
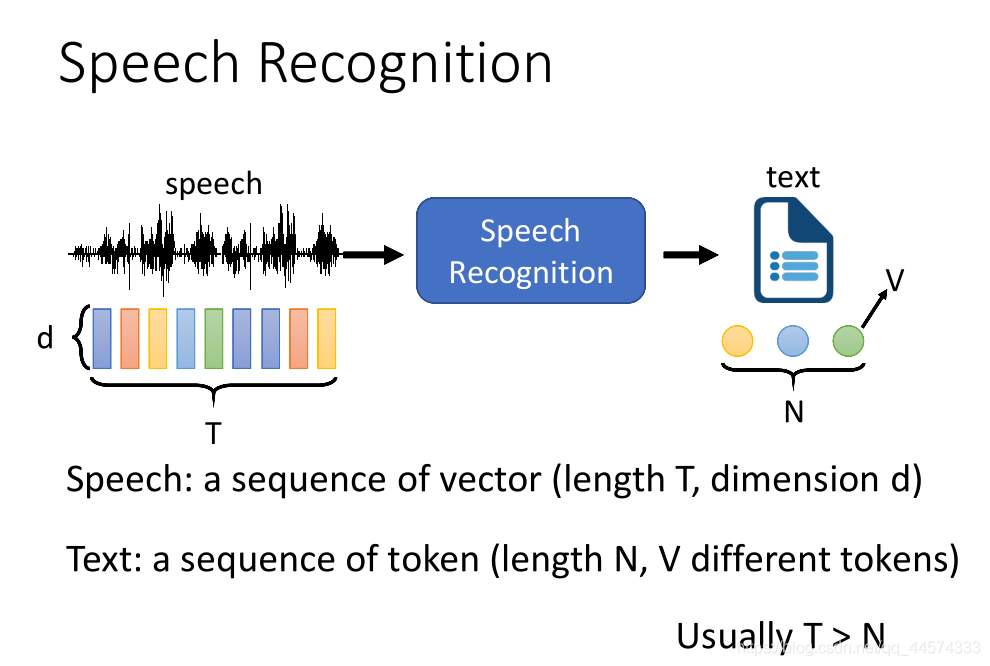
语音识别系统中的输入和输出
P2 是课程安排,无需阐述
Speech Recognition 语音辨识 输入输出部分
输入:语音,形式化表示为 长度为T,维度为d 的向量
输出:文字,形式化表示为 长度为N 的tokens序列,词表(tokens总数)为V
输入:Acoustic Feature 声学特征
如何将一段语音转换为长度为T,维度为d 的向量,详细可参考《数位语音处理》第七章
类似于word2vec里的window一样,从头取25ms的语音,将这25ms的语音转换为一个向量frame(音框),之后往右移10ms的框框,则可以得到在1s内将得到100个frames(注意,相邻的frame将会有重叠,且数据量很大)
其中这个frame形式有三种:
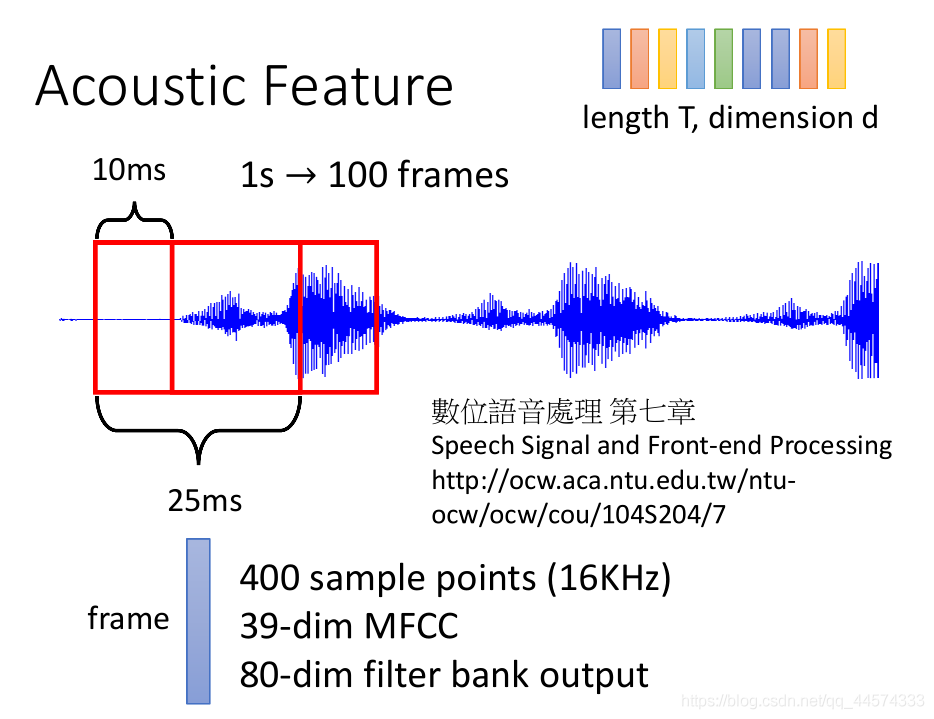
传统的400 个sample点(假设16KHz的声波,则25ms内便有400个点,400个数值)
39维的MFCC,不细讲可参考下图
80维的filter bank output,近年来流行的,取代
根据统计ICASSP、ASRU,得到 :
| Frame | Probability |
|---|---|
| filter bank output | 75% |
| MFCC | 18% |
