微服务依赖管理的陷阱与模式

去年,在 QCon Plus 期间,我分享了我在谷歌工作的 10 多年里遇到的一些 微服务依赖管理中的陷阱和模式。这次演讲不是为了介绍任何特定产品或团队,而是为了分享我自己作为谷歌软件工程师的经验和个人学习成果。
我是基于上述前提登台演讲的。这些场景都有一些关键的顿悟时刻,通过这些瞬间我意识到了微服务环境中的许多方面是何等重要。也有不少遭遇失败或出错的时刻。我精心挑选出了这些故障场景,并告诉大家我做了哪些事情来避免将来发生类似的情况,这样你就可以在你自己的环境中找出可能导致类似故障的迹象。
所有这些场景中我都在与其他工程角色协作。有时我是一名软件工程师,与某位项目经理共事。还有些时候,我是一名站点可靠性工程师,与其他开发人员协作。在最后一个场景中,我基本上在和团队中的所有人配合,目标是构建可靠的服务。
这些场景都对团队中的各种角色大有助益:能否成功构建可靠的微服务环境,不仅取决于某个人或某个单一角色。
每次更改系统时,更改都会影响整个产品的许多部分和组件——这些组件可能是由你的公司、在云中或由第三方提供商运营的。系统更改会产生连锁反应,一直影响到客户一侧:客户恰恰是你每时每刻都要考虑的群体。出于这个原因,你需要从整体的角度来看待系统——这也是我在演讲中试图传达的一部分内容。
在介绍这些场景(以及所有可以从它们中学到的东西)之前,让我们快速了解一下行业是如何从单体服务过渡到微服务,然后再迈出最后一步将服务上云的。我们还将研究各种模式和流量增长、故障隔离,以及如何在每个后端都有不同提示的世界中规划合理的服务级别目标(SLO)。
我们的旅程(这里我们会使用一个通用服务)从一个二进制文件开始,它最终(且迅速)会演变为包括众多复杂功能的文件,例如数据库、用户身份验证、流量控制、运维监控和 HTTP API(这样我们的客户就可以在线找到我们)。起初,这个单一的二进制文件只打算运行在一台机器上,但随着业务的增长,我们有必要在多个地理位置复制这个二进制文件,同时为流量增长留出额外的空间。
在复制我们的单体之后不久,有几个原因要求我们将它们解耦为一些单独的二进制文件。或许你可以想到其中一些因素。一个常见的原因与二进制文件的复杂性有关。随着我们向其添加愈加复杂的功能,代码库变得几乎无法维护(更不用说添加其他新功能了)。将单体分解成许多单独的二进制文件的另一个常见原因事关独立逻辑组件的独特需求。例如,我们可能有必要为特定组件增加硬件资源,而不影响其他组件的性能。
像这样的场景最终促成了 微服务 的诞生:微服务是一组松散耦合的服务,这些服务可独立部署、高度可维护并组织起来形成(或服务)一个复杂的应用程序。在实践中,这意味着我们会部署多个二进制文件并通过网络让它们通信,其中每个二进制文件都实现了自己的微服务,但它们都服务于并代表单一的一个产品。图 1 展示了一个 API 产品的示例,该产品解耦为五个独立的微服务(API、Auth、Control、Data 和 Ops),这些微服务通过网络相互通信。在微服务架构中,网络也是产品的重要组成部分,因此你必须始终牢记这一点。每个服务——现在既是单个二进制文件又是应用程序的一个组件——可以独立增加硬件资源,并且工程团队可以轻松控制其生命周期。
