BERT遇上知识图谱:预训练模型与知识图谱相结合的研究进展
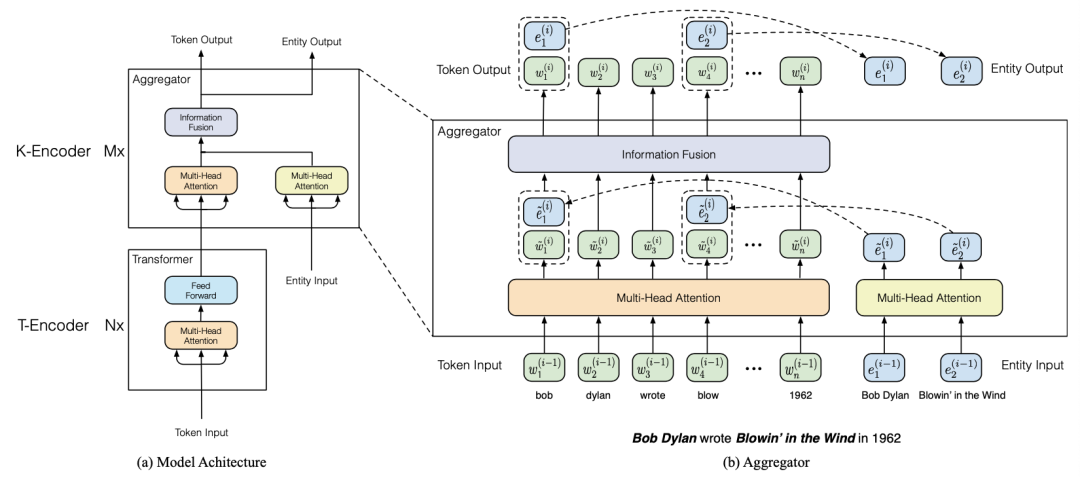
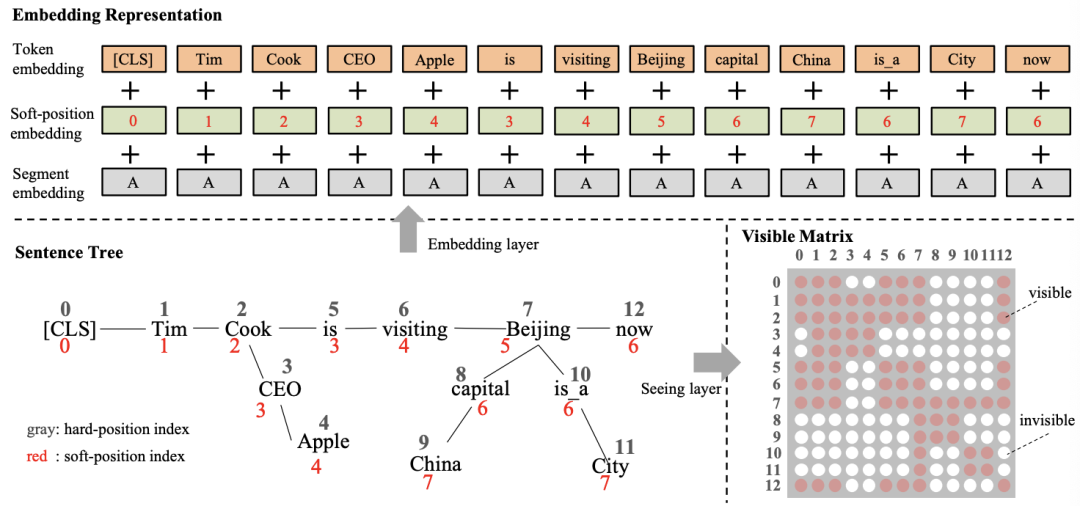
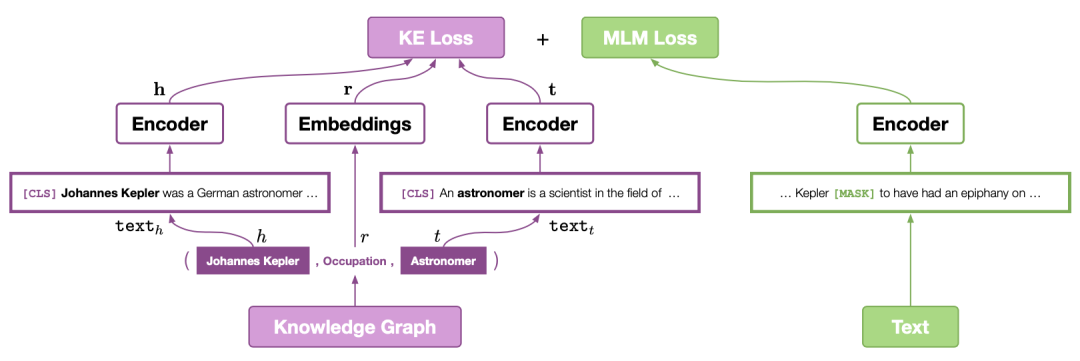
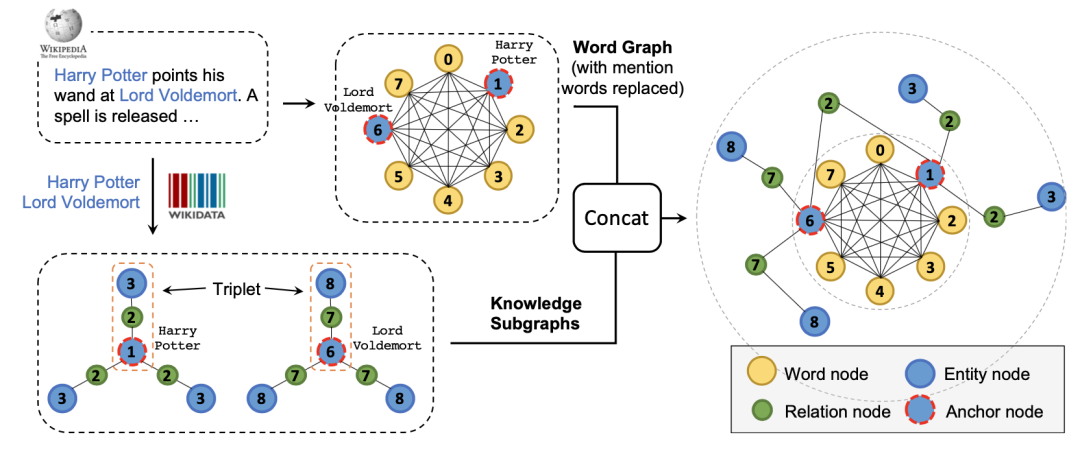
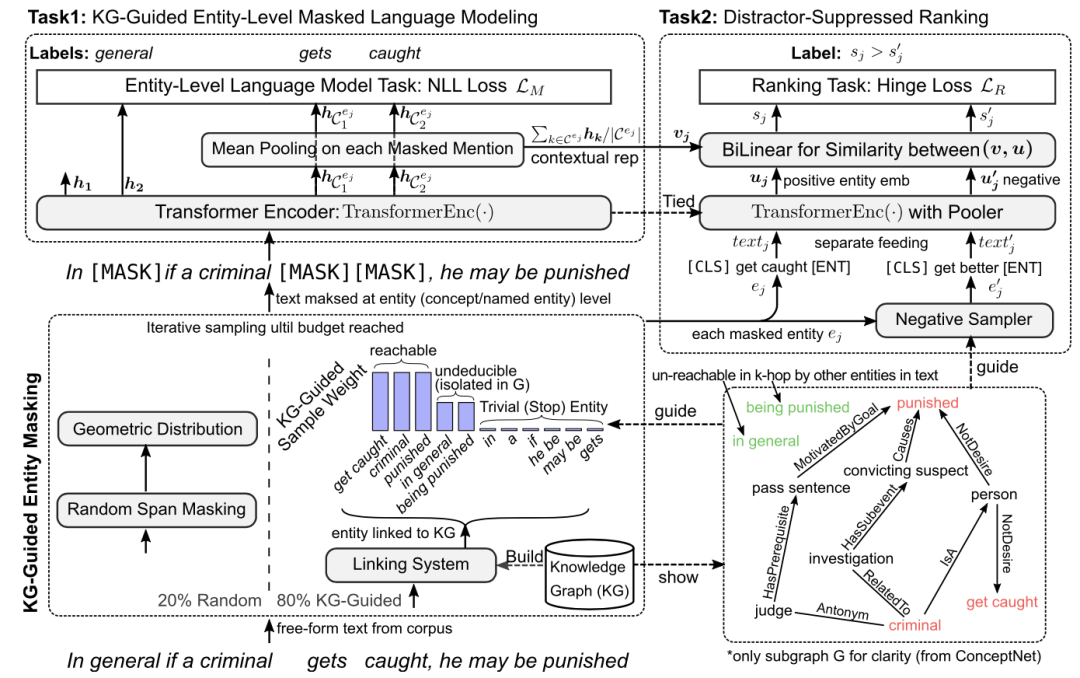
