后训练量化——Data free quantization

极市导读
本文作者详细的介绍了高通的一篇有关模型量化的工作,从该工作为基础解说Weight Equalization 和 Bias Correction两个量化技术,并落实到了代码层面的解析。>>加入极市CV技术交流群,走在计算机视觉的最前沿

首先登场的是高通提出的一篇论文:Data-Free Quantization Through Weight Equalization and Bias Correction。之所以介绍它是因为笔者在使用高通的模型量化工具 Snapdragon Neural Processing Engine (SNPE) 时感觉效果奇好,而 weight qualization 和 bias correction 就是该工具中提供的常用算法,应该说是比较成熟的量化技术了,况且算法本身也有很多巧妙之处,值得学习。
三个关键点
这篇论文发表于 2019 年的 ICCV 会议,但在此之前高通就已经将它落地到自己的工具中了,算是有一定知名度的论文。学习这篇论文只要把握住三个点就可以:Data-Free、Weight Equalization、Bias Correction (好的题目可以把握住读者的心)。
Data-Free Quantization
第一点 Data-Free,也是最不重要的一点,我觉得是高通搞出来的一点噱头。
高通在论文提出了模型量化算法的四重境界。
第一重,不需要数据,不需要重训练,不 care 模型结构,看一眼你的网络就可以自动帮你量化好。这一重即论文提到的 Data-Free。但这种一般只对 weight 量化起作用。高通说它的方法是 Data-Free 的,意思就是说它对 weight 的量化方法非常鲁棒,数据都不用就给你量化好了,效果还很好。当然对 feature 的量化还是得老老实实用数据来统计数值范围的。
第二重,需要数据,但不需要重训练,也不 care 模型结构。这种是目前大部分后训练量化追求的,用少量的数据达到最好的量化效果。这也是对 feature 进行量化的最低要求。但有些论文为了对 weight 做更好的量化,也会需要一点数据来辅助优化 (高通说:弟弟们,我不用,我 Data-Free)。
第三重,需要数据,也需要重训练,但不 care 模型结构。这种就是量化训练追求的最高境界了。
第四重,需要数据,也需要重训练,模型结构还不能乱来。这种指的是最 navie 的量化训练,一遇到特殊的结构或者压缩很厉害的模型就 gg 的那种。
Weight Equalization
weight equalization 是论文的关键点之一,这在另一篇论文 Same, Same But Different 中也有所提及。
weight equalization,顾名思义,就是对 weight 进行均衡化操作。为什么要有这个操作呢?因为高通研究人员在剖析 MobileNetV2 的时候发现,这个网络用 per-layer 量化精度下降极其严重,只有用上 per-channel 的时候才能挽救一下。具体实验数据出自 Google 的白皮书。我特意去翻了一下,发现还真是:
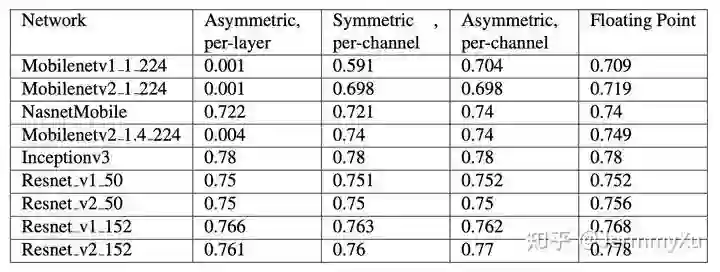
Mobilenet 类的网络在 per-layer 量化下,精度直接掉到 0.001 了,而同样作为小网络的 Nasnet 下降很小 (per-layer 精度一般是比 per-channel 低一些,但这么严重的精度下降,我怀疑是不是 Google 的程序员跑错代码了)。
为什么会有这种情况呢?原因在于 MobileNetV2 中用了大量的可分离卷积 (depthwise conv),这个卷积的特殊之处是每个 output channel 都只由一个 conv kernel 计算得到,换句话说,不同 channel 之间的数值是相互独立的。研究人员调查了某一层可分离卷积的 weight 数值,发现不同的卷积核,其数值分布相差非常大:
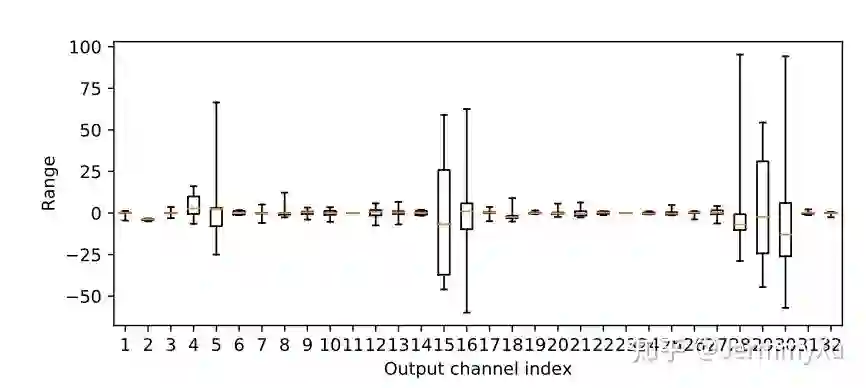
纵坐标是数值分布,横坐标表示不同的卷积核。你会发现,有些 weight 的数值分布在 0 附近,有些数值范围就非常大。在这种情况下,如果使用 per-layer 量化,那这些大范围的 weight 就会主导整体的数值分布,导致那些数值分布很小的 weight 在量化的时候直接压缩没了。这也是为什么 per-channel 对可分离卷积效果更好的原因。
而 weight equalization 要做的事情,就是在使用 per-layer 量化的情况下,使用一些方法使得不同卷积核之间的数值分布能够均衡一些,让大家的数值分布都尽量接近,这样就可以用 per-layer 量化实现 per-channel 的精度 (毕竟 per-channel 实现上会比 per-layer 复杂一些)。