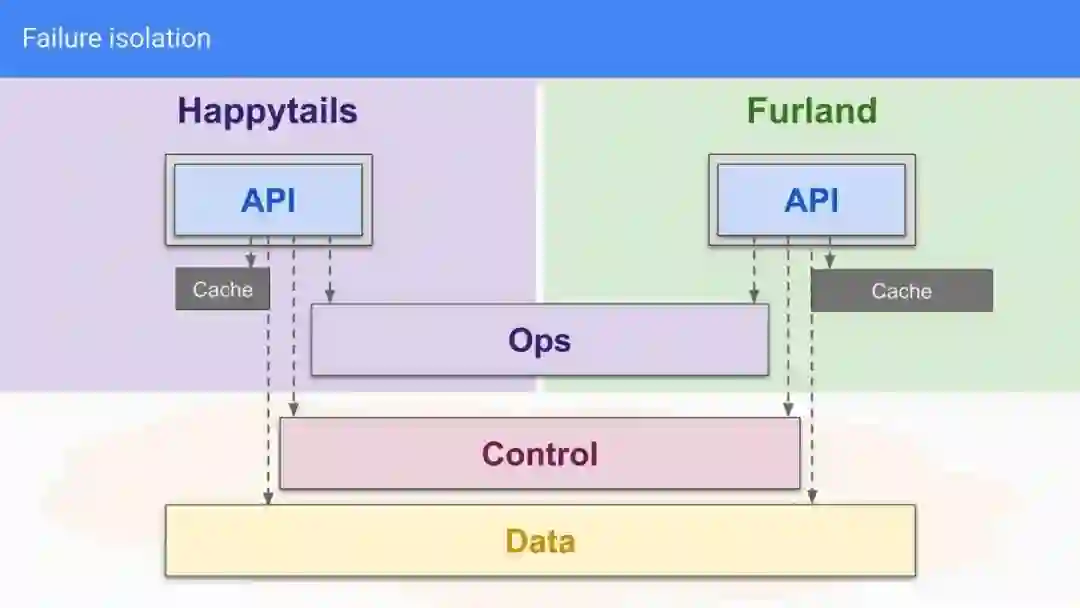
一个 API 产品解耦为五个独立的微服务
在微服务架构中运行产品提供了一系列好处。总体而言,因为产品所有者可以在不同位置部署松散耦合的二进制文件,所以他们能够在具有成本效益和高可用性的部署方案中做出选择,在云中或在他们自己的机器中托管每项服务。它还允许独立的垂直或水平扩展:增加每个组件的硬件资源,或复制允许使用不同独立区域的组件。
另一个好处与开发生命周期有关。由于每个服务在逻辑上都与其他服务分离,并且内部复杂性较低,因此开发人员更容易推理其实现中的更改,并保证新功能具有可预测的结果。这也意味着每个组件都能做到独立开发,允许开发人员在不干扰其他服务的情况下对一个或多个服务进行本地更改。发布可以独立推进或回滚,从而带来对中断的更快反应速度和更专注于核心的生产更改。
尽管有那么多优点,但基于微服务的架构也可能会让某些流程处理起来更加困难。在接下来的部分中,我将展示我之前提到的一些场景(虽然我改动了一些其中涉及的真实姓名)。我将详细介绍每个场景,包括一些与管理微服务相关的令人难忘的痛点,例如调整前端和后端之间的流量和资源增长需求。我还将讨论如何设计故障域,以及如何基于所有微服务的组合 SLO 计算产品 SLO。最后,我将分享一些有用的技巧,希望这些技巧可以帮助节省你的时间并预防最终的客户中断。
我们的第一个场景围绕一个名为 PetPic 的虚构产品展开。如图 2 所示,PetPic 是一项全局服务,可为两处地理区域(Happytails 和 Furland)的狗狗爱好者提供狗的照片。该服务目前在每个地区都有 100 个客户,总共有 200 个客户。前端 API 运行在独立的机器上,每台机器都位于其中一个区域。作为一个复杂的服务,PetPic 有多个组件,但在第一次研究中我们将只考虑其中一个组件:数据库后端。该数据库运行在云端的一个全局区域中,并为 Happytails 和 Furland 两个区域提供服务。
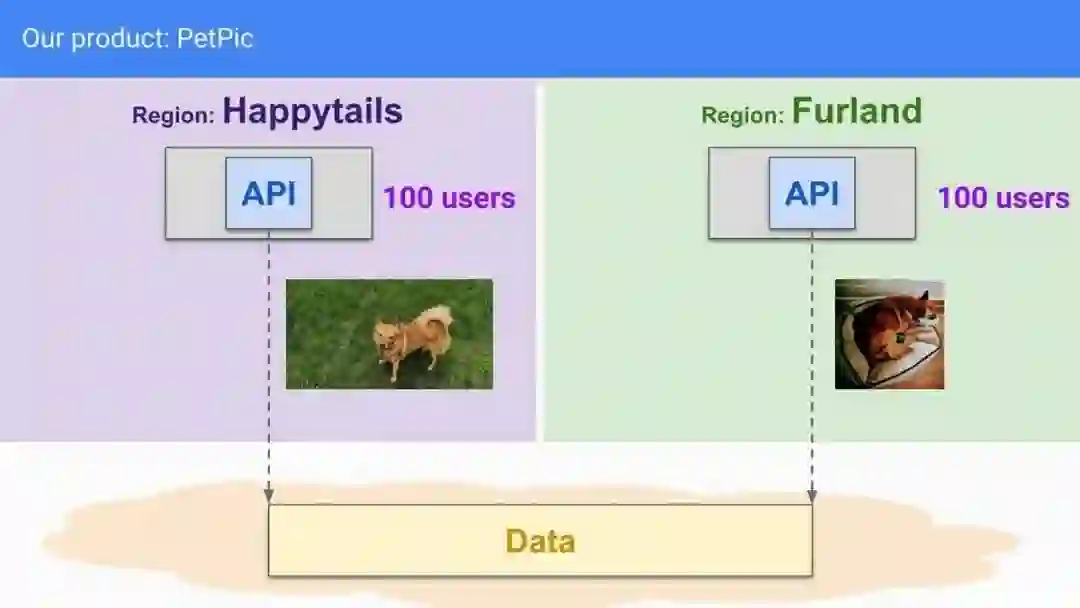
全局 PetPic 服务
目前该数据库在高峰时使用了其所有资源的 50%。考虑到这一点,产品负责人决定在 PetPic 中实现一项新特性,让它也可以向客户提供猫的照片。新特性实现后,工程师决定首先在 Happytails 区域推出这项特性。这样,他们可以在向所有人提供新特性之前找出意外的热情用户流量或资源使用变化。考虑到两个地区的用户基数相同,这在当时似乎是一个非常合理的策略。
为准备上线,工程师将 Happytails 中 API 服务的处理资源增加了一倍,数据库资源增加了 10%。上线很成功。客户增长了 10%,这可能表明一些爱猫人士加入了 PetPic。数据库资源利用率在峰值时为 50%,再次表明额外资源确实是必要的。
