YouTube视频推荐系统为什么那么强?看了这篇文章你就知道了
选自Medium
作者:Tim Elfrink
机器之心编译
参与:张倩
作为全球主流的视频平台,谷歌旗下视频网站 YouTube 的成功离不开精准的视频推荐系统。 YouTube 的推荐系统有何亮点? 他们解决了哪些问题? 在一篇 RecSys 2019 论文中,谷歌研究者对这些问题做出了解释。 来自荷兰的一位数据科学家对论文的内容进行了总结。
论文地址:https://dl.acm.org/citation.cfm?id=3346997
Youtube 的推荐系统解决了什么问题?
在 Youtube 上观看视频时,页面上会展示用户可能喜欢的视频推荐列表。该论文聚焦于以下两大目标:
1)需要优化不用的目标。他们没有定义确切的目标函数,而是将目标函数分为「参与度」(点击量、花的时间)目标和「满意度」(点赞量、踩的量)目标;
2)减少系统引入的「选择偏见」:用户通常更倾向于点开排在第一位的推荐视频,尽管后面的视频可能参与度、满意度更高。如何高效地减少这些偏见是一个亟待解决的问题。
用什么方法解决?
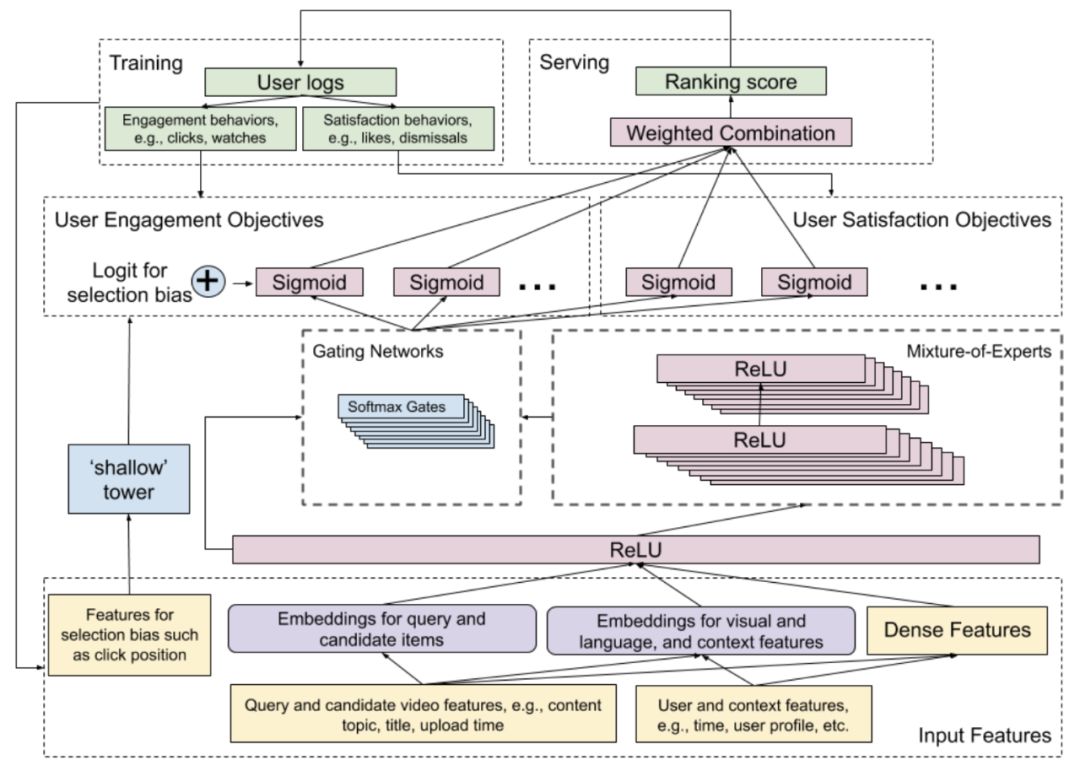
图 1:模型的完整架构。
论文中介绍的模型着眼于两个主要的目标。他们用到了一个宽度&深度模型框架 。宽度模型拥有强大的记忆能力,深度神经网络拥有泛化能力,宽度&深度模型则综合了二者的优点。宽度&深度模型会为每一个定义的(参与度和满意度)目标生成一个预测。这些目标函数可以分为二分类问题(是否喜欢某个视频)和回归问题(为视频评级)。这一模型之上还有一个单独的排序模型。这只是一个输出向量的加权组合,它们是不同的预测目标。这些权重是手动调整的,以实现不同目标的最佳性能。此外,研究者还提出了结对、列表等先进的方法,以提升模型的性能,但由于计算时间的增加,这些方法没有被应用到生产中。
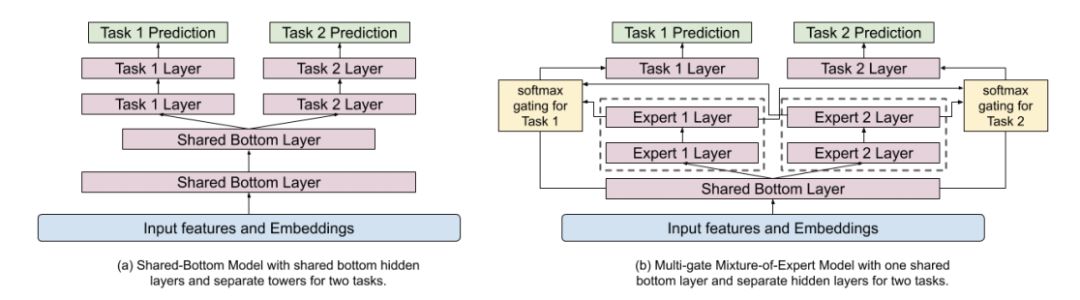
图 2:用 MMoE 替换 shared-bottom 层。
在宽度&深度模型的深层部分,研究者利用了一个多任务学习模型 MMoE。现有视频的特征(内容、标题、话题、上传时间等)以及正在观看的用户的信息(时间、用户配置文件等)被用作输入。MMoE 模型可以在不同的目标之间高效地共享权重。共享的底层(shared bottom layer)被分为多个专家层,用于预测不同的目标。