Spark在唯品会财务系统重构中的实践总结

本文转自唯技术订阅号,经同意授权转载
大多数人听到Spark这个名字就很容易联想实时计算和机器学习,然而却忽略了Spark的另外一个杀手级特性Spark SQL,财务系统研发团队利用Spark SQL的能力重构财务系统的供应商结算系统。Spark SQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具。随着Spark的发展,在保留Shark内存列存储(In-Memory Columnar Stoarge)和Hive兼容性等少部分特性情况下,重新开发了SparkSQL,摆脱了对Hive的依赖性,无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
在财务系统重构项目中,充分地利用了Spark SQL对RDBMS和NoSQL的兼容性,通过它可以非常方便从MySQL、Oracle、Hive、Redis以及远程服务(OSP)获取数据。在讨论Spark给我们带来便利性的同时,也要讨论如何避开那些坑。本文根据在使用Spark SQL中的碰到的问题作一个简单的总结:
问题一:如何避免作业运行时发生Out of Memory?
Spark 的主要特点是利用内存进行聚合计算和存储,当所分配的资源不足以支持运算或者存储时,Executor将自动地被Yarn杀掉,如下图:
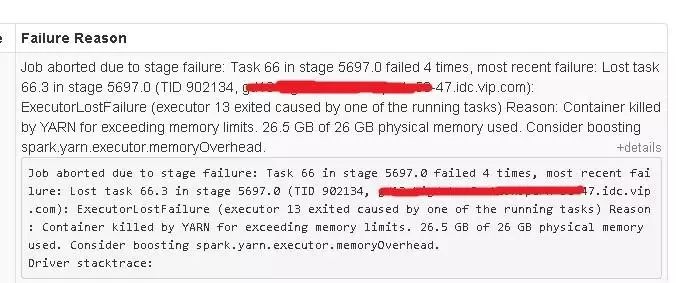
从以上错误信息中可以很清楚地看到任务由于Executor内存不足而失败,解决这个问题有以下4个思路:
检查任务中分片的数据是否均匀,通过数据比较均匀的字段对数据进行分片增加分片的数量,并减少每个分片数据的规模。
及时释放缓存的RDD,Spark自动的监控每一个节点的缓存的使用并按照LRU算法清除旧的数据缓存,为了有限的内存空间更有效率,使用RDD.unpersist()方法立即释放缓存。
通过观察Spark的运行日志和Spark UI存储使用情况,使用rdd.persist(StorageLevel)方法调整RDD缓存的存储策略,将缓存的数据序列化保存在硬盘中, 牺牲一部分时间换取任务的成功完成。
以上三个方法均无法降低内存使用的情况, 可调整Executor内存分配或者memoryOverhead参数,但实际效果可能并不好。
注意:
rdd.cache()和rdd.persist(Storage.MEMORY_ONLY)是等价的,在内存不足的时候rdd.cache()的数据会丢失,再次使用的时候会重算,而rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)在内存不足的时候会存储在磁盘,避免重算,只是消耗点IO时间。
