【Transformer】Transformer中16个注意力头一定要比1个注意力头效果好吗?
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要10分钟
跟随小博主,每天进步一丢丢


作者:Paul Michel
编译:ronghuaiyang
来自: AI公园
多头注意力中的冗余分析,看看是否可以在不影响性能的情况下做剪枝。

“Hercules Slaying the Hydra”, Sebald Beham, 1545 (source: Art Institute of Chicago)
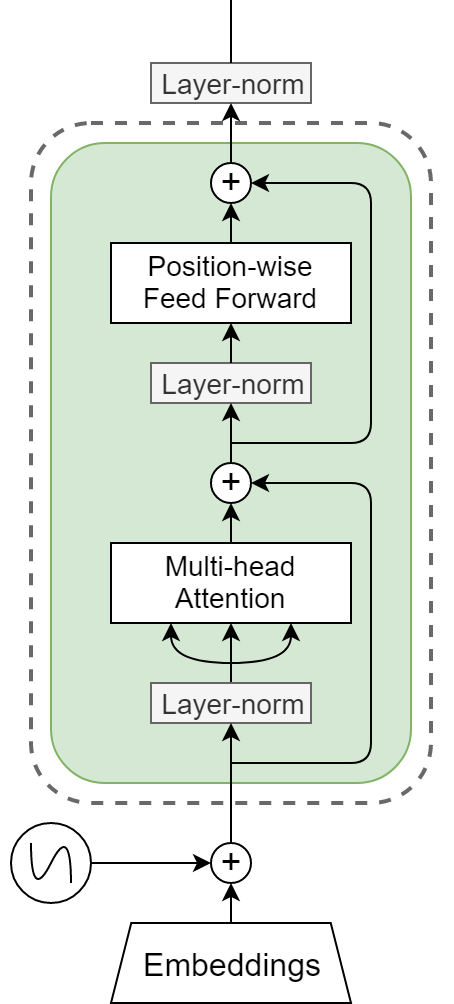
自Vaswani等人提出transformer模型以来,transformer模型已经成为NLP研究的主要内容。它们被用于机器翻译,语言模型,并且是最新最先进的预训练模型。典型的transformer架构由堆叠的块组成,图1中显示了其中的一块。这种块由一个多头部注意层和一个每个位置的2层前馈网络组成,并与残差连接和层归一化连接在一起。多头注意机制的普遍应用可以说是transformer的核心创新。在这篇博客文章中,我们将仔细研究这种多头注意力机制,试图理解多头实际上有多重要。这篇文章是基于我们最近的NeurIPS论文:https://papers.nips.cc/paper/9551-are-sixteen-heads-really-better-than-one.pdf。
多头注意力