高通说他们实现这一步并不需要额外的数据,可以优雅地在 Data-Free 的情况下实现,这也是他们给论文起名 Data-Free 的缘由。具体的算法我们后面再说。
Bias Correction
除了 weight 的问题之外,研究人员发现,模型量化的时候总是会产生一种误差,这种误差对数值分布的形态影响不大,但却会使整个数值分布发生偏移 (biased)。
假设有 个样本,那么对于 feature map 上面的每一个数值,我们可以用下面这种方式计算偏移误差 (biased error):
其中, 是量化后再反量化的 weight (即带了量化误差), 是原先的 weight, 是输入,对应的 是量化后的输出, 是原输出。
用这个公式可以算出引入量化误差后的 feature map 上每个点和原先的相差了多少,统计一下这些误差,就得到下面这张图:
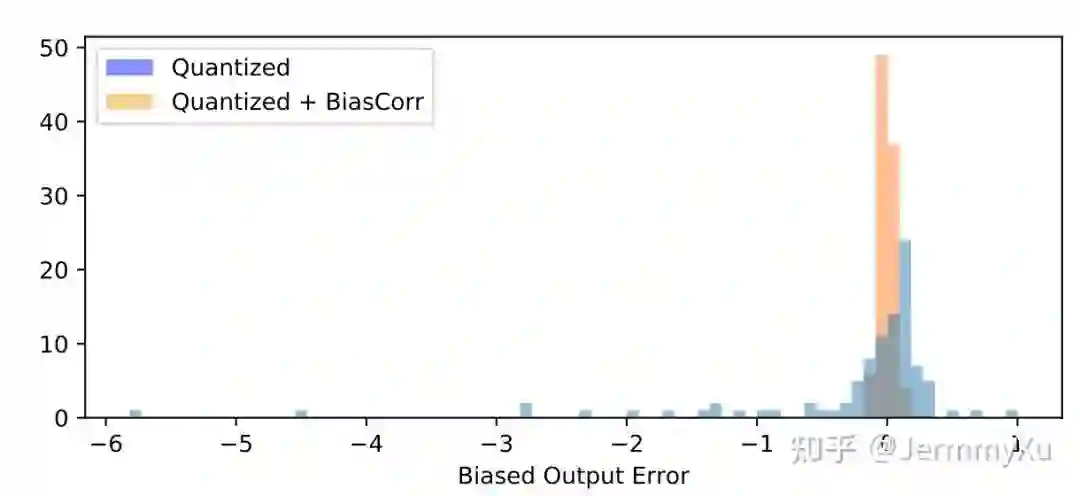
这里面蓝色的柱状图就统计了量化后的误差分布,看得出,有不少 feature 的误差已经超过了 1,而理想状态下,我们是希望量化后的误差能集中到 0 附近,越接近 0 越好,就像橙色直方图那样。
其实,这种 biased error 不仅仅只有量化的时候会出现,在做模型压缩的时候也会遇到。做过画质类任务模型剪枝的同学可能有这种体验,就是当你把一个大模型里面某些卷积的通道数砍掉时,会发现模型的输出结果出现一种整体上的色彩变化。比如,我在一个图像去噪的实验中用了剪枝后,出现下面这种现象:

模型剪枝后,你会发现模型的输出结果和原来相比,好像整体的颜色上多了一个偏移 (biased),但图像里面的物体基本还能辨识 (数值分布的形态没有发生变化)。
我自己画了幅简图描述这种现象:
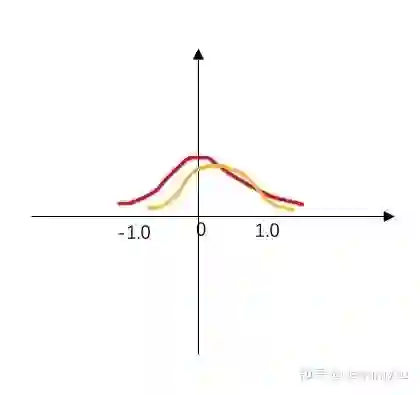
其中红色的分布是原模型的分布,而橙色分布就是剪枝后带了 biased error 的分布,它的形状大体上和红色分布类似,但整体向右发生了一点偏移,从而导致整个画面的色彩发生了变化。一般来说,经过 finetune 后,这种现象可以慢慢得到缓解。
以上是我对 biased error 的一些理解。
研究人员发现,用上 weight equalization 后,这种 biased error 会更加地突出。而 Bias Correction 就是为了解决该问题提出的。
具体方法
Weight Equalization
要实现 Weight Equalization,一个很直接的想法就是对卷积核的每个 kernel (或者是全连接层的每个权重通道) 都乘上一个缩放系数,对数值范围大的 kernel 进行缩小,范围小的则扩大。
Positive scaling equivariance (伸缩等价)
不过,乘上放缩系数的同时不能影响网络的输出。为了保证计算上的等效性,论文利用了卷积层 (包括全连接层) 和 ReLU 这类激活函数的伸缩等价性 (Positive scaling equivariance)。
卷积层和全连接层,本质上都是加权求和 (线性映射),因此都满足下式:
(注意这个式子的 必须是正数)

对于卷积来说,在卷积核上乘以放缩系数,等效于在输出上乘以同样的放缩系数。全连接层同理。(简单起见,上图中的 bias 被省略了)
如果卷积后跟着一个类 ReLU 的激活函数 (ReLU、LeakyReLU 等),那么 (2) 式也是成立的,因为 ReLU 这类激活函数本质上也是分段线性的。
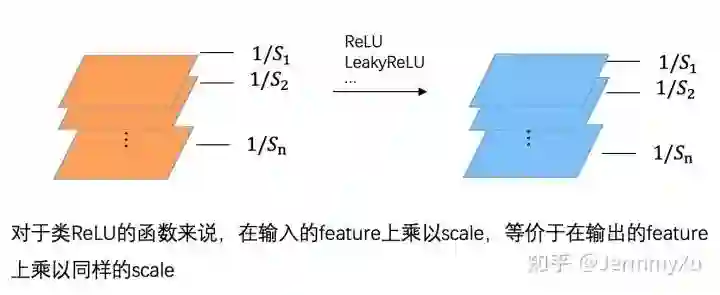
其实不只是 ReLU,任何分段线性的函数,都满足 Positive scaling equivariance。不过由于我们大部分时候使用的都是类 ReLU 的函数,所以这里就不再延伸了。
有了以上这些性质后,我们就可以在下一个卷积核上,乘以一个逆放缩系数,从而抵消第一个卷积核放缩的影响,实现计算上的等效性。
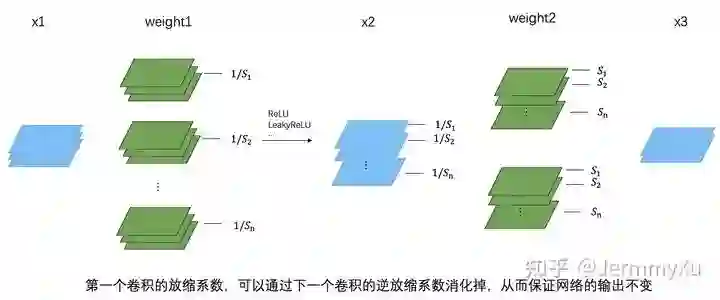
这一切成立的前提都在于 conv 和类 ReLU 函数满足公式 (2),从而可以把缩放系数等价地作用到下一层输入上,并进一步被下一层卷积的逆缩放系数吸收掉。需要注意的是,第一个卷积的缩放系数是乘在每个 kernel 上,而第二个卷积的逆缩放系数则是乘在每个 kernel 的 channel 上的。
这个过程总结一下就得到了论文中的公式:
如何找到放缩系数S
下一步就是如何找出合适的放缩系数 。
回到开头,我们在 weight 上乘以 的目的是为了让不同 kernel 之间的数值尽可能相同,从而达到均衡化。为此,论文定义了一个指标来描述这种均衡化的程度 (称为均衡化系数):