内存溢出情况:在Spark on yarn模式,即实际运行过程中ExecutorMemory (堆内)+MemoryOverhead(堆外)之和(JVM进程总内存)超过container的容量。
Yarn Container:
http://dongxicheng.org/mapreduce-nextgen/understand-yarn-container-concept/
Container 内存:
http://ju.outofmemory.cn/entry/199175
Container 配置:
https://yq.aliyun.com/articles/25468
问题二:在自定义函数中实例变量造成频繁的FULL GC
Spark 中的自定义函数对于很多Spark SQL的开发人员来讲都是一大利器,使用不当却给应用带来灾难。在某一次的任务运行中我们发现在数据量没有明显增长的情况下,Exectuor的GC时间增长了一个量级,如下图所示:
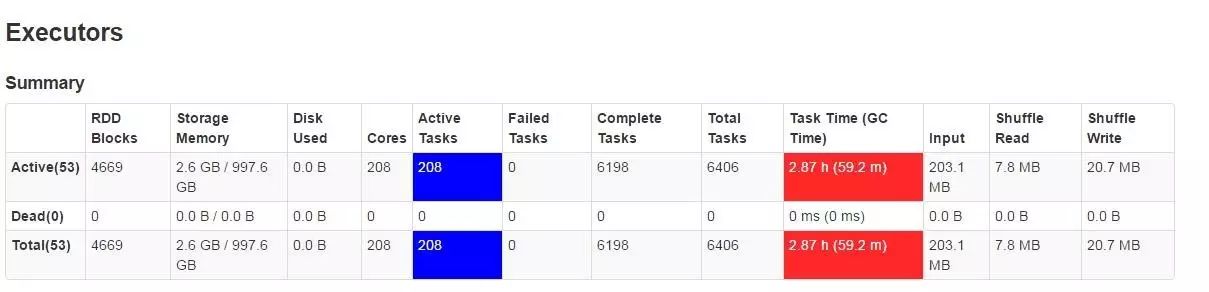
经过分析发现我们在Spark SQL中使用的自定义函数CuxApVendorSetupUDF增加了一个Map的实例变量,如下图。这个Map大约有几十万的数据,这个Map实例变量在Spark SQL运行过程中被不同的Task里面频繁的创建并赋值。

发现问题后解决的方法就比较简单,可以将这个Map进行广播出去,减少该数据集在不同的Task中创建,如下图:
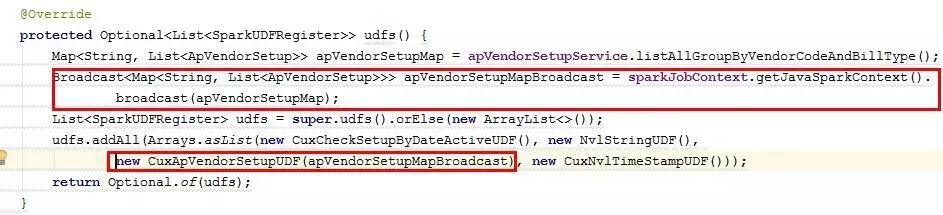

注:Spark中的广播变量允许开发人员在一台机器上保留一份只读的变量缓存,减少变量在不同的Task之间进行拷贝复制,Spark同时也会尝试高效的广播算法分发广播变量减少多台机器 之间的通读成本。
广播变量存储在 executor的 storage memeory 中 (http://www.cnblogs.com/jcchoiling/p/6494652.html), storage 是存储broadcast,cache,persist数据的地方。
在某一次的任务运行过程发现该任务一直没有结束,在Spark UI中看到多个不同类型的线程阻塞的状态,比下图所示的事件心跳,Spark UI信息收集以及任务结果收集线程都在阻塞状态。
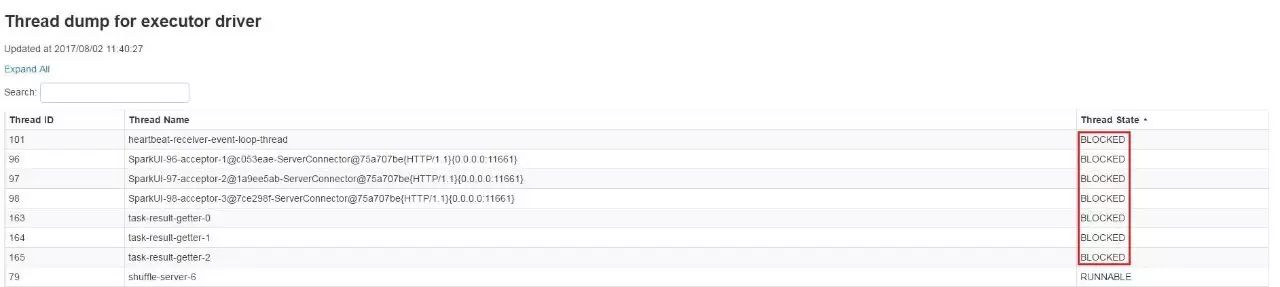
点开其中一个线程可会发现阻塞点在于服务器上的Socket通讯上,如下图:
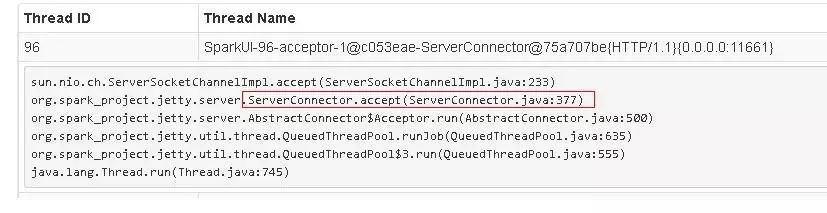
同时也看到部分的Executor无法显示地址或者主机名
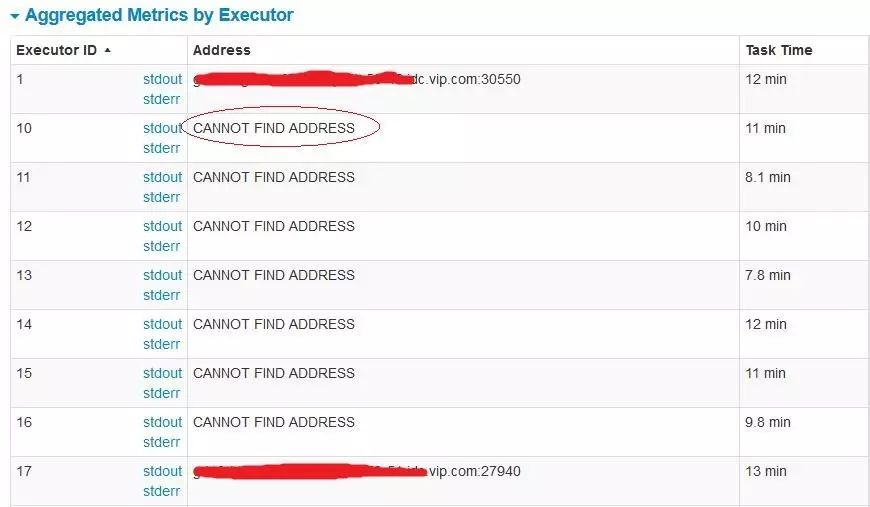
1. 根据以上信息在网上找到大多数的文章都认为是Executor的内存或者CPU资源不足造成,但是从Spark日志来看任务未启动而且服务器尚有充足的资源启动新的Executor, 故排除这个原因。