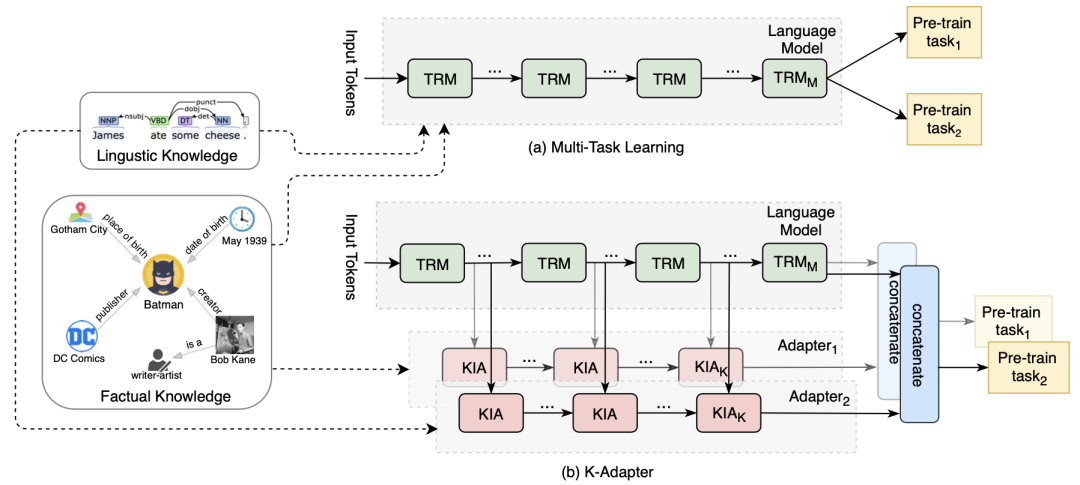
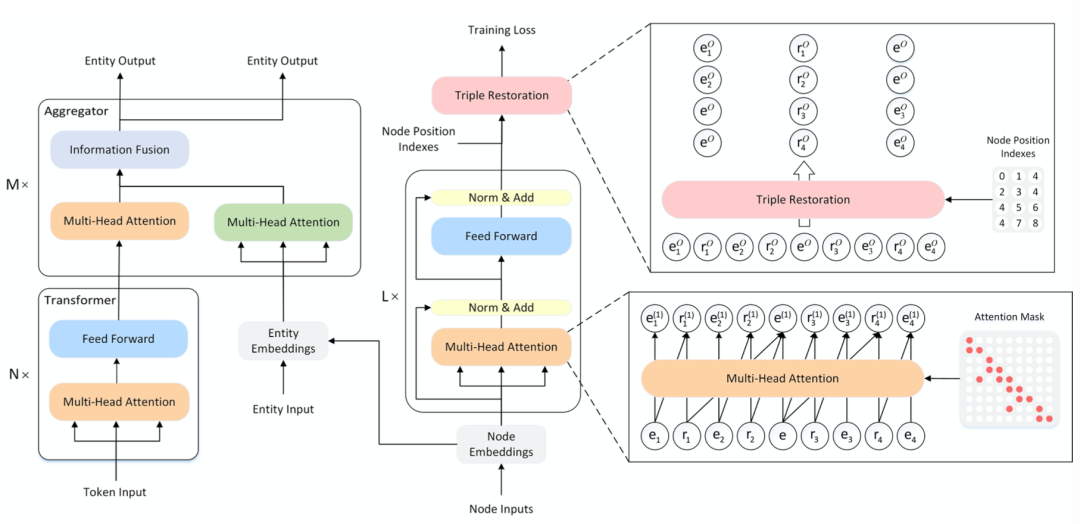
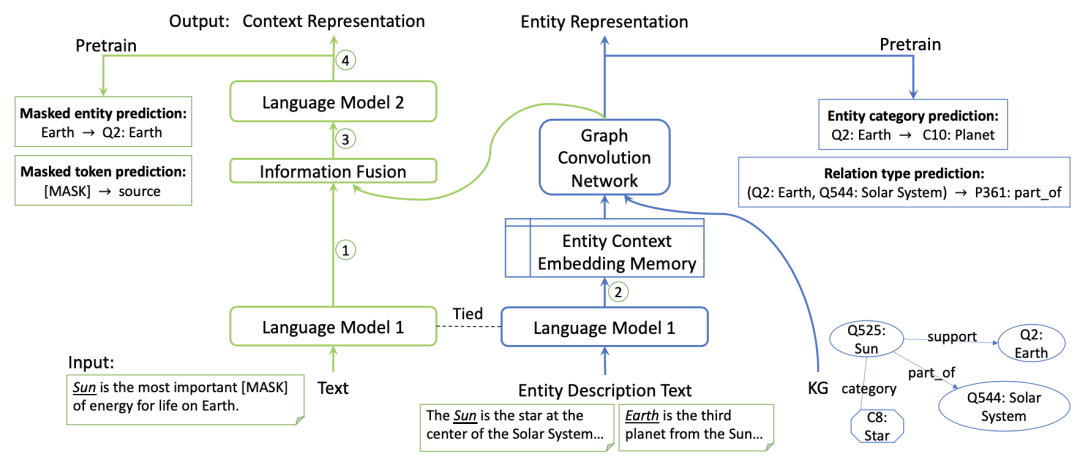
8、《JAKET: Joint Pre-training of Knowledge Graph and Language Understanding》


登录查看更多
相关内容
专知会员服务
79+阅读 · 2019年12月29日
Arxiv
0+阅读 · 2021年1月27日
Arxiv
11+阅读 · 2020年7月31日
Arxiv
15+阅读 · 2020年2月28日
Arxiv
7+阅读 · 2019年9月17日
Arxiv
6+阅读 · 2019年8月21日
Arxiv
5+阅读 · 2019年5月20日
Arxiv
7+阅读 · 2019年2月3日





相关VIP内容
专知会员服务
79+阅读 · 2019年12月29日
相关资讯
相关论文
Arxiv
0+阅读 · 2021年1月27日
Arxiv
11+阅读 · 2020年7月31日
Arxiv
15+阅读 · 2020年2月28日
Arxiv
7+阅读 · 2019年9月17日
Arxiv
6+阅读 · 2019年8月21日
Arxiv
5+阅读 · 2019年5月20日
Arxiv
7+阅读 · 2019年2月3日