这里面, 表示第一个卷积核的第 i 个 kernel 的数值范围, 则表示第一个卷积核整体的数值范围。理想情况下,当然是每个 kernel 的数值范围都近似整个卷积核的数值范围 (即 的数值越大),均衡化的程度越好。
不过,由于我们把缩放的代价转移到了下一个卷积核上了,因此,我们同时要让这种代价越小越好。所以,对于下一个卷积核来说,它那些被缩放的权重也应该尽可能地均衡。
需要注意的是,在计算下一个卷积核的均衡化系数时,不能像第一个卷积核一样每个 kernel 单独计算,而应该把相同缩放系数的通道重新排列后,再按照前者的方式计算。(只是求解缩放系数的时候需要这么处理,正常卷积运算还是按照原来的卷积核来算)
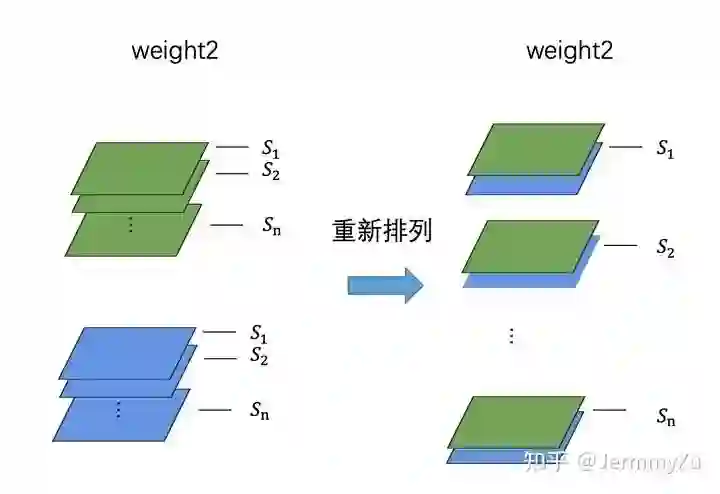
这种处理方法在数学优化以及代码实现上都能带来极大的方便。卷积核重新排列后,第二个卷积核的 kernel 数就和第一个相同了。
由此,论文给出了最终的优化函数:
这个式子翻译成人话就是,第一个卷积核和第二个卷积核 (重排后),它们每个 kernel 的均衡化系数要尽可能大,而让所有 kernel 的系数之和最大的那个缩放系数 ,就是我们想要的。
论文只针对对称量化求解这个函数,非对称量化结果也是一样的。具体求解过程在论文附录里面已经给出了,感兴趣的同学可以自行参考。实在看不懂的话,也不用过分纠结,毕竟求解一个数学问题是数学家要做的事,作为工程师,我们要做的是在了解原理的情况下把想法实现。
这里直接给出最终的答案:
这就是每个 kernel 最优的放缩系数了。
至此,两个卷积核的 equalization 算法可以通过下面的代码实现:
def equalize(weight1, bias1, weight2):
# 重排列
weight2 = weight2.permute(1, 0, 2, 3)
out_channel = weight1.shape[0]
for i in range(out_channel):
r1 = compute_range(weight1, i) # 计算kernel数值范围
r2 = compute_range(weight2, i)
s = r1 / sqrt(r1 * r2)
weight1[i] = weight1[i] * (1. / s)
weight2[i] = weight2[i] * s
bias1[i] = bias1[i] * (1. / s)
# 调整回之前的数据排布
weight2 = weight2.permute(1, 0, 2, 3)
return weight1, weight2
在实际操作中,我们会以两个相邻的 conv 为一组 (比如 conv1、conv2 为一组,conv2、conv3 为一组),按顺序逐个计算每一组的缩放系数,逐层逐层地做 weight equalize 直到结尾。
另外,我们上面的讨论都忽略了卷积里面 bias 的影响。论文提到,如果 ,那么第一个卷积的 bias 相当于被放大了,这种情况下会导致 activation 里面某些 channel 的数值也被放大 (类似于形成某种 biases),使得 activation 的 channel 之间也变得不够均衡化。因此,论文提出一种方法,可以把这个 biases 吸收掉 (Absorbing high biases)。
不过,论文对这种方法做了一个很严格的假设,作者假设 activation 会经过 batchnorm 层,使得数值分布接近高斯分布。但在实际情况中,这个假设过于严格,并非每个卷积层之后都会跟上一个 BN 层。因此,我觉得这个方法局限性比较大,不够通用,这里就不过多介绍了。
Bias Correction
前面提到,量化可能会破坏模型的数值分布,使得输出结果产生一个偏移 (biased),因此需要对这个偏移做一点矫正。
假设原始全精度模型的权重是 ,而带了量化误差的权重是 (这里的权重是将 进行量化后再反量化得到的,熟悉 量化训练 的同学应该不陌生)。由于 bias 量化引起的误差一般较小,一般不考虑,因此,可以大致估算出量化导致的误差偏移为:
表示从几个样本上计算得到的均值,又称期望,而 。
算出误差 后,我们可以从卷积或者全连接层的 bias 里面减掉这个误差,这样一来,就通过 bias 把这个偏移抵消掉,因此把这种方法称为 bias correction。
在手头上有数据集的情况下,我们可以从数据集里面拿出 个样本,然后,分别跑一遍全精度模型和量化模型 (这里是量化后再反量化的权重,同时做了 weight equalization),针对每一层输出,按照公式 (10) 计算出偏移后,再从对应层的 bias 上减掉这个偏移即可。需要注意的是,后面层在计算误差时,要等前面层已经做了 bias correction 后再进行,防止前面层已经矫正的偏移量传导到后面的层。