在深入研究多头注意力之前,我们先来讨论一下常规注意力。在自然语言处理(NLP)的上下文中,注意力通常是指计算基于内容的向量序列的凸组合。这意味着权重本身是输入的函数,通常的实现是:
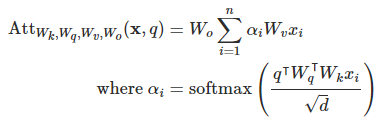
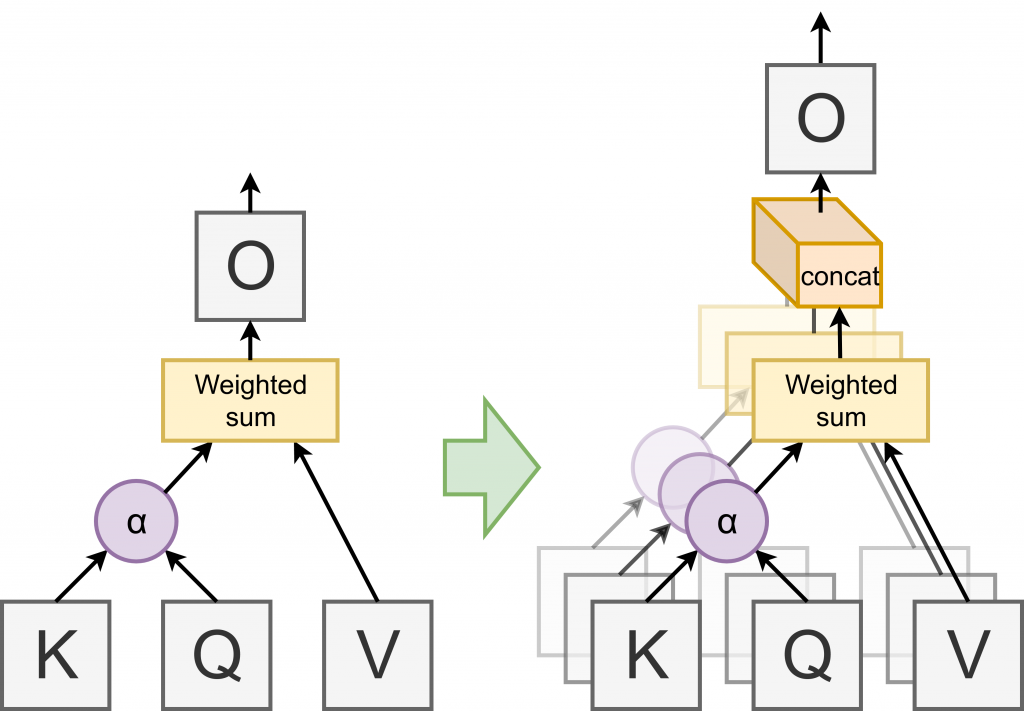
参数为,输入序列为x,查询向量q。使用注意力而不是递归神经网络等句子池化的操作符有很多优势,其中最重要的是在高度并行环境(如GPU)中具有很高的计算效率。然而,它们是以表达性为代价的(例如,注意力只能在其输入的凸包中取值)。在Vaswani等人中提出的解决方案是使用“多头注意力”:本质上是并行地运行
个注意力层(“头”),将它们的输出连接起来,并通过仿射变换提供给它。
通过将最终输出层分割成大小相等的
个层,可以将多头注意机制改写为:
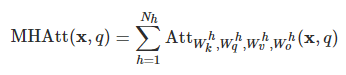
参数为以及
,当
的时候,这个就和原始的注意力形式是完全一样了。然而,为了使得参数的数量不变,
设置成
,这样的话,多头的注意力可以认为是低维度的原始的注意力层的集成。
去掉一些注意力头
但是为什么多头比单头好呢?当我们开始尝试回答这个问题时,我们的第一个实验是这样的:让我们取一个好的、最先进的transformer模型,然后去掉注意力头,看看会发生什么。具体来说,我们通过修改多层头的表达式来掩盖推理时的注意头:
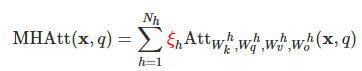
其中,
的范围是{0,1},和头相关的掩码。