2. 由于该任务需要访问外部服务以及频繁开关MySQL数据库连接,造成主机上Socket端口开启数量过多,导致有一些连接无法建立,如上面的Spark UI无法创建连取获取Executor信息。
问题四:系统属性无法被正确初始化
由于开发团队基本都是传统的JAVA开发人员,按照JAVA应用的惯例在系统设计之初大部分的系统配置信息以环境变量的形式存储在操作系统上面, 结果发现每增加或者修改环境变量均需要重新启动整个Spark集群。这明显是不符合Spark集群的运维规范,也导致任务部署时间过长。经过讨论后改成配置信息由应用配置文件中读取,同时兼容原来的环境变量的配置信息,最后将环境变量和配置文件读取配置信息写到System.Property中, 那么一不注意坑就此时出现了。
从下图的Spark集群的运行模式可以看到,一个Spark作业运行完成由Driver、Executor和集群管理共同完成,每一个节点均是独立JVM。许多Java开发人员考虑代码的运行效率避免多次初始化,很自然地在作业的入口对系统属性初始化,然而在任务在Executor中却无法获取系统属性或者只能从环境变量中获取属性,原因是作业的入口尚在Driver端运行。
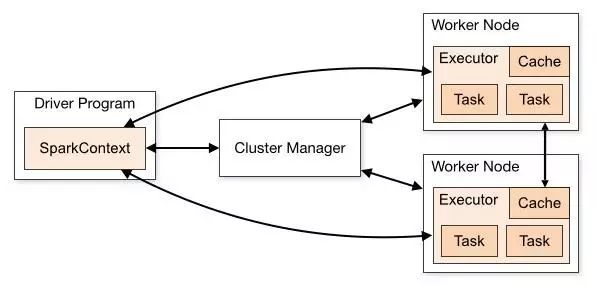
解决这个问题确保System.setProperty在每一个Executor中运行,由Executor执行任务再次对系统属性进行初始化。
问题五:在写入数据库的任务中慎用Spark.speculation
一个集群中,不同节点的负荷有差异,Spark.Speculation参数决定是否将将跑得慢的任务重新复制到另外一个稍空闲的Executor中执行,以加快整个作业的运行速度。通过重新调度后的任务可能同时在多个不同的Executor中执行,那么就有可能产生重复的数据并写到数据库,造成脏数据并影响到业务。在我们实际的案例中,由于数据表中存在唯一索引,没有成生脏数据,但任务由于数据库的写入异常而中断。
注:Spark.speculation的默认值是不启用。
如果Spark.Speculation参数 设置为true:可以让Spark在发现某些task执行特别慢的时候,可以在不等待完成的情况下被重新执行,最后相同的task只要有一个执行完了,那么最快执行完的那个结果就会被采纳。
http://www.infoq.com/cn/news/2016/01/Spark-performance-tuning
官网解释:

问题六:时刻关注写入目标存储状态,避免任务执行失败
作来一个传统的JAVA开发者,经常痛恨自己的程序在单个JVM进程无法发挥数据库的最大威力,那么在Spark这个平台上这个问题得到轻易的解决,可以很方便的通过调整分片来让Spark Cluster启用多个Executor(JVM)和线程来完成你想做的事情。俗话说 “欲速则不达”, 在我们解决前面的任务计算性能瓶颈后,数据库写入就成为下一个瓶颈,造成任务的大面积的失败,如下图MySQL数据状态,单个数据库实例的UPDATE语句达到快20万/秒,CPU负载非常高。