如果手头上没有数据,而网络里面刚好使用了 BatchNorm,那就又到了论文秀 Data-Free 的时间了。
根据期望的性质 ,由于 是可以根据权重计算的,因此只要知道 ,即输入的期望即可。那该如何在没有输入数据的情况下,得到输入的期望呢?论文假定,对于某一层 Conv 层,它的前一层跟着一个 BN 层和一个类 ReLU 的激活函数:

我们只要算出 ReLU 的输出的均值,那就相当于我们得到了所要求的 Conv 的输入均值 。这里起关键作用的是 BN,我们知道,BN 里面有两个参数: 和 ,它们表示 scale 和 shift,但同时它们还包含另一层物理意义,即均值和方差。换句话说,上面这幅图里面, 的均值就是 。
所以,如果没有中间的 ReLU 函数的话,我们就可以直接用 BN 的参数 作为 了。而如果 ReLU 存在的话,就需要考虑 ReLU 这类函数对数据分布的影响。论文在附录里面用了较大篇幅推出了 ReLU 后的均值:
对推导过程感兴趣的同学,可以自行查阅论文附录。同样地,如果你看了之后一阵眩晕,也不用太强迫自己一定要看懂,毕竟公式推导是数学家的事,工程师要做的是把搭建数学和现实之间的桥梁,把它们实现出来。
实验
这里摘取部分我比较关注的实验结果。
首先是 weight equalize + per-layer 和 per-channel 量化的效果对比,毕竟用 weight equalize 就是希望用 per-layer 达到或接近 per-channel 的效果:
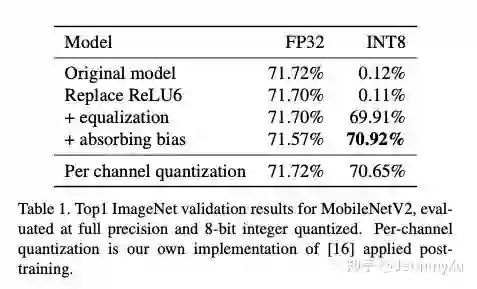
从 ImageNet 分类这个任务来看,在 MobilenetV2 这个网络上,weight equalize 和 per-channel 量化效果相当了。
我们也可以直观地感受下加上 weight equalize 后,权重是如何变化的。下图里面,左图是 MobilenetV2 里面,某个可分离卷积不同 kernel 的数值分布,右图是用上 weight equalize 后的数值分布,可以明显看到,用上 weight equalize 后,数值范围从 -50~100 的区间缩小到了 -0.75~0.75 的区间,这也正是 per-layer 量化时希望看到的结果:
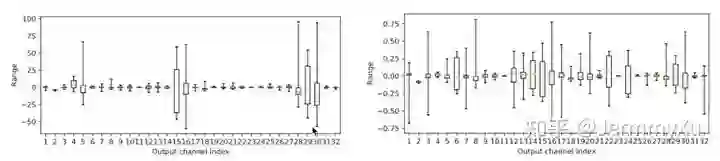
此外,我关注的另一个实验是,如果我们把卷积 kernel 中,那些大的 range 直接截断一部分,强制让每个 kernel 的数值接近,这样能不能取得好的结果呢?论文做的实验是强行把 kernel 的数值范围截断到 [-15, 15] 之间,然后对比和 weight equalize 的效果:
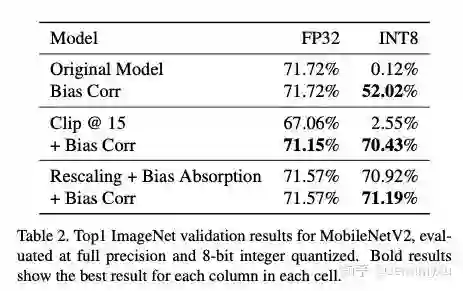
从结果来看,强行对 kernel 的数值进行截断,在没有重新训练的情况下,虽然全精度模型还能维持在 67% 的准确率上 (全精度只有 71%),但量化后还是凉凉。如果截断到更小的范围,全精度的准确率应该要下降更多了,那量化后更没法比了。
论文还做了目标检测和分割的实验,结论基本类似,这里不再赘述。
不过,Bias Correction 对 weight equalize 的加持作用好像不明显啊。反倒是剪枝 (Clip@15) 和直接 per-layer 量化的情况中能带来很大的收益。这倒是给我带来一些启发,也许在一些模型剪枝压缩的任务中,可以考虑用上 Bias Correction。
总结
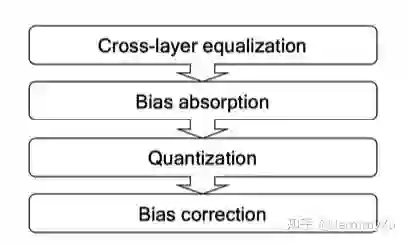
这篇文章主要介绍了高通 Data-Free 论文中的两个神技:Weight Equalization 和 Bias Correction。通过这些技巧,可以在卷积 (或者全连接层) 的 kernel 数值差异较大的情况下,用 per-layer 量化达到 per-channel 的效果。算法流程可以概括为下图:
上文介绍了高通 Data-Free Quantization 的基本思想,但我在代码实现的时候发现有个问题没有解决,因此这里对前文打个补丁 (果然没有落实到代码层面都不能说自己看懂了论文)。
Depthwise Conv如何equalize
之前的文章给出了 weight equalize 的代码
def equalize(weight1, bias1, weight2):
# 重排列
weight2 = weight2.permute(1, 0, 2, 3)
out_channel = weight1.shape[0]
for i in range(out_channel):
r1 = compute_range(weight1, i) # 计算kernel数值范围
r2 = compute_range(weight2, i)
