【CVPR2020】多模态社会媒体中危机事件分类

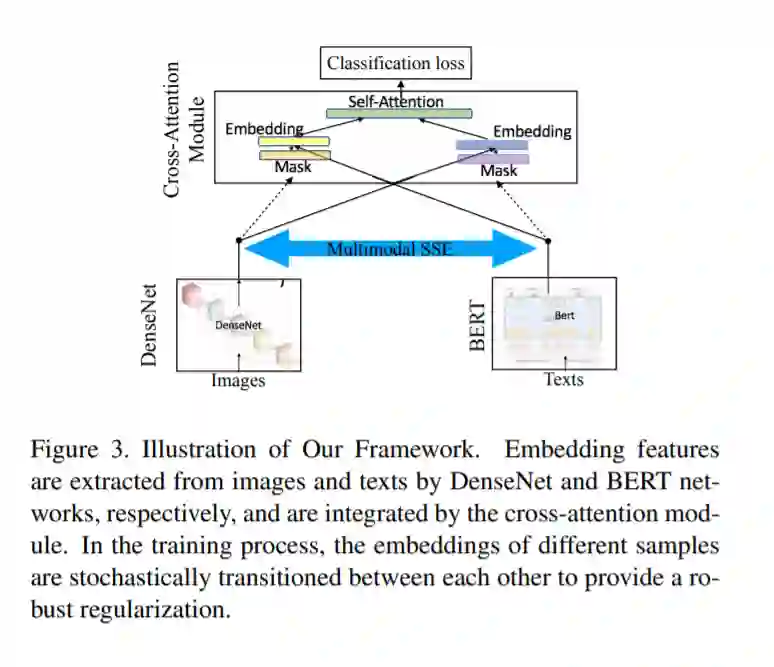
图像分类和自然语言处理的最新发展,加上社交媒体使用的快速增长,使得实时检测世界各地突发事件的技术取得了根本性的进步。应急响应就是这样一个可以从这些进展中获益的领域。通过每分钟处理数十亿的文本和图像,可以自动检测事件,从而使应急响应人员能够更好地评估快速发展的情况并相应地部署资源。到目前为止,该领域的大多数事件检测技术都集中在图像或文本方法上,这限制了检测性能并影响了向危机响应团队传递信息的质量。在本文中,我们提出了一种新的多模态融合方法,利用图像和文本作为输入。特别地,我们介绍了一个交叉注意力模块,它可以在一个样本的基础上从弱模态中过滤没有信息和误导的成分。此外,我们采用了一种基于多模态图的方法,在训练过程中随机转换不同多模态对的嵌入,以更好地规范学习过程,并通过从不同的样本构造新的匹配对来处理有限的训练数据。结果表明,我们的方法在三个与危机相关的任务上比单模态方法和强多模态基线有较大的优势。
https://www.zhuanzhi.ai/paper/484e527e6d6575cb5781d0cdcae5781b
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MCE” 就可以获取《多模态社会媒体中危机事件分类》专知下载链接



登录查看更多
相关内容
Arxiv
5+阅读 · 2018年9月6日
Arxiv
4+阅读 · 2018年5月24日




相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2018年9月6日
Arxiv
4+阅读 · 2018年5月24日