在我们大部分任务的典型模式是源数据MYSQL库读取->Spark运算->结果写入目标MYSQL数据库,最后的写入阶段非常集中,如何控制写入的速度降低MYSQL的负载又成为我们另外一个问题,尽量将写入的速度在一个可接受的范围,大约是10000 tps 左右,当时主要采取了以下几个措施:
控制作业的发起数量,降低作业并发量
降低分片的数量,减少Executor数量和并行Task数量
-
合并SQL语句,将多个UPDATE语句合到一个,减少SQL命令执行量。
数据源是MySQLl,所以在用Spark读取数据量比较大的表时,需要利用表索引分片小批量并发的读取,将数据量比较大的表数据load到内存形成rdd。
问题七:避免org.apache.spark.SparkException: Task not serializable
有经验的Spark开发者都知道,所有的外部变量在闭包中使用都会自动的传输到集群中,在Driver端初始化的变量在Executor中使用就会报出以上Task not serializable异常,下图中的异常就是在rdd.partitions中引用了某一个变量。
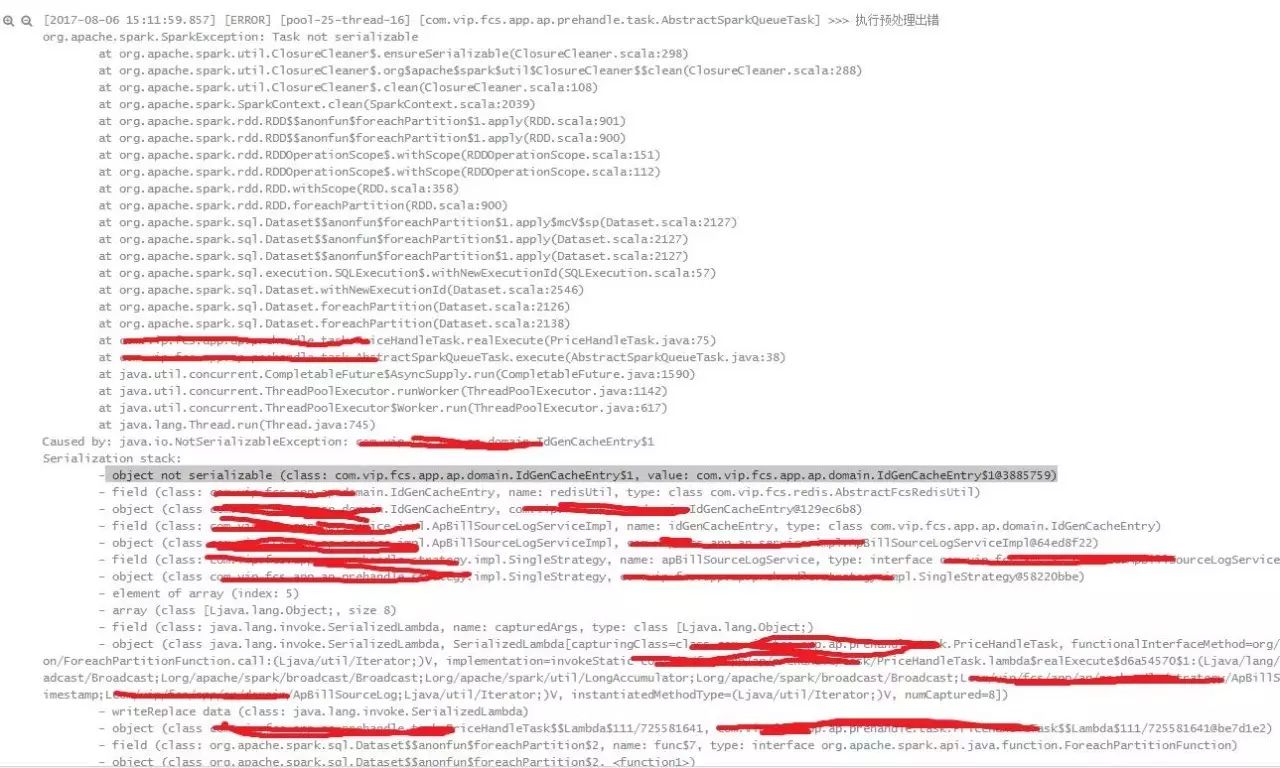
解决上面这个问题,主要有以下几个方法:
将该对象以及该对象的引用对象均实现序列化
在调用rdd.foreachPartition并在方法中创建该对象
将该对象定义为一个静态对象
-
不要使用外部对象的属性
问题八:Spark累加器(Accumulator)陷阱及解决办法
在Spark开发中Accumulator经常当作一个轻量级的调试器,对Task处理数据量或者资源情况进行追踪。可是如果你对Accumulator的运行机制不太了解话,有时候会带来一些错误的信息。在以下的场景中需要特别注意:
在使用Accumulator的时候,为保证准确性,只在RDD中使用一次action操作,如果需要使用多次则使用cache或者persist操作切断RDD的血缘关系。
在Stage 执行失败时,未处理的Accumulator将会返回错误的结果。假设一个Executor节点宕机且正好处于在Shuffle阶段,Spark会检查哪些任务需要重新运行并将这些任务调度到运行良好的Executor中运行,那么其中有一些任务会被执行了多次,那么Accumulator也会被更新多次得到错误的结果。
-
如果Spark启用了猜测执行的功能,同一个Task也可能被在不同的节点中运行多次,导致Accumulator得到错误结果。
问题九:如何在一个Spark集群下,多个任务同时跑起来?