s = sqrt(r1 * r2) / r1
weight1[i] = weight1[i] * (1. / s)
weight2[i] = weight2[i] * s
bias1[i] = bias1[i] * (1. / s)
# 调整回之前的数据排布
weight2 = weight2.permute(1, 0, 2, 3)
return weight1, bias1, weight2
仔细看了上图代码的读者可能会发现:这段 equalize 的代码对可分离卷积 (depthwise conv) 好像不适用。
确实是这样的,上面这段代码只适用于普通的卷积。如果第二个 conv 是可分离卷积的话,由于它的 input channel 是 1,因此在循环里面,weight2 是会越界的。
高通在论文里面避开了这个问题,但其实可分离卷积才是需要 weight equalize 的地方。(太鸡贼了)
不过,好在高通自家的 AIMet 工具中已经落地了这套算法,所以在代码中可以了解到实际情况是怎么处理的。
首先,在 AIMet 中有这样一段代码 (https://github.com/quic/aimet/blob/develop/TrainingExtensions/torch/src/python/aimet_torch/cross_layer_equalization.py#L157 ,这个链接随着代码更新可能会变化)
@staticmethod
def convert_layer_group_to_cls_sets(layer_group):
"""
Helper function to convert a layer group to a list of cls sets
:param layer_group: Given layer group to conver
:return: List of cls sets
"""
cls_sets = []
prev_layer_to_scale = layer_group.pop(0)
while layer_group:
next_layer_to_scale = layer_group.pop(0)
if next_layer_to_scale.groups > 1:
if layer_group: # 如果第二个卷积是depthwise conv,则会继续找到下一个conv,三个为一组
next_non_depthwise_conv_layer = layer_group.pop(0)
cls_sets.append((prev_layer_to_scale, next_layer_to_scale, next_non_depthwise_conv_layer))
prev_layer_to_scale = next_non_depthwise_conv_layer
else:
cls_sets.append((prev_layer_to_scale, next_layer_to_scale))
prev_layer_to_scale = next_layer_to_scale
return cls_sets
这段代码会找到相邻的 conv,将他们组成一组后再做 weight equalize。如果是普通的卷积,则把相邻的两个 conv 作为一组进行 equalize,而如果第二个 conv 是 depthwise conv,则需要继续找到下一个相邻的卷积,然后三个一组 (conv, depthwise conv, conv),一起 equalize。
从代码中变量名的命名,以及之后 equalize 的代码也可以看到,高通默认这里面的卷积不包括分组卷积 (所以要么 group = 1,要么就是彻底的 depthwise conv),同时,高通也默认,如果遇到 depthwise conv,那紧跟在它后面的卷积一定是个普通的卷积 (即 group=1),否则之后做 equalize 时就会报错。(私以为,这跟 weight equalize 在数学上的优化过程有关,如果没有满足这些条件,可能求解不出合适的缩放因子)。
找到这一组一组的卷积对后,就要开始做 weight equalize 了。这里也分两种情况,如果是两个普通的卷积为一组,那代码和前面的截图是一样的。而如果是三个卷积一组,根据官方给出的代码,可以总结为下面这张图:
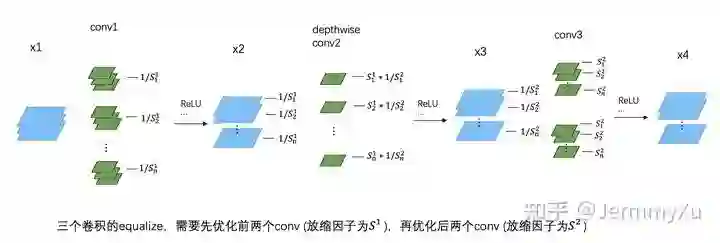
跟之前 equalize 的区别是,这里有两个缩放因子 和 。需要先用 对前两个 conv 进行 equalize,然后再用 对后两个 conv 进行 equalize。而且由于中间 depthwise conv 的特殊性,在 equalize 的时候不需要对它的 weight 进行重排 (关于重排,请参考上一篇文章),只需要在后面的 equalize 中对第三个 conv 进行重排即可。
