十年来人工不断完善的评估函数。相比之下,AlphaGo Zero和AlphaZero仅仅使用强化学习进行游戏的自我对弈,得到了非常好的效果。
AlphaZero的核心思想是建立一个神经网络来同时输出策略(policy,在给定盘面下下一步该怎么走)和价值(value,给定盘面的期望赢率),将策略(policy)和价值(value)结合到一个单一的网络中,训练时候通过蒙特卡洛树搜索进行自我训练获取策略目标π和最终价值目标z,然后通过随机梯度下降优化损失函数来进行学习。
这次注意的一点是AlphaZero使用通用的蒙特卡洛树搜索(MCTS)算法,而不是使用特定领域的alpha-beta搜索,AlphaZero完全从自我对弈中学习这些移动概率和数值估计。
当然,其训练AlphaZero需要海量的计算资源,文中说产生自我学习棋谱的时候用了5000块第一代TPU,训练神经网络的时候用了64块第二代TPU。
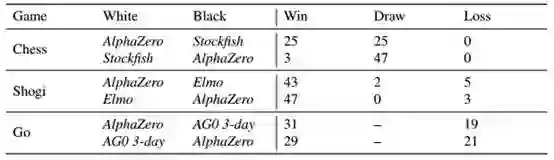
表1:国际象棋,将棋和围棋比赛中AlphaZero的评估,经过三天的训练,与Stockfish,Elmo和之前发布的AlphaGo Zero进行100场比赛,表中显示的是以AlphaZero视角的结果结果。
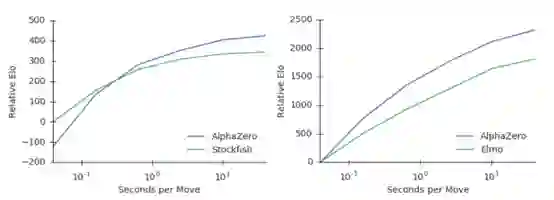
图2:用Elo评估AlphaZero每步的思考时间的可扩展性。(a)展示了在国际象棋中AlphaZero和Stockfish的表现,每一步的思考时间。(b)展示了在将棋中AlphaZero和Elmo的表现,每一步的思考时间。
文中提到了AlphaZero每秒评估的棋位比Stockfish少很多,如图2所示,聚焦于更有希望的棋位,在每一步思考时间较长的时候,AlphaZero的分析更精准。
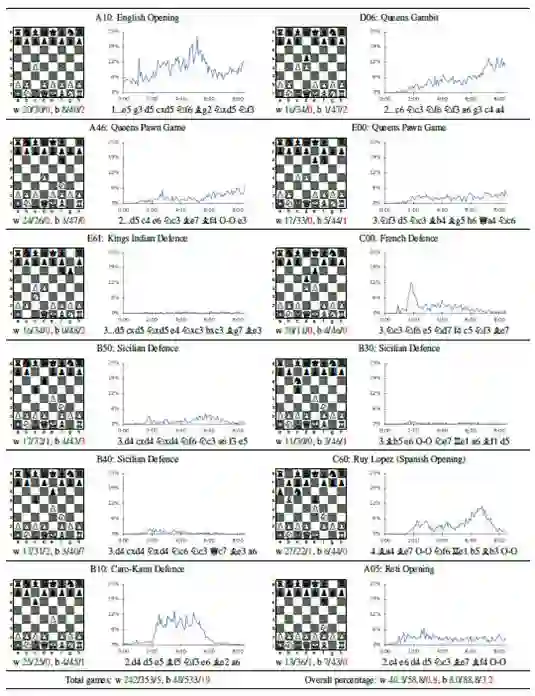
表2:分析12个最受欢迎的人类开局(在线数据库(1)中播放超过10万次)。每个开局都标有其ECO代码和通用名称。该图显示了AlphaZero每次开局自我对弈比赛和训练时间的比例。我们还从AlphaZero的角度报告了从每场比赛开局的100场比赛AlphaZero vs. Breakish比赛的胜负/平局/失败结果,无论是白色(W)还是黑色(B)。最后,从每个开局提供AlphaZero的主要变化(PV)
▌Twitter点评
Olimpiu G. Urcan表示:人类用了1500年建立起来的智慧结晶,AlphaZero只用了24小时就给打破了
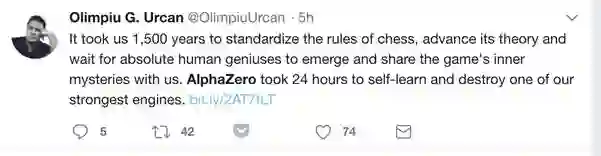
著名科技博客wildml.com博主,同时也是前谷歌大脑成员Denny Britz却对此保持谨慎态度。他表示:准确来说,没有“先验知识”并不完全准确。新算法中输入的特征以及网络的结构的建立都是需要领域知识的。并不清楚AlphaZero是怎么泛化到看起来完全不同的领域的,但是其中MCTS确实是一种基于泛化目的的设计,作者本人也承认这一点。
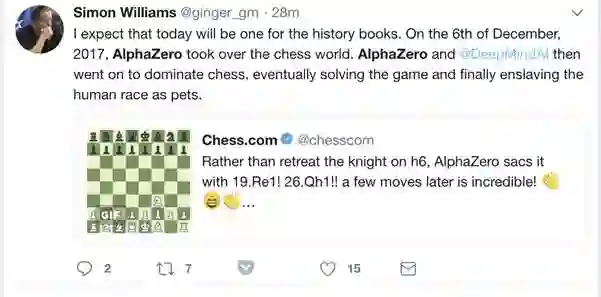
Simon 表示:希望这一天会被载入史册。在2017年12月6日,AlphaZero统治了象棋届。
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域25个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!



