首次突破30FPS!清华、天大和卡迪夫联合提出基于单RGB相机的全新三维表示方法FOF|NeurIPS 2022

来源:新智元
本文为约4807字,建议阅读10分钟
本文介绍了
清华大学、天津大学与英国卡迪夫大学联合团队在NIPS2022的工作中提出一种高效灵活的三维几何表示——傅里叶占有率场。

随着深度学习的发展,基于单张RGB图像的人体三维重建取得了持续进展。
但基于现有的表示方法,如参数化模型、体素栅格、三角网格和隐式神经表示,难以构筑兼顾高质量结果和实时速度的系统。
针对上述问题,清华大学、天津大学与英国卡迪夫大学联合团队在NIPS2022的工作中提出一种高效灵活的三维几何表示——傅里叶占有率场(FOF)。

项目主页:http://cic.tju.edu.cn/faculty/likun/projects/FOF
方法动机
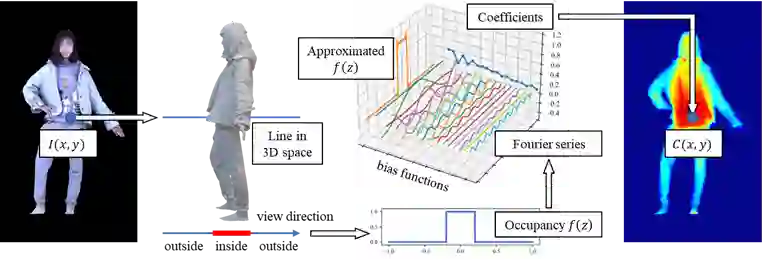
方法思路
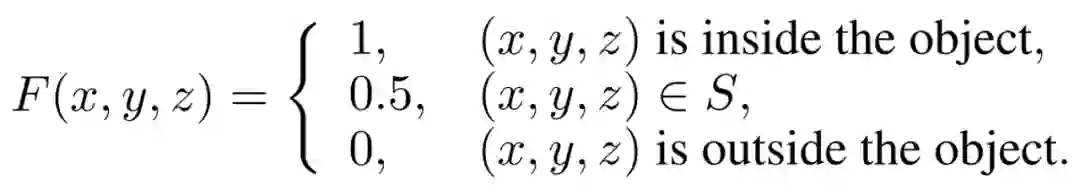
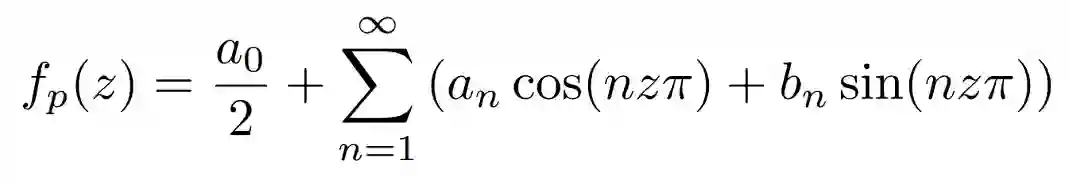

FOF与三角网格之间的转换
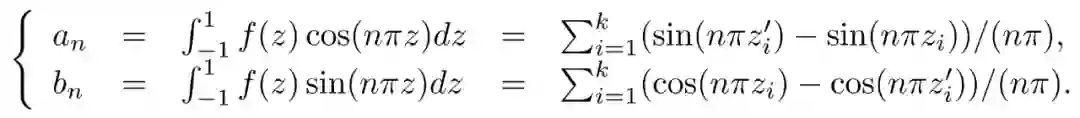
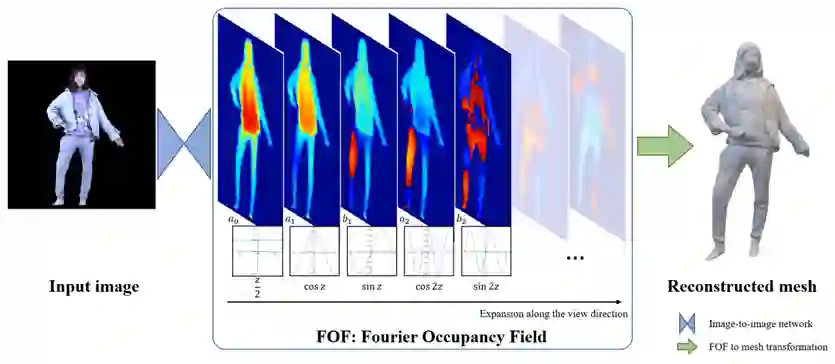
如图3所示,得益于FOF的二维形式,仅需一个image-to-image网络便可完成单图像人体三维重建。在该文的实现中,重构网络使用了HRNet-W32-V2作为backbone,并设计了简单的解码器头。
同时,得益于FOF的灵活性,参数化模型如SMPL,可直接转化为FOF一起作为网络的输入。
此外,估计出正反法线图作为网络的输入也有助于提升重建结果的精度。两种变体分别命名为FOF-SMPL和FOF-NORMAL。
需要注意的是,除网络输入的通道数外,整体网络无需再做其它修改。得益于FOF的良好特性,网络训练仅使用L1 loss作为监督便可收敛良好。
实验结果
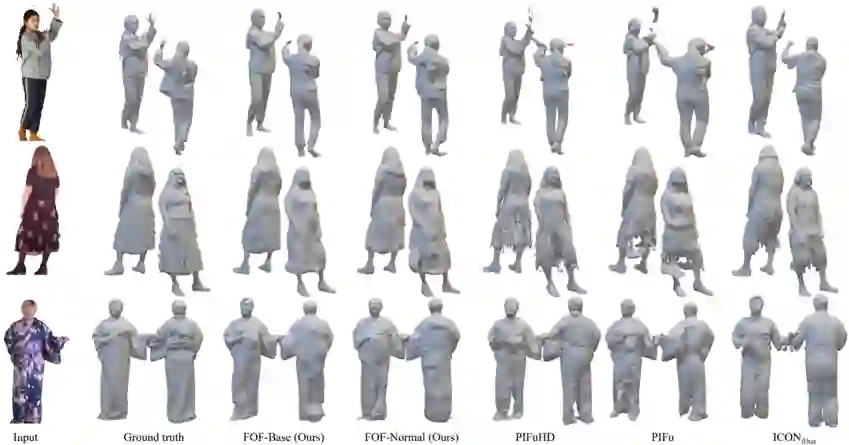
作者在Twindom和THuman2.0混合而成的数据集上与ICON[1]、PIFu[2]、PIFuHD[3]三种方法进行了对比。
如图4图5所示,在定性比较上,该方法及变种取得了高质量的重建结果。
FOF-SMPL对不同的服装、不同的姿势都非常鲁棒。该方法的运行速度远超其他方法,其中基线版本FOF-Base实现了实时重建。

在定量比较方面,如表1所示,FOF-SMPL的几何误差(倒角距离和点到面距离)最小,获得了最好的几何准确度。
同时,基线方案FOF也取得了十分优秀的结果。在视觉效果上(法线误差),FOF-SMPL仅略次于网络更加复杂,参数量更大,运行时间更长的PIFuHD。

表1 不同方法定量对比结果
作者介绍