这两个缩放因子的计算方法和论文里介绍的没有本质区别,这里就不纠结数学上的细节了,直接给出答案:
其中, 、 、 分别是三个卷积 weight 中第 个 kernel 的数值范围大小 (第三个卷积的 weight 需要重排)。
Talk is cheap,show you the code:
def equalize(weight1, bias1, weight2, bias2, weight3):
# 重排列
weight3 = weight3.permute(1, 0, 2, 3)
out_channel = weight1.shape[0]
S1, S2 = [], []
# 计算放缩系数
for i in range(out_channel):
r1 = compute_range(weight1, i) # 计算kernel数值范围
r2 = compute_range(weight2, i)
r3 = compute_range(weight3, i)
s = r1 / pow(r1 * r2 * r3, 1. / 3)
S1.append(s)
s = pow(r1 * r2 * r3, 1. / 3) / r3
S2.append(s)
# 对前两个conv进行equalize
for i in range(out_channel):
weight1[i] = weight1[i] * (1. / S1[i])
bias1[i] = bias1[i] * (1. / S1[i])
weight2[i] = weight2[i] * S1[i]
# 对后两个conv进行equalize
for i in range(out_channel):
weight2[i] = weight2[i] * (1. / S2[i])
bias2[i] = bias2[i] * (1. / S2[i])
weight3[i] = weight3[i] * S2[i]
# 调整回之前的数据排布
weight3 = weight3.permute(1, 0, 2, 3)
return weight1, bias1, weight2, bias2, weight3
顺便,我们看看高通官方 AIMet 的代码是怎么做的 (下一篇文章我会尝试用 pytorch fx 实现一下)。
在 AIMet 中,会先在 python 层面收集网络中的卷积,把它们组成一对一对,再通过 pybind 把卷积的 weight 和 bias 传递到 C++ 中进行 equalize。这篇文章主要看看 C++ 里面是如何实现我上面这段 equalize 代码的。
下面这段代码摘自 AIMet (https://github.com/quic/aimet/blob/develop/ModelOptimizations/DlEqualization/src/CrossLayerScaling.cpp#L93)
AimetEqualization::CrossLayerScaling::RescalingParamsVectors
CrossLayerScaling::scaleDepthWiseSeparableLayer(AimetEqualization::EqualizationParams& prevLayer, AimetEqualization::EqualizationParams& currLayer, AimetEqualization::EqualizationParams& nextLayer) {
const int ndims = 4;
int N = prevLayer.weightShape[0]; // output channels
// 获取三个卷积的weight和bias数据
cv::Mat weightTensor1 = cv::Mat(ndims, (int*) &prevLayer.weightShape[0], CV_32F, prevLayer.weight);
cv::Mat biasTensor1;
if (!prevLayer.isBiasNone)
biasTensor1 = cv::Mat(N, 1, CV_32F, (float*) &prevLayer.bias[0]);
cv::Mat weightTensor2 = cv::Mat(ndims, (int*) &currLayer.weightShape[0], CV_32F, currLayer.weight);
cv::Mat biasTensor2;
if (!currLayer.isBiasNone)
biasTensor2 = cv::Mat(N, 1, CV_32F, (float*) &currLayer.bias[0]);
cv::Mat weightTensor3 = cv::Mat(ndims, (int*) &nextLayer.weightShape[0], CV_32F, nextLayer.weight);
// 第三个卷积kernel重排
cv::Mat flippedWeightTensor3 = TensorOperations::swapFirstTwoAxisIn4dMat(weightTensor3);
// 计算缩放因子
RescalingParams* pReScalingMats = ScaleFactorCalculator::ForDepthWiseSeparableLayer(weightTensor1, weightTensor2, flippedWeightTensor3);
// 对前两个conv进行equalize
for (size_t s = 0; s < pReScalingMats->scalingMatrix12.total(); ++s) {
// Scaling Weight Matrix of prev layer with S12
cv::Mat w1PerChannel = TensorOperations::getDataPerChannelIn4dMat(weightTensor1, s, AXIS_0);
w1PerChannel = w1PerChannel * (1.0f / pReScalingMats->scalingMatrix12.at<float>(s));
// Scaling the bias of prev layer with S12
if (!prevLayer.isBiasNone)
biasTensor1.at<float>(s) = biasTensor1.at<float>(s) * (1.0f / pReScalingMats->scalingMatrix12.at<float>(s));
// Scaling Weight Matrix of curr layer with S12
cv::Mat w2PerChannel = TensorOperations::getDataPerChannelIn4dMat(weightTensor2, s, AXIS_0);
w2PerChannel = w2PerChannel * pReScalingMats->scalingMatrix12.at<float>(s);
}
// 对后两个conv进行equalize
for (size_t s = 0; s < pReScalingMats->scalingMatrix23.total(); ++s) {
// Scaling Weight Matrix of prev layer with S23
cv::Mat w2PerChannel = TensorOperations::getDataPerChannelIn4dMat(weightTensor2, s, AXIS_0);
w2PerChannel = w2PerChannel * (1.0f / pReScalingMats->scalingMatrix23.at<float>(s));
// Scaling the bias of curr layer with S23
if (!currLayer.isBiasNone)
biasTensor2.at<float>(s) = biasTensor2.at<float>(s) * (1.0f / pReScalingMats->scalingMatrix23.at<float>(s));
// Scaling Weight Matrix of curr layer with S23
cv::Mat w3PerChannel = TensorOperations::getDataPerChannelIn4dMat(flippedWeightTensor3, s, AXIS_0);
w3PerChannel = w3PerChannel * pReScalingMats->scalingMatrix23.at<float>(s);
}
// 调整回之前的数据排布
cv::Mat(TensorOperations::swapFirstTwoAxisIn4dMat(flippedWeightTensor3)).copyTo(weightTensor3);
// return pReScalingMats as vectors
CrossLayerScaling::RescalingParamsVectors scalingVectors;
scalingVectors.scalingMatrix12.assign(pReScalingMats->scalingMatrix12.begin<float>(),
pReScalingMats->scalingMatrix12.end<float>());
scalingVectors.scalingMatrix23.assign(pReScalingMats->scalingMatrix23.begin<float>(),
pReScalingMats->scalingMatrix23.end<float>());
return scalingVectors;
}
上面关键步骤我加了注释,可以看到和我前面给出的代码基本是一样的流程。
然后是具体计算缩放因子的代码 (https://github.com/quic/aimet/blob/develop/ModelOptimizations/DlEqualization/src/ScaleFactorCalculator.cpp#L90)
AimetEqualization::RescalingParams* ScaleFactorCalculator::ForDepthWiseSeparableLayer(const cv::Mat& weightTensor1, const cv::Mat& weightTensor2, const cv::Mat& weightTensor3)
{
AimetEqualization::RescalingParams* reScalingMats = new RescalingParams;
// 省略若干代码....
// 分别计算三组weight里面每个kernel的数值范围
cv::Mat rangeVec1 = TensorOperations::computeRangeAlongFirstAxis(weightTensor1);
cv::Mat rangeVec2 = TensorOperations::computeRangeAlongFirstAxis(weightTensor2);
cv::Mat rangeVec3 = TensorOperations::computeRangeAlongFirstAxis(weightTensor3);
// 三次开方计算缩放系数
cv::Mat cubeRootMat;
// perform element-wise multiplication on range vectors and find sqrt
cv::pow((rangeVec1.mul(rangeVec2).mul(rangeVec3)), 1.0f / 3, cubeRootMat);
reScalingMats->scalingMatrix12 = cv::Mat::ones(1, rangeVec1.total(), FLOAT_32_TYPE);
reScalingMats->scalingMatrix23 = cv::Mat::ones(1, rangeVec2.total(), FLOAT_32_TYPE);
// 计算第一个缩放因子
for (size_t s = 0; s < rangeVec1.total(); ++s) {
if ((rangeVec1.at<float>(s) != 0) && (rangeVec2.at<float>(s) != 0) && (rangeVec3.at<float>(s) != 0)) {
reScalingMats->scalingMatrix12.at<float>(s) = (rangeVec1.at<float>(s)) * (1.0f / cubeRootMat.at<float>(s));
}
}
// 计算第二个缩放因子
for (size_t s = 0; s < rangeVec2.total(); ++s) {
if ((rangeVec1.at<float>(s) != 0) && (rangeVec2.at<float>(s) != 0) && (rangeVec3.at<float>(s) != 0)) {
reScalingMats->scalingMatrix23.at<float>(s) = (cubeRootMat.at<float>(s)) * (1.0f / rangeVec3.at<float>(s));
}
}
return reScalingMats;
}
参考
-
Same, Same But Different - Recovering Neural Network Quantization Error Through Weight Factorization -
https://zhuanlan.zhihu.com/p/104052236 -
https://github.com/quic/aimet
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