| waveform | 4% |
| spectrogram | 2% |
| other | 1% |
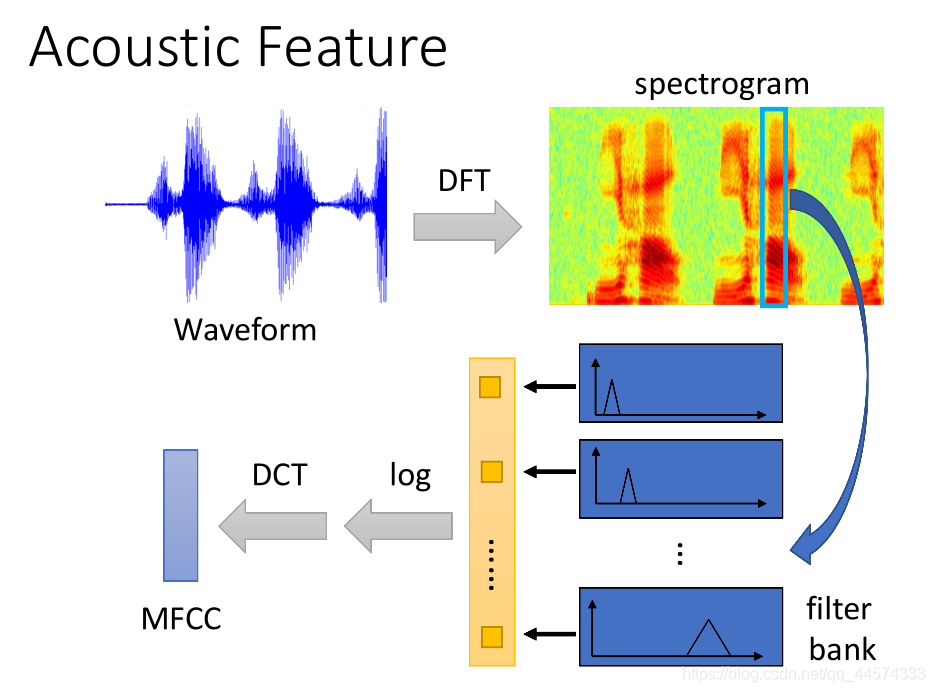
(一个window的音波做DFT (离散傅里叶变换Discrete Fourier Transform)得到spectrogram,这一步很重要,因为声音讯号颇为复杂,同样人听起来一样的声音其声音讯号可能会有大不同,而经过DFT得到spectrogram是与同义的声音讯号有较强的相关性,之后再通过filter bank(根据哺乳类声学器官设计的filter),通常会再取log(log很重要,讯号处理中的log很巧妙),再经过离散余弦变换DCT(Discrete Cosine Transform)得到最终的MFCC)
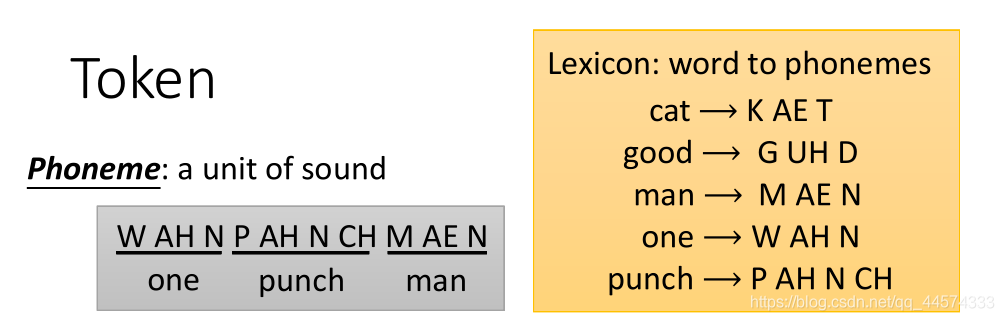
输出:Token
与传统的文字处理不同,一般的文字处理都以词表中的词为token,而声学中有四种主流的token形式
Phoneme: a unit of sound 音位,音素 (发音的基本单位)
可将模型的输出选为phoneme,如读取语音one punch man 输出 W AH N P AH N CH M AE N ,再根据Lexicon(可视为“词汇表”)还原文本,而这个Lexicon是需要一定的语言学家提供,很多语言是找不到Lexicon的Grapheme:the smallest unit of a writing system (书写的最小单位,如英文字母、中文汉字)
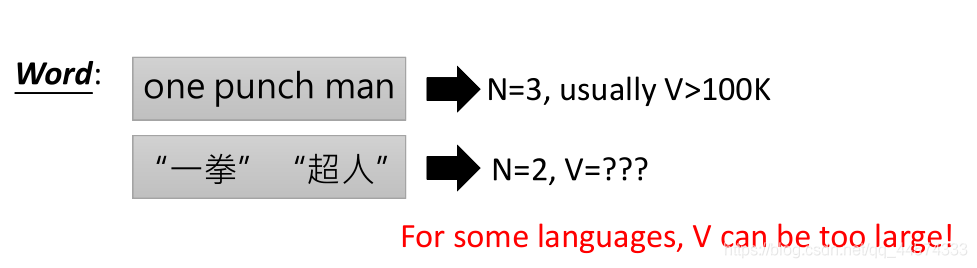
依旧是 one punch man的语音输入,可将输出选为one_punch_man, 26个英文字母加空格和其他特殊符号,对于中文可以直接使用字且无空格的要求。Word:词
直接输出词,对于很多语言来说,词有很多,如中文,常用字较少,但词可谓无数Morpheme:the smallest meaningful unit (<word,>grapheme) 词素(有意义的词根及其扩展)
输出词根+词缀,而得到这样的数据有两种方法,其一linguistic语言学家、其二statistic统计得到。Bytes
这是最新的一种token方式,根据UTF-8编码通过语音预测bytes,其优点在语言无关性。



根据统计:
| Tokens | Probability |
|---|---|
| Grapheme 字母、汉字 | 41% |
| Phoneme 音素 | 32% |
| Morpheme 词根、缀 | 17% |
| Word 词 | 10% |
数据集

模型
将在下一篇中解释模型

欢迎大家评论指正,共同学习。