我们使用BERT模型(Devlin et al. 2018)进行了初始实验,对MultiNLI数据集进行了微调。我们独立地去掉了每个注意力头,并报告了BLEU评分(一种标准的MT评估指标)的差异。令我们惊讶的是,很少有注意头有任何实际效果(见下图)。
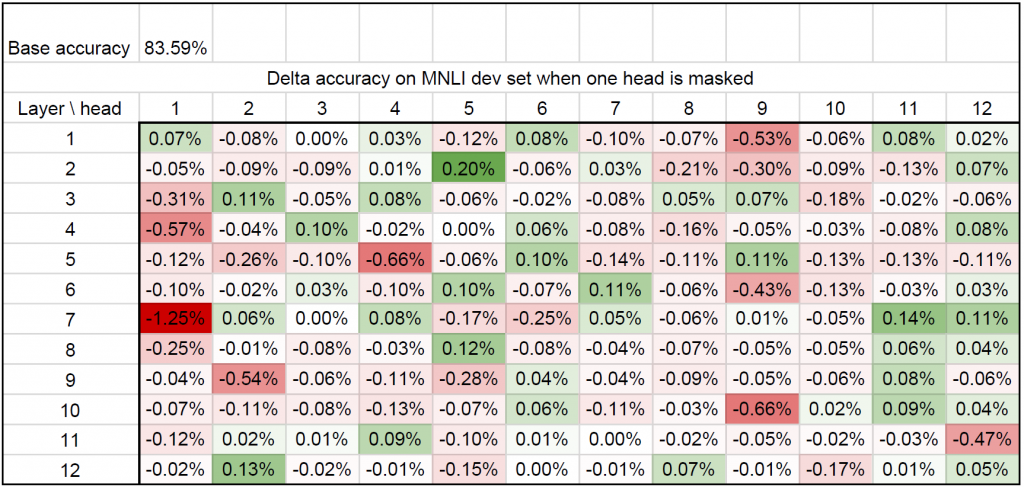
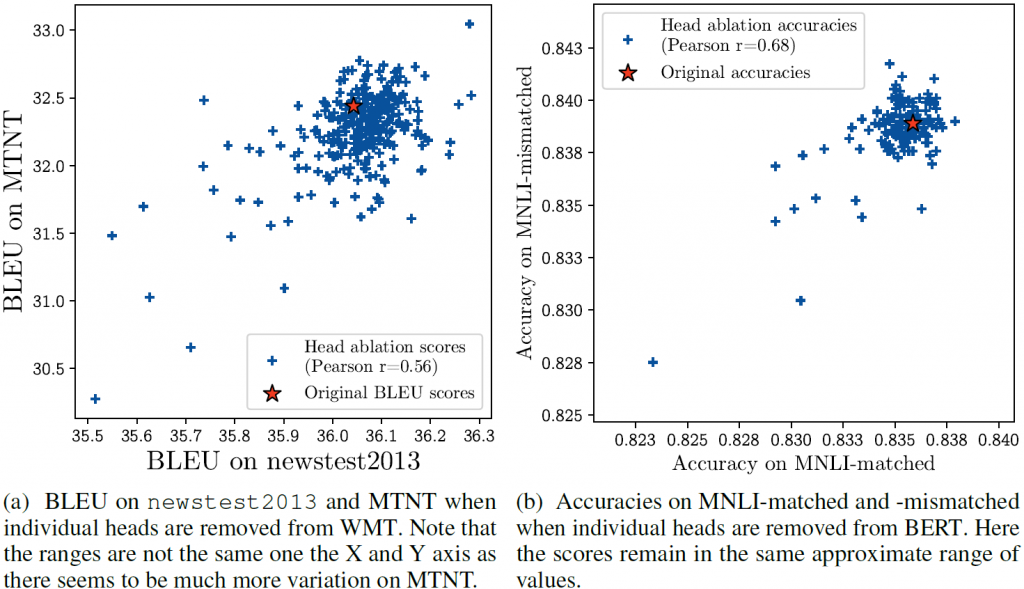
这向我们表明,大多数注意力头实际上是多余的。此外,我们还测试了特定的注意力头如何在不同的数据集中泛化,这些数据集对应于相同的任务。为此,我们查看了两个对应数据集的两个任务:机器翻译(数据集:newstest2013(新闻文章)和MTNT (Reddit评论))以及MultiNLI(数据集:匹配和不匹配)。有趣的是,这一现象在某一任务的不同领域中普遍存在,如下图所示:在不同数据集上删除每个头的影响之间存在正线性相关关系。
为了进一步具有说服性,并对这个问题进行抨击,我们以一种扭曲的方式重复了这个实验。对于每一个注意力头,我们都计算出在所有其他注意力头被移除后的测试分数的差异(保持模型的其余部分不变——特别是我们没有触及其他的注意力层)。
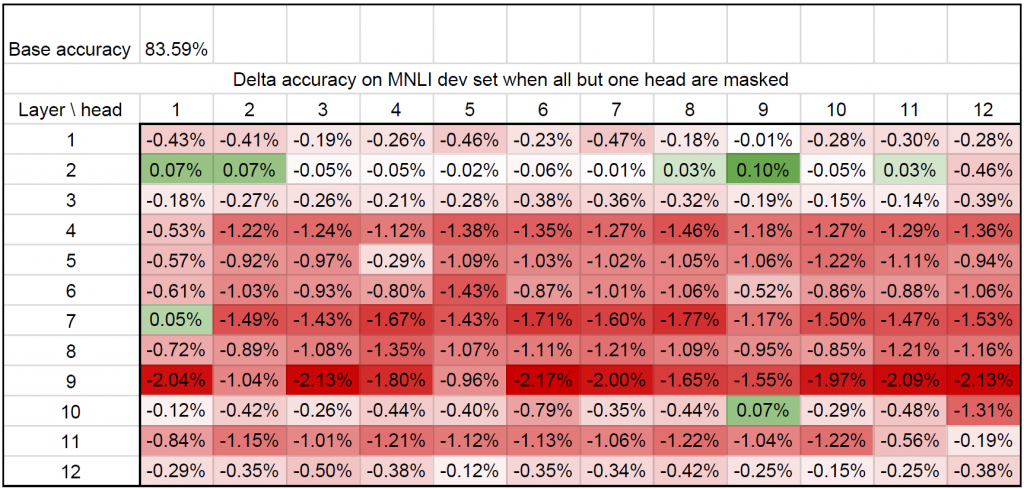
特别引人注目的是,在几层(2层、3层和10层)中,只需要一些注意力头就足够了。仅用一个注意力头就可以保持相同(或更好)的性能水平。所以,是的,在某些情况下,16个注意力头(这里是12个)并不一定比1个好。然而,这些观察并没有解决两个关键问题:
-
在模型中去掉注意力头产生的复合影响:我们单独考虑每一层(我们将所有的注意力头保留在其他层中),但是在整个transformer架构中去除注意力头可能会对性能产生复合影响。 -