由于我们的Spark集群是一个独立的小集群,集群的资源并不多,同时我们又想同时开启多个任务来充分压榨系统的能力。在系统运行之初,我们发现集群只允许一个任务在运行,另外一个任务即使在系统尚有资源的情况都无法启动运行,一直在等上一个任务执行完成才能启动,这就大大的影响一些高优先级任务的执行,也不利于提高资源利用率。看到这里,相信大家都已经猜测到通过YARN队列的实现资源的共享和隔离,但是每个队列分配多少资源以及采取什么分配策略是合适的呢?
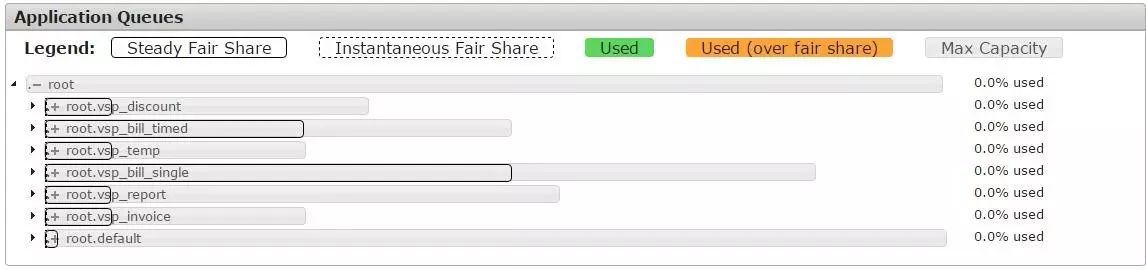
同团队沟通后确定了以下几个分配原则:
根据业务功能,优先级以及所需资源的数量创建队列。
每一个队列的最少资源不应过多,建议足够启用1个Executor即可。
-
最高优先级队列的最大容量之和不超过系统的总资源。
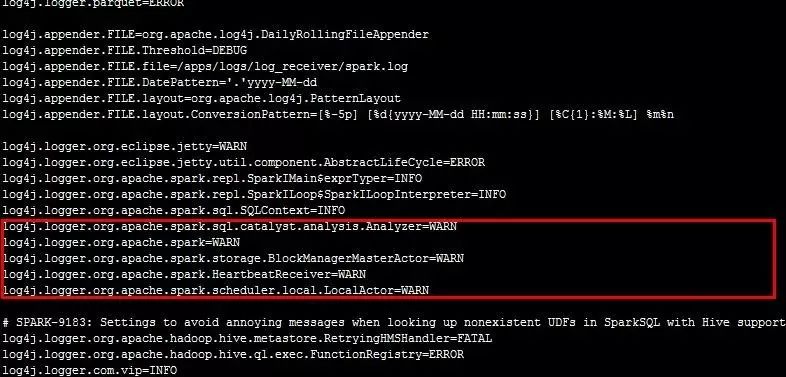
问题十:Spark 日志输出过多导致日志系统堵塞
Spark 执行日志级别默认为INFO,在执行任务过程中会输出非常多执行过程日志,但对我们目前的用处不是太大,而我们用dragonFly(Logstash)搜集日志,短时间内产生过多的日志会导致日志搜集的客户端挂掉,从而收集不到日志,不利于问题跟踪和错误预警。
解决方式:调整Spark 的日志级别为WARN,业务日志的日志级别为INFO. 由于Spark在YARN模式下运行,无法支持在Spark Conf 中配置新log4j.properties文件生效,必须将修改后的log4j.properties放到集群配置文件目录方能生效。
近期热文:






