torcs强化学习的图像生成低纬表示重建效果
在强化学习的问题中,策略网络学习到的是从状态空间到动作空间的映射。
状态空间和动作空间的大小决定了策略学习和探索的难易程度。
因此,高维的有噪音的图像作为状态输入之前需要有representation learning 的预训练的过程。首先训练一个神经网络将图像编码成有意义的低维隐变量,之后将这个训练好的网络嵌入到强化学习的策略网络之前处理图像数据。
VAE的编码器可以学习一个低维的隐变量,但是以像素级的重建误差作为损失函数,最后输出的图像真实度较低。考虑结合GAN,计算原始图像在discriminator 的某一层的输出和原始图像经过encoder->generator->discriminator 在同一层的输出的误差作为特征级重建误差。联合训练VAE和GAN。
以上训练的隐变量知识与图像相关,并不一定包含强化学习决策需要的信息,因此增加一个从隐变量到reward的输出,使隐变量也能包含强化学习需要的信息。
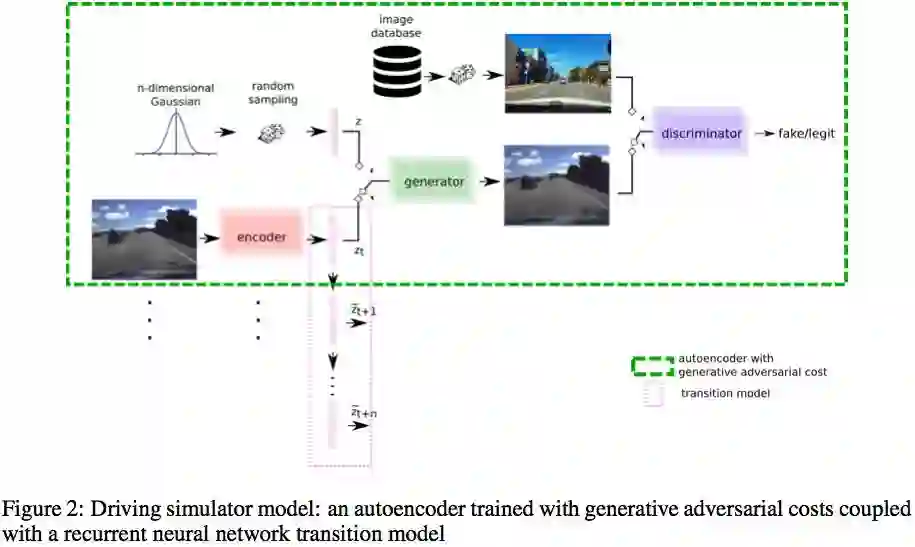
上图from commaai paper
commaai的生成模型进行生成torcs道路画面,左侧为生成图像,右侧为实际游戏图像,两个画面为一个epoch的1万次循环训练的效果,下面跨度98个epoch中挑选了部分图片;生成效果的显现很快,很快生成的图像变得很清晰,但是大概在60epoch左右图像开始变模糊,后又恢复。
1

2 出现天空

3

4

5 画面大结构出现

6

7 车的画面也生成了,右侧第一张

8

9

0

1

2

3

1

2 有些清晰了

3

4

5

6

7

8

9

0

1

2

3

4

5

6

7

招聘信息请公众号回复招聘
登录查看更多
相关内容

专知会员服务
42+阅读 · 2020年4月11日
专知会员服务
36+阅读 · 2020年3月13日
Arxiv
8+阅读 · 2018年11月21日



相关VIP内容
专知会员服务
42+阅读 · 2020年4月11日
专知会员服务
36+阅读 · 2020年3月13日
相关资讯
相关论文
Arxiv
8+阅读 · 2018年11月21日