拨开算力的迷雾:聊聊不同 GPU 计算能力的上限

极市导读
通过深入了解自己手头 GPU 的计算能力上限,能够在买新卡时做出更理性判断。本文深入GPU架构,重点介绍了其中的ampere架构。另外,作者还对比了不同GPU之间的峰值计算能力,增加读者对硬件资源的了解。
1、前言

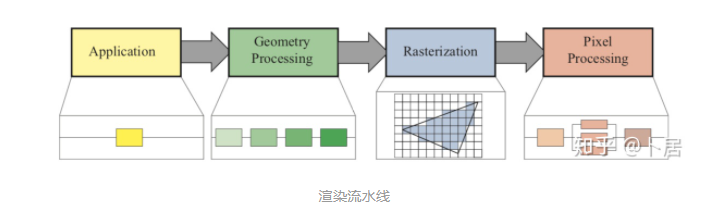
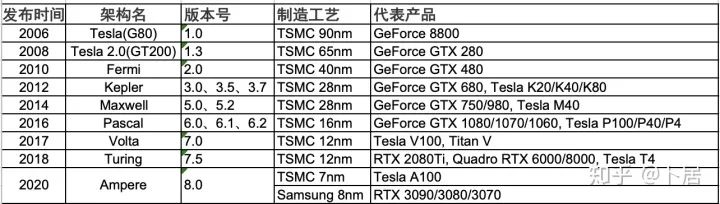
2、GPU 架构演变

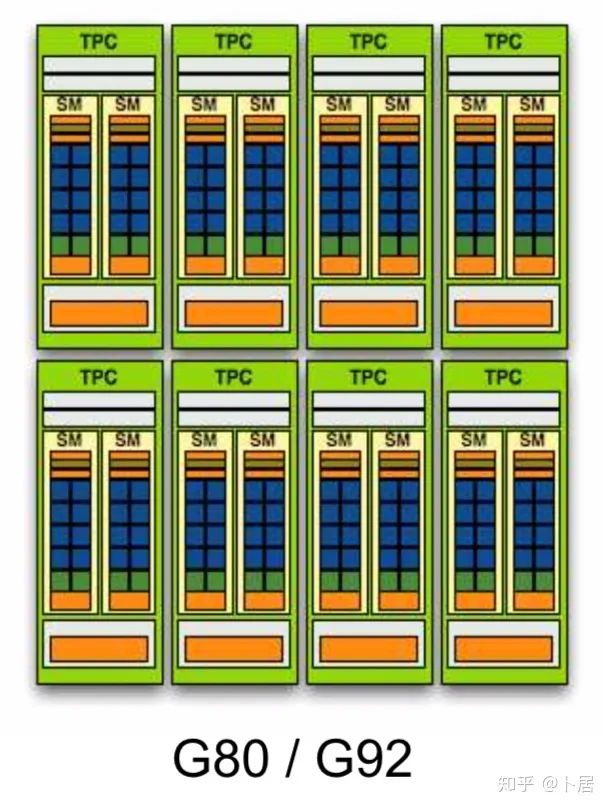
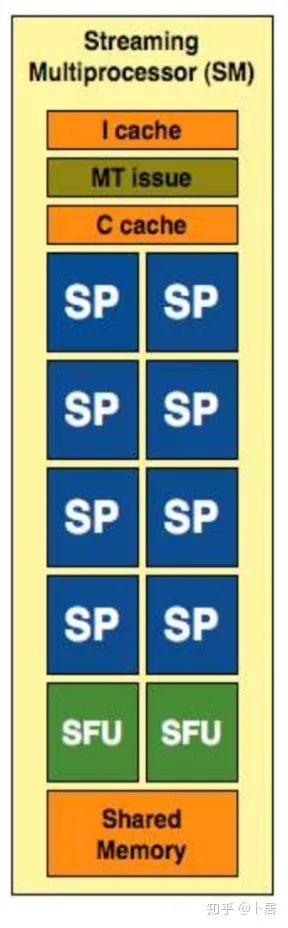
3、Ampere 架构详解
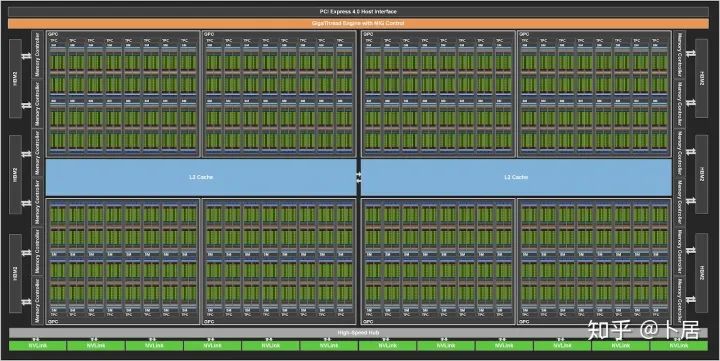
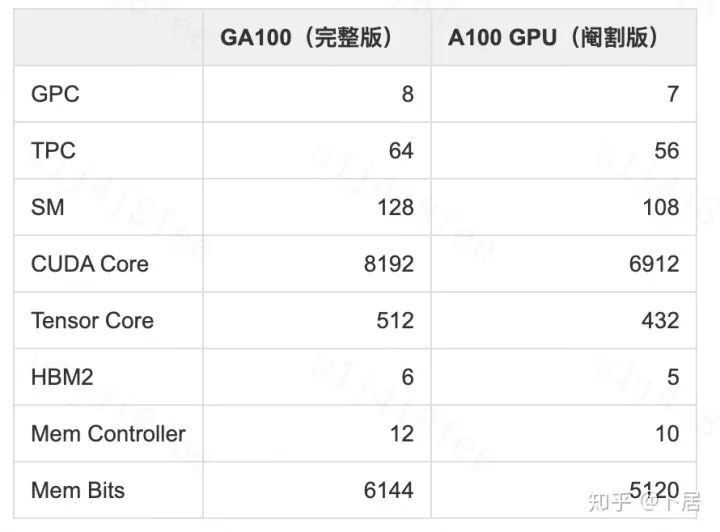
-
GPC —— 图形处理簇,Graphics Processing Clusters -
TPC —— 纹理处理簇,Texture Processing Clusters -