预测注意力头的性能:我们正在观察头部烧蚀后对测试集的影响。
语义注意力头剪枝

为了解决这些问题,我们求助于剪枝文献中探索的各种方法,以计算在验证集或训练数据子集上估计的重要性得分 ,并将其用作确定剪枝顺序的代理。较低的重要性得分 意味着注意力头h将首先被修剪。特别是我们把 设置为( )和( )之后,loss的绝对差。注意力头h这样剪枝:
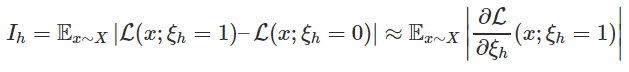
我们用一阶近似这个差异,这使得计算每个注意力头的
成为可能,在数据集X中的每个样本上进行一次向前和向后的传递。否则,我们将需要尽可能多的前向通过有注意力头的模型(加上一个为未修剪的模型)。对于BERT(12×12=14412×12=144个注意力头)或大型transformers(16×3×6=28816×3×6=288个注意力头)这样的模型,这是非常不现实的。另一方面,使用这个粗略的近似值,我们可以同时计算所有的
,而且整个过程在计算上并不比常规训练更昂贵。
在下面的图中,你可以看到系统注意力头剪枝对各种任务的性能的影响。在这里,我们按重要程度来对注意力头剪枝。“10%剪枝”是指我们用10%最低的 等来剪枝。
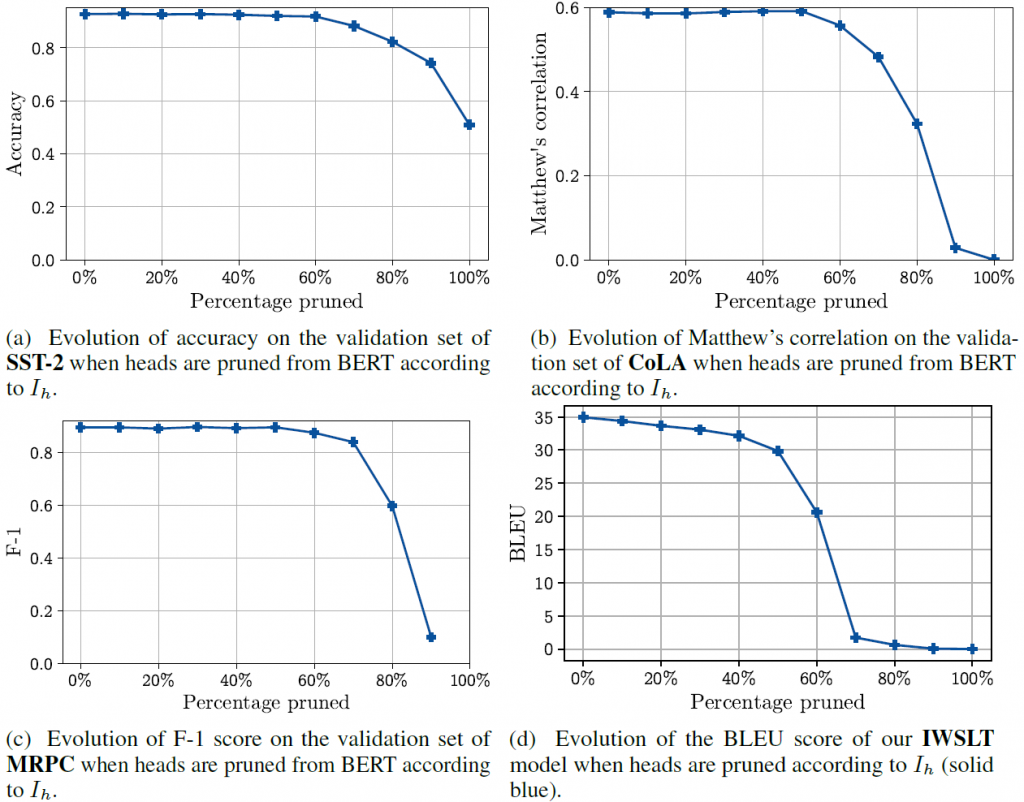
所以这里的情况有点微妙。一方面,根据任务和模型,可以在不损失任何性能的情况下,将heads的数量减少60%。另一方面,我们也不能降低到每层一个注意力头。所以一般来说,多注意力头比单个好。
在训练中发生了什么?
我们想知道的一件事是,在训练期间,这种现象是在什么时候出现的。我们通过使用上述方法在优化过程的不同阶段对模型进行剪枝来研究这个问题。在这个实验中,我们在IWSLT数据集上使用一个更小的transformer模型(6层和8个注意头)进行德语到英语的翻译。我们查看了“剪枝配置文件”——性能随剪枝百分比的函数下降的速度——在优化过程中是如何变化的。
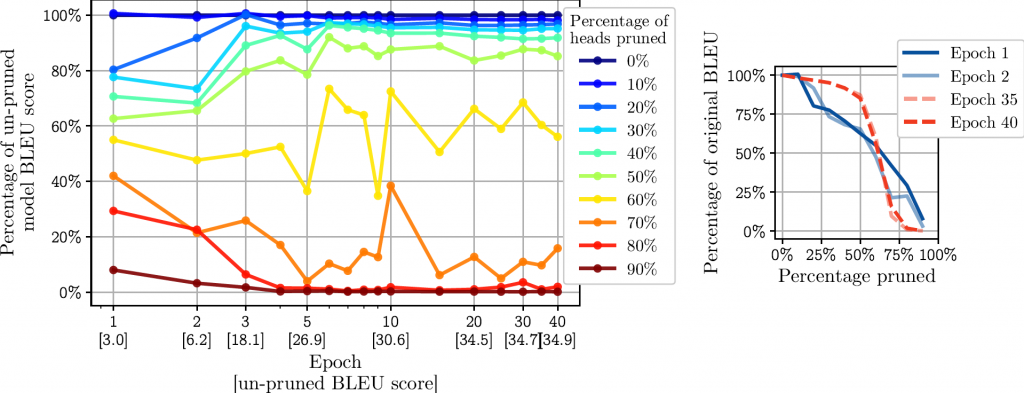
在最初的几个epochs上,剪枝对性能的影响是线性的,这表明所有的注意力头都是同等重要的(剪枝10%的注意力头的成本~10%的模型性能)。然而,请注意图中最早在epoch 3开始出现的最上面(接近原始分数的100%)和最下面(接近原始分数的0%)部分的集中。这表明,在早期的训练中,冗余的注意力头(40%的冗余注意力头可以用大约10%的性能成本进行剪枝)和“有用的”注意力头之间有明显的区别。
你想知道的更多吗?
在我们试图理解自注意力在transformer模型中的作用的同时,也发表了一些研究成果。两个特别有趣的出发点是:
-
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned (Voita et al. 2019):本文主要研究机器翻译模型中的自注意力层。他们识别了一些注意力头的“角色”(不管这个头是关注罕见的单词,还是与依赖弧重合,等等),并开发了一个智能的注意力头剪枝算法。 -
What Does BERT Look At? An Analysis of BERT’s Attention (Clark et al. 2019)。本文的分析以BERT (Devlin et al., 2018为中心,这是一种事实上的预先训练过的语言模型。作者非常深入地研究了注意力头的作用,特别是关注哪些语法特征可以从自我注意权重中获得。
接下来的工作?
因此,虽然在训练时16个注意力头比单个头好,但是在测试时很多注意力头是多余的。这使得有很多机会缩减这些巨型模型的推理(事实上很多最近的工作已经开始剪枝或蒸馏大型transformer 模型)。
我特别感兴趣的一个方面是利用这种“过剩的能力”来处理多任务问题:与其丢弃这些冗余的注意力头,我们能否更有效地使用它们来“塞入更多的知识”到模型中?

英文原文:https://blog.ml.cmu.edu/2020/03/20/are-sixteen-heads-really-better-than-one/