所有信号都表明用户增长 10% 需要数据库资源也增长 10%。为了准备在 Furland 区域推出新特性,PetPic 工程师向数据库中添加了 10% 的额外资源。他们还将 Furland 的 API 资源增加了一倍,以应对新客户的需求。这些更改与在 Happytails 推出新功特性时所做的完全相同。
他们在周三为 Furland 用户推出了这项新特性。然后,在午餐时间,工程师开始收到大量警报,报告用户了服务返回 HTTP 500 错误代码——这意味着用户无法使用该服务了。这与 Happytails 的上线经历完全两回事。此时,数据库团队联系到工程部,提到数据库资源利用率在两小时前(上线后不久)就达到了 80%。他们试图分配更多的 CPU 来处理额外的流量,但这一更改在今天之内不太可能实现。同时,API 团队检查了用户增长图,并报告没有出现与预期不同的变化:该服务现在共有 220 个客户。由于工程团队中没有人能找出任何明显的中断原因,他们决定中止发布并在 Furland 中回滚该特性。

流量增长的意外影响
在 Happytails 中推出的特性带来的 10% 的客户增长与 10% 的数据库流量增长相一致。然而,在分析日志后工程团队发现,在 Furland 推出该特性后,即使没有一个新用户注册,数据库的流量也增长了 60%。回滚后,急于在午休时间看到猫猫照片的不满客户们开了几张客户支持票。工程师们总算了解到,Furland 的客户实际上多为爱猫人士,当只有狗狗图片能看时,他们没什么兴趣与 PetPic 互动。
上面的场景告诉我们,猫图片特性在吸引 Furland 的现有客户方面取得了巨大成功,但新特性的部署策略完全没能预料到会取得如此大的成功。这里的一个重要教训是,每种产品都会经历不同类型的增长过程。正如我们在这个场景中看到的,客户数量的增长与现有客户参与度的增长是不一样的——不同类型的增长并不总是相互关联。处理用户请求所需的硬件资源可能因用户行为而异,用户行为也可能因许多因素(包括地理区域)而异。
在准备在不同地区推出产品时,最好在所有地区进行特性实验,以更全面地了解新特性将如何影响用户行为(以及资源利用率)。此外,每当新发布需要额外的硬件资源时,明智的做法是让后端所有者有更多时间来动手分配这些资源。分配新机器需要采购订单、运输过程和硬件的物理安装过程。发布策略需要考虑到这部分额外时间。
从架构的角度来看,我们刚刚研究的这个场景涉及了一项在运行中成为单点故障的全局服务,以及一次导致两个区域中断的本地部署。在单体应用的世界中,跨组件隔离故障是非常困难,甚至无法做到的。这种困难的主要原因是所有逻辑组件共存于同一个二进制文件中,因此它们也会处于同一个执行环境中。使用微服务的一个巨大优势是我们可以允许独立的逻辑组件孤立地发生故障,防止故障在整个系统中广泛传播并危及其他组件。分析服务如何共同失败的设计过程通常称为故障隔离。
在我们的示例中,PetPic 独立部署在两个不同的区域:Happytails 和 Furland。但是,这些区域的性能表现与为这两个区域提供服务的全局数据库的性能密切相关。正如我们目前所观察到的,Happytails 和 Furland 的客户有着截然不同的兴趣,因此很难调整数据库来高效地为这两个地区提供服务。Furland 客户访问数据库方式的变化可能让 Happytail 用户遇到糟糕的用户体验,反之亦然。
有一些方法可以避免此类问题,例如使用有界本地缓存,如图 4 所示。本地缓存可以带来增强的用户体验,因为它还可以减少响应延迟和数据库资源使用。缓存大小可以适应本地流量而不是全局利用率。它还可以在后端中断的情况下提供保存的数据,从而实现服务的优雅降级。
缓存也可能会带来特定于应用程序或业务需求的问题——例如你有很高的数据新鲜度或扩展需求时。常见问题包括由于资源限制和查询各种缓存时的一致性导致缓存延迟缓慢增加。此外,服务不应该依赖缓存的内容来提供服务。
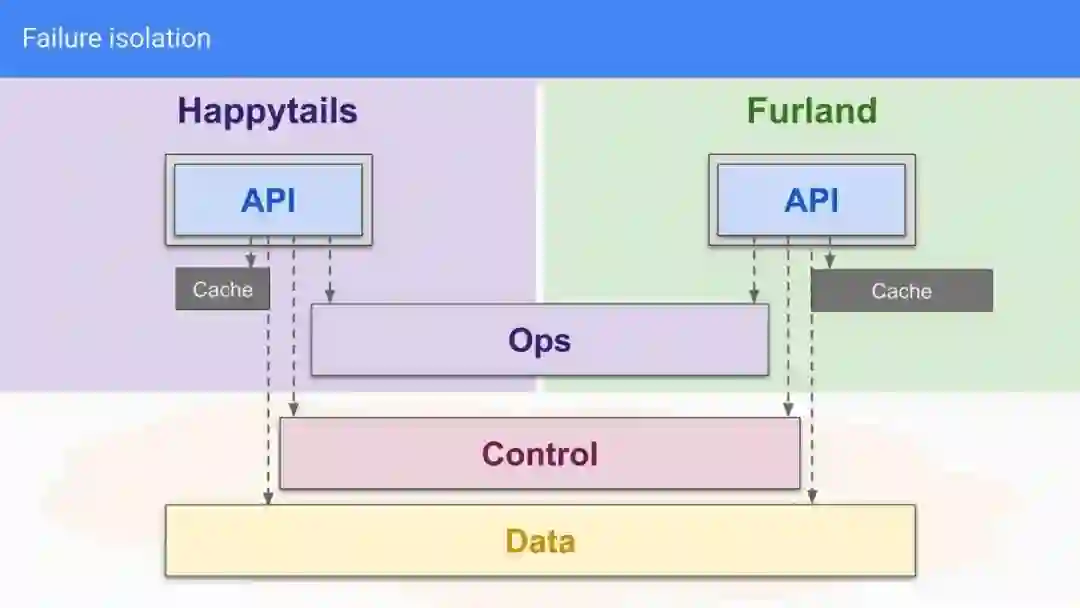
使用有界本地缓存进行故障隔离
产品架构中的其他组件呢?对所有内容都使用缓存是否合理?你能否将在云中运行的服务隔离到特定区域?这两个问题的答案都是肯定的,如果可以,你应该实施这些策略。在云中运行服务并不能避免它成为全局中断的根源。运行在不同云区域的服务仍然可以作为全局服务运行,因此可以成为单点故障来源。将服务隔离到故障域是一种架构决策,并不能仅由运行服务的基础架构来保证。
让我们考虑另一个 PetPic 的使用场景,但这次将重点放在控制(Control)组件上。该组件会执行一系列内容质量验证。开发团队最近基于机器学习(ML)将自动滥用检测程序集成到了控制组件中,这使得每张新图片在上传到服务后立即得到验证。当 Happytails 的新客户开始将大量不同动物的图片上传到 PetPic 时,问题开始出现了,因为 PetPic 设计为只提供狗和猫的图片。上传流激活了我们控制组件中的自动滥用检测,但新的 ML 例程无法跟上请求的数量。
该组件运行在 1000 个线程池中,并将专用于滥用例程的线程数量限制为一半,即 500 个线程。如果大量长处理请求一起到达,这应该有助于防止线程饥饿,就像我们这里的例子一样。工程师没想到的是,一半的线程最后消耗了所有可用的内存和 CPU,导致这两个地区的客户在将图像上传到 PetPic 时开始遇到很高的延迟。
我们如何减轻用户在这种情况下所经历的痛苦呢?如果我们将控制组件运维活动隔离到单个区域,就可以进一步限制这种滥用情况的影响范围。即使服务运行在云中,确保每个区域都有自己的专用控制实例可以保证只有 Happytails 中的客户会受到不良图像上传流的影响。请注意,无状态服务很容易被限制在故障域中。隔离数据库并不总是可行的,但你可以考虑从缓存中实现本地读取,以及偶尔的跨区域一致性作为一个很好的折衷方案。处理栈应该尽可能实现区域隔离。
将服务栈中的所有服务保持在同一位置,并限制在同一故障域中,可以防止广泛传播的全局中断。将无状态服务隔离到故障域通常比隔离有状态组件更容易。如果无法避免跨区域通信,请考虑优雅降级和最终一致性的策略。
在这最后一个场景中,我们将查看 PetPic 的 SLO,并验证每个数据包提供的 SLO 情况。简而言之,SLO 是提供服务时要达成的目标,可以通过合同绑定在我们与客户的 SLA 中。让我们看一下图 5 中的表格:

PetPic 的 SLO
此表显示了工程师眼中将为 PetPic 客户提供出色用户体验的 SLO。在这里,我们还可以看到每个内部组件提供的 SLO。请注意,API SLO 必须基于 API 后端(例如 Control 和 Data)的 SLO 构建。如果需要更好的 API SLO,但我们又无法做到,我们需要考虑更改产品设计并与后端所有者合作以提供更高的性能和可用性。考虑到我们最新的 PetPic 架构,让我们看看 API 的 SLO 是否有意义。
让我们从运维后端(我们将其称为“Ops”)开始,它是后端的一部分,用于收集 PetPic API 的健康指标。API 服务仅调用 Ops 来提供与运维相关的请求、错误和处理时间的监控数据。所有对 Ops 的写入都是异步完成的,故障不会影响 API 服务质量。考虑到这些因素,我们在为 PetPic 设计外部 SLO 时可以忽略 Ops SLO。
将读取 SLO 与数据库对齐
现在,让我们来看看从 PetPic 读取图片的用户旅程。内容质量只在新数据注入 PetPic 时才会进行验证,因此数据读取不会受到控制服务性能表现的影响。除了检索图像信息外,API 服务还需要处理请求,我们的基准测试表明这需要大约 30 毫秒。准备好发送图像后,API 需要构建一个响应,平均需要大约 20 毫秒。仅在 API 中,每个请求的处理时间就增加了 50 毫秒。
如果我们能保证至少有一半的请求会命中本地缓存中的一个条目,那么承诺第 50 个百分位数和 100 毫秒的 SLO 是非常合理的。请注意,如果我们没有本地缓存,请求延迟将至少为 150 毫秒。对于其他所有请求,图像需要从数据库中查询。数据库需要 100 到 240 毫秒才能回复,并且它可能不会与 API 服务共存。网络延迟平均为 100 毫秒。如果我们考虑这些数字的最坏情况,请求可能花费的最长时间是 50 毫秒(API 处理)+10 毫秒(考虑缓存未命中)+100 毫秒(网络)+240 毫秒(数据),总计 400 毫秒。如果我们查看图 6 左列中的 SLO,我们可以看到这些数字与 API 后端结构很好地对齐了。
将写入 SLO 与控制和数据库组件对齐
按照相同的逻辑,我们来检查上传新图像的 SLO。当客户请求向 PetPic 加载新图像时,API 必须请求控制组件以验证内容,这需要 150 毫秒到 800 毫秒。除了检查滥用内容之外,控制组件还会验证图像是否已存在于数据库中。现有图像被视为已验证(并且不需要重新验证)。历史数据显示,Furland 和 Happytails 的客户倾向于在两个地区上传相同的图像集。当数据库中已经存在图像时,Control 组件可以为其创建一个新 ID,而无需复制数据,这需要大约 50 毫秒。这段旅程适合大约一半的写入请求,50% 的延迟情况总计为 250 毫秒。
包含滥用内容的图像通常需要更长的时间来处理。控制组件返回响应的时间限制为 800 毫秒。此外,如果图像是狗或猫的有效图片,并且假设它不在数据库中,则数据组件可能需要长达 1000 毫秒来保存它。考虑到所有数字,在最坏的情况下,返回响应可能需要近 2000 毫秒。正如你在图 7 的左列中所见,2000 毫秒远远高于当前 SLO 工程师为写入而预测的时间,这表明他们在提出 SLO 时可能忘了包括不良场景。为了缓解这种不匹配现象,你可以考虑将第 99 个百分位的 SLO 与请求截止时间绑定。这种情况也可能导致服务性能不佳或错误。例如,数据库可能会在 API 向客户端报告超过操作期限后才完成图像写入过程,从而导致客户端混乱。在这种情况下,最好的策略是与数据库团队合作提高数据库性能或调整 PetPic 的写入 SLO。
确保你的分布式产品为客户提供正确的 SLO 是非常重要的。在构建外部 SLO 时,你必须考虑所有后端的当前 SLO。你应该考虑所有不同的用户旅程以及请求生成响应可能采取的不同路径。如果需要更好的 SLO,请考虑更改服务架构或与后端所有者合作以改进服务。将服务和后端保持在同一位置,可以更轻松地确保 SLO 对齐。
Silvia Esparrachiari 已在谷歌担任软件工程师 11 年了,她曾在用户数据隐私、垃圾邮件和滥用预防领域任职,最近在谷歌 Cloud SRE 工作。她拥有分子科学学士学位和计算机视觉和人机交互硕士学位。她目前在谷歌的工作重点是促进一个相互尊重和多元化的环境,让人们可以更好地提高他们的技术技能。
Betsy Beyer 是谷歌纽约分部的技术作家,专门研究站点可靠性工程(SRE)。她与他人合著了《站点可靠性工程:谷歌如何运行生产系统》(2016 年)、《站点可靠性工作簿:实施 SRE 的实用方法》(2018 年)和《构建安全可靠的系统》(2020 年)。在她迄今为止的职业生涯中,Betsy 还学习了国际关系和英国文学,她拥有斯坦福大学和杜兰大学的学位。
原文链接:
https://www.infoq.com/articles/pitfalls-patterns-microservice-dependency-management/
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
流行20年的架构设计原则SOLID可能已经不适合微服务了
软件工程师年满 40 岁,下一步怎么走?
曝腾讯天美员工税后收入250万,月均20万;传阿里CEO张勇要放权;“人人影视字幕组”侵权案宣判,被告人获刑三年半 | Q资讯
逃离被微软支配的恐惧,.NET开发者们Fork了一个开源分支

点个在看少个 bug 👇