SM —— 流多处理器,Stream Multiprocessors -
HBM2 —— 高带宽存储器二代,High Bandwidth Memory Gen 2
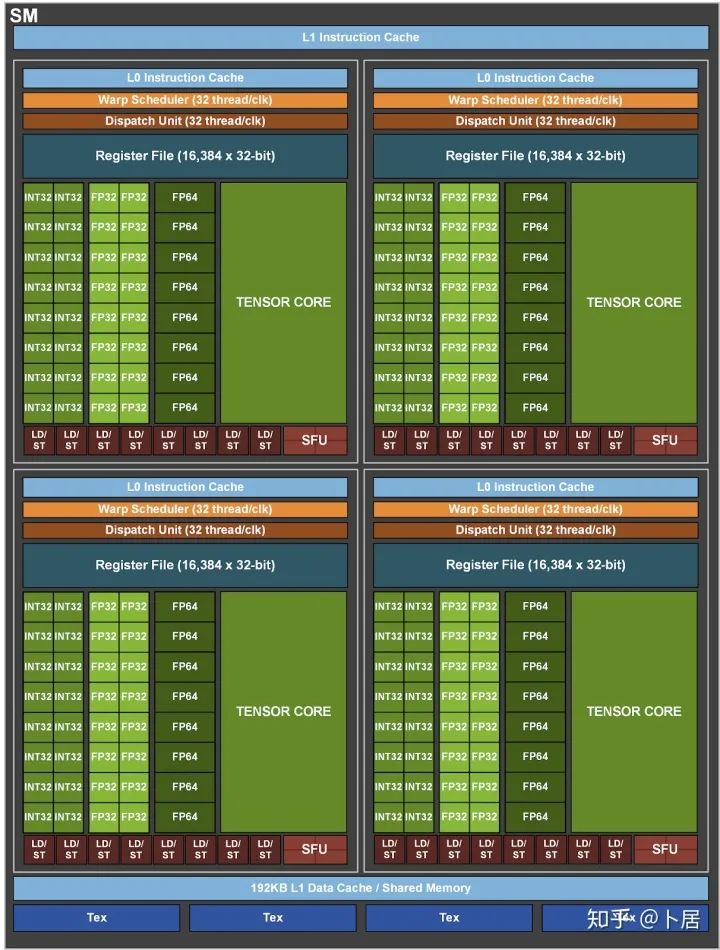
图中能看出 INT32 计算单元数量与 FP32 一致,而 FP64 计算单元数量是 FP32 的一半,这在后面峰值计算能力中会有体现。
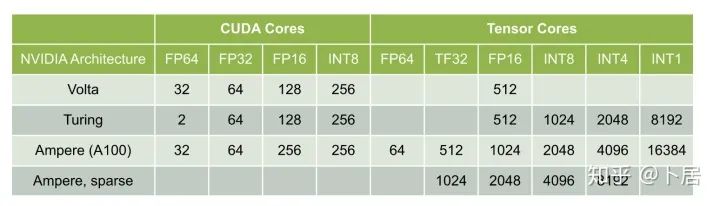
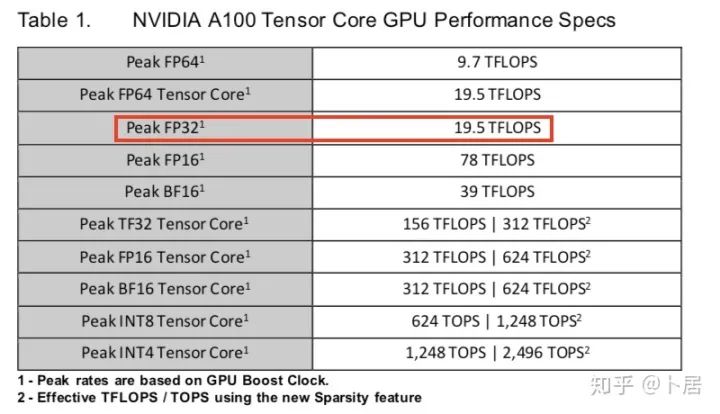
4、不同型号 GPU 峰值计算能力对比
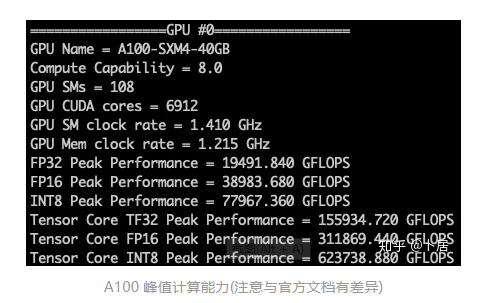
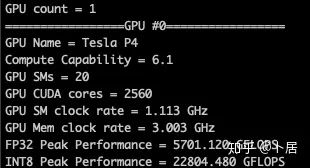
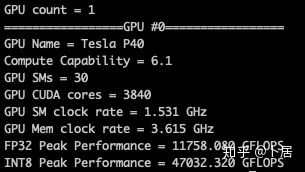
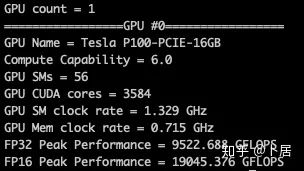
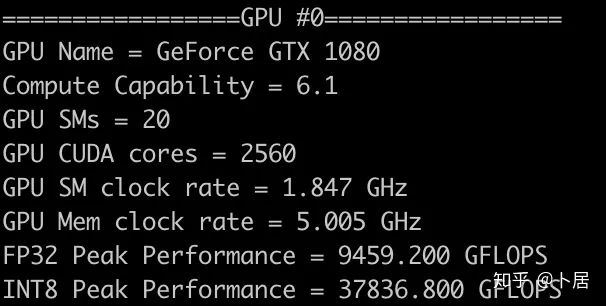
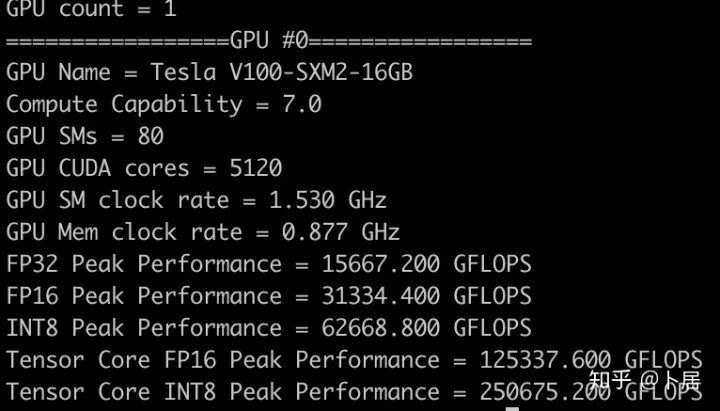
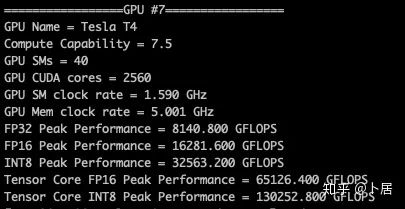
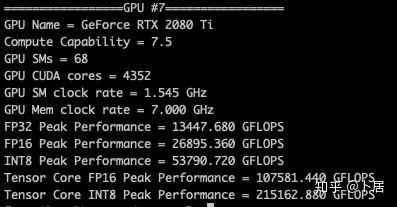
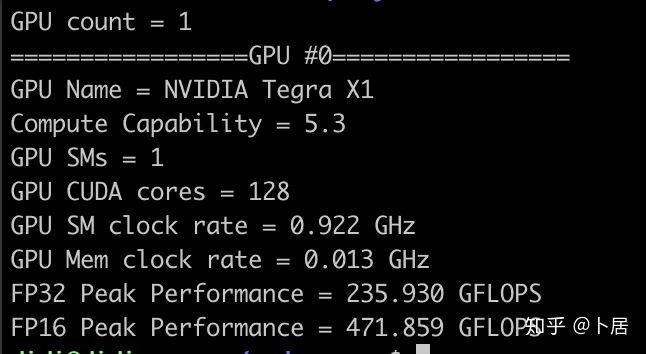
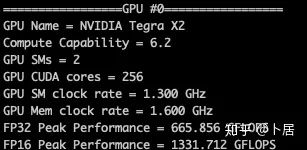
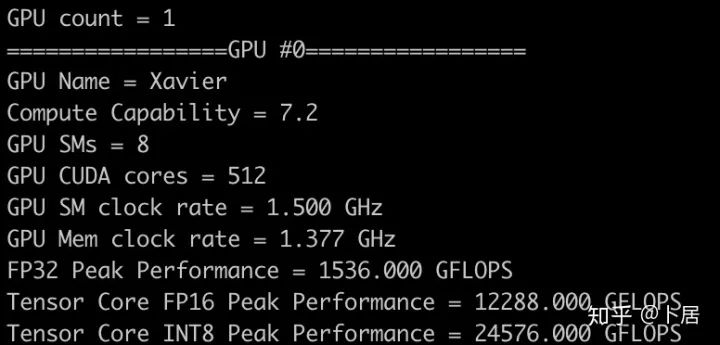
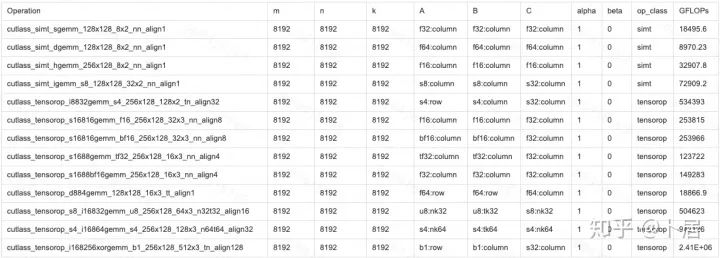
5、本文代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <cuda_runtime.h>
#define CHECK_CUDA(x, str) \
if((x) != cudaSuccess) \
{ \
fprintf(stderr, str); \
exit(EXIT_FAILURE); \
}
int cc2cores(int major, int minor)
{
typedef struct
{
int SM;
int Cores;
} sSMtoCores;
sSMtoCores nGpuArchCoresPerSM[] =
{
{0x30, 192},
{0x32, 192},
{0x35, 192},
{0x37, 192},
{0x50, 128},
{0x52, 128},
{0x53, 128},
{0x60, 64},
{0x61, 128},
{0x62, 128},
{0x70, 64},
{0x72, 64},
{0x75, 64},
{0x80, 64},
{-1, -1}
};
int index = 0;
while (nGpuArchCoresPerSM[index].SM != -1)
{
if (nGpuArchCoresPerSM[index].SM == ((major << 4) + minor))
{
return nGpuArchCoresPerSM[index].Cores;
}
index++;
}
printf(
"MapSMtoCores for SM %d.%d is undefined."
" Default to use %d Cores/SM\n",
major, minor, nGpuArchCoresPerSM[index - 1].Cores);
return nGpuArchCoresPerSM[index - 1].Cores;
}
bool has_fp16(int major, int minor)
{
int cc = major * 10 + minor;
return ((cc == 60) || (cc == 62) || (cc == 70) || (cc == 75) || (cc == 80));
}
bool has_int8(int major, int minor)
{
int cc = major * 10 + minor;
return ((cc == 61) || (cc == 70) || (cc == 75) || (cc == 80));
}
bool has_tensor_core_v1(int major, int minor)
{
int cc = major * 10 + minor;
return ((cc == 70) || (cc == 72) );
}
bool has_tensor_core_v2(int major, int minor)
{
int cc = major * 10 + minor;
return (cc == 75);
}
bool has_tensor_core_v3(int major, int minor)
{
int cc = major * 10 + minor;
return (cc == 80);
}
int main(int argc, char **argv)
{
cudaDeviceProp prop;
int dc;
CHECK_CUDA(cudaGetDeviceCount(&dc), "cudaGetDeviceCount error!");
printf("GPU count = %d\n", dc);
for(int i = 0; i < dc; i++)
{
printf("=================GPU #%d=================\n", i);
CHECK_CUDA(cudaGetDeviceProperties(&prop, i), "cudaGetDeviceProperties error");
printf("GPU Name = %s\n", prop.name);
printf("Compute Capability = %d.%d\n", prop.major, prop.minor);
printf("GPU SMs = %d\n", prop.multiProcessorCount);
printf("GPU CUDA cores = %d\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount);
printf("GPU SM clock rate = %.3f GHz\n", prop.clockRate/1e6);
printf("GPU Mem clock rate = %.3f GHz\n", prop.memoryClockRate/1e6);
printf("FP32 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2);
if(has_fp16(prop.major, prop.minor))
{
printf("FP16 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 2);
}
if(has_int8(prop.major, prop.minor))
{
printf("INT8 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 4);
}
if(has_tensor_core_v1(prop.major, prop.minor))
{
printf("Tensor Core FP16 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 8);
}
if(has_tensor_core_v2(prop.major, prop.minor))
{
printf("Tensor Core FP16 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 8);
printf("Tensor Core INT8 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 16);
}
if(has_tensor_core_v3(prop.major, prop.minor))
{
printf("Tensor Core TF32 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 8);
printf("Tensor Core FP16 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 16);
printf("Tensor Core INT8 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 32);
}
}
return 0;
}
nvcc -I/usr/local/cuda/include -L/usr/local/cuda/lib64 -lcudart -o calc_peak_gflops calc_peak_gflops.cpp
export PATH=/usr/local/cuda/bin:$PATH
./calc_peak_gflops
6、后记
推荐阅读



登录查看更多
相关内容

Arxiv
3+阅读 · 2018年4月23日





相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年4月23日