每个目标函数都有一个门函数(gate function)。这个门函数是一个 softmax 函数,接收来自原始共享层和不同专家层的输入。该 softmax 函数将决定哪些专家层对于不同的目标函数是重要的。如下图 3 所示,不同的专家层对于不同目标的重要程度存在差别。如果与 shared-bottom 架构相比,不同的目标相关度更低,则 MMoE 模型中的训练受到的影响更小。
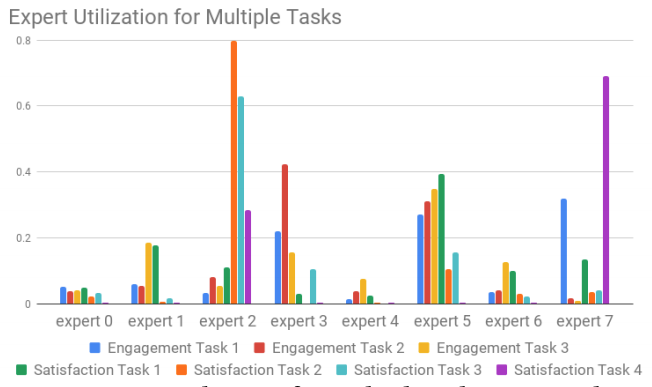
图 3:在 Youtube 多个任务中的专家层应用情况。
该模型的宽度部分致力于解决系统中由视频位置带来的选择偏见问题。研究者将该部分称为「浅塔」(shallow tower),它可以是一种简单的线性模型,使用简单的特征,如视频被点击时所处的位置、用户观看视频使用的设备等。「浅塔」的输出与 MMoE 模型的输出相结合,这也是宽度&深度模型架构的关键组成部分。
如此一来,模型将更加关注视频的位置。在训练过程中,dropout 率被定为 10%,以防止位置特征在模型中变得过于重要。如果不用宽度&深度模型,而是将位置添加为一个特征,模型可能根本就不会注意到这个特征。
结果
该论文的结果表明,用 MMoE 替换 shared-bottom 层可以在参与度(观看推荐视频花费的时间)和满意度(调查反馈)两个目标中提升模型的性能。增加 MMoE 中的专家层数量和乘法的数量可以进一步提升模型的性能。但由于计算上的限制,现实部署中无法实现这一点。

表 1:MMoE 模型的 YouTube 实时实验结果。
进一步的研究结果表明,参与度度量可以通过使用「浅塔」降低选择偏见来加以改进。与只在 MMoE 模型中添加特征相比,这是一项显著的改进。
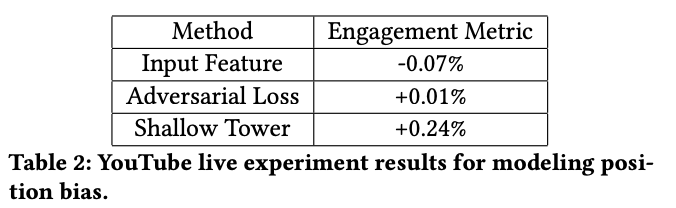
表 2:建模视频位置偏见的 YouTube 实时实验结果。
有趣之处
尽管 Google 拥有强大的计算基础设施,但在训练和成本方面仍然非常谨慎;
通过使用深度&宽度模型,你可以在设计网络时预定义一些重要特征;
当你需要多目标模型时,MMoE 模型会非常有效;
即使具有强大而复杂的模型架构,大家仍在手动调整最后一层的权重,从而根据不同的客观预测确定实际排名。
原文链接:https://medium.com/vantageai/how-youtube-is-recommending-your-next-video-7e5f1a6bd6d9




