谷歌AutoML创造者Quoc Le:未来最好的人工智能模型将由机器生成
机器之心原创
作者:Tony Peng
过去十年,谷歌在人工智能领域的重重突破,有很大一部分和 Quoc Le 有关。这位出生在越南的谷歌研究员像是一个人工智能的信徒,坚信机器学习能够解决一切让人烦恼的问题,即使存在失败的可能性,他也乐在其中。AutoML 则是他最新的研究方向,也是被认为将改变整个深度学习发展进程的技术。正如此,我们希望从和 Le 的采访中探寻围绕在 AutoML 的真相和未来。
在这场一个小时的采访里,笔者印象最深刻的是下面的两句话:1. 我们做到了自动化机器学习,之后就只是规模化的问题。2. 我预计未来两年内,至少在计算机视觉领域内,最好的网络会是 AutoML 生成的,而不是人工设计的。
作为谷歌大脑的创始成员和 AutoML 的缔造者之一,Quoc Le 算得上是人工智能研究领域的原住民了。
2011 年在斯坦福大学读博时,Le 和他的老师吴恩达以及谷歌大脑的研究人员一起,基于千万张 YouTube 图像开发了一个能够识别猫的无监督学习系统;2014 年,他将深度学习技术应用在自然语言理解任务上,提出了能将文本转换为向量表征、基于循环神经网络的 Seq2Seq 学习模型,将机器翻译的前沿水平又向前推进了一步。这为谷歌之后在自然语言机器翻译方面的突破奠定了基础。

自 2014 年以来,Le 开始将目光转向了自动化机器学习(AutoML)。构建机器学习模型的过程需要反复的人工调整:研究者会在初始的模型上尝试不同的架构和超参数,在数据集上评估模型的表现,再回头进行修改;这个过程会反复进行,直到达到最优。
Le 认为可以把它想成是一个试错问题,继而通过机器学习解决:「可以看看强化学习以及机器学习下围棋的方式,基本上就是试错。」
2016 年,Le 与一位谷歌研究者合作发表了一篇开创性的论文《Neural Architecture Search with Reinforcement Learning》。其核心思想类似于搭建积木:机器从一个定义空间中选取自己所需的组件来构建神经网络,然后使用一种试错技术,也就是—强化学习—来提升其准确度。这种方法得到了令人惊喜的结果,机器所生成的模型的表现可媲美人工调节的最佳模型。
Le 的研究成果催生了 Google Cloud AutoML,能让机器学习知识有限的开发者也能训练出高质量的模型。不出所料,AutoML 迅速成为了今年最热门的研究主题之一,科技巨头与创业公司纷纷跟随谷歌的脚步,投入这项新技术。
Google Cloud 在今年年初发布了 AutoML 视觉,之后又发布了 AutoML 翻译和语言
机器之心近日视频采访了 Quoc Le 博士。这位谦逊的 36 岁越南裔人工智能专家谈到了他的灵感来源、AutoML 背后的技术和前方的道路及其在机器学习领域内扮演的重要新角色。这位站在许多变革性技术背后的人有怎样的见解呢?请看后文。为了简洁和明晰,采访内容进行过适当编辑。
在即将于 11 月 9 日 于加利福尼亚州圣何塞举办的 AI Frontiers 会议上,Quoc Le 将发表主题为「使用机器学习自动化机器学习」的演讲,特别将关注神经架构搜索和自动数据增强 AutoAugment。
灵感
您在何时开始想要设计一种新的神经架构搜索方法?是什么启发了你?
那是在大概 2014 年的样子,这个过程随时间逐渐发生的。我是一位机器学习工程师。当你一直以来都在做神经网络方面的工作时,你会意识到很多工作都需要人工调整,也就是人们说的「超参数」——神经网络的层数、学习率、网络中所使用的层的类型。AI 研究者往往会根据某些原则开始调整,然后这些原则会随时间变得不那么有效,他们再尝试不同的策略。
我关注了 ImageNet 竞赛中的某些进展,也见证了谷歌的 Inception 网络的发展。我便开始思考我想做些什么,但那时的想法还不清晰。我喜欢卷积网络,但我不喜欢一个关于卷积网络的事实:卷积网络中的权重并不彼此共享。所以我就想,也许我应该开发一种全新的机制,能真正学会如何在神经网络中共享权重。
随着我的工作推进,我对此的直观理解也越来越多,我开始发现:研究者们所做的事情是将一些已有的构建模块组合到一起,然后尝试它们的效果。他们看到准确度有一定提升。然后就说:「很好,也许我刚引入了一个好想法。试试看保留我刚刚引入的好东西,但用某些新东西替换旧有的部分会怎样呢?」他们就这样继续这一过程,这个领域的专家可能会尝试数百种架构。
在 2016 年左右,我当时在思考如果这个过程需要如此之多的试错,那我们就应该使用机器学习来自动化,因为机器学习本身也是基于试错的。可以看看强化学习以及机器学习下围棋的方式,基本上就是试错。
我研究了做成这件事将需要多少真正的计算资源。我的想法是,如果是一个人类,那可能会需要一百个网络来试错,因为人类已经有大量直觉知识和大量训练了。如果你使用算法来做这件事,那你的速度可能会慢上一两个数量级。我认为实际上慢一两个数量级也不算太差,而且我们已经有充足的计算资源来做这件事了。所以我决定与一位培训生(Barret Zoph,现在已是谷歌大脑的一位研究者)一起启动这个项目。
我之前没想到这会如此地成功。我当时认为我们能做到的最佳结果可能是人类水平的 80%。但这位培训生非常优秀,他实际上做到了与人类媲美的水平。
许多人告诉我:「你花费了如此之多资源,就只为达到了人类水平?」但我从这个实验中看到的是现在我们可以做到自动化机器学习。这只是一个规模问题。所以如果你的规模更大,你就能得到更好的结果。我们继续开展了第二个项目,采用了甚至更大的规模并在 ImageNet 上进行了研究,然后开始得到了真正非常出色的结果。
您有这个想法有告诉 Jeff Dean 吗?他是什么反应?
嗯,他非常支持。实际上我也想感谢 Jeff Dean 在这个想法的初期所提供的帮助。
我记得在 2014 年,有一次和 Jeff 吃了一顿午餐,他也分享了非常类似的看法。他认为如果仔细了解那时候的深度学习研究者所做的事情,就会发现他们当时会花大量时间来在超参数等方面调整架构。我们认为一定存在一种自动化这一过程的方法。Jeff 喜欢扩展和自动化困难的东西,这是大多数科技人员不愿做的事情。Jeff 给我提供了鼓励,我也最终决定去做这个。

谷歌 AI 负责人 Jeff Dean
神经架构搜索与您之前的研究有何不同?
这不同于我之前在计算机视觉领域的工作。这段研究经历源自一个想法,并且也在随时间成长。我也有过一些错误想法。比如,我曾想自动化和重建卷积,但那是个错误的直觉想法。也许我应该接受卷积,然后使用卷积来构建其它东西?这对我来说是一个学习过程,但不算太坏。
技术
研究者或工程师需要哪些种类的组件来构建神经网络模型?
因应用各异,确实会有所不同,所以我们先来看看计算机视觉领域——即使是在计算机视觉领域内也有很多事物。通常而言,卷积网络会有一个图像输入,有一个卷积层,然后一个池化层,之后还有批归一化。然后还有激活函数,你还可以决定连接到新的层的 skip connection 等等。
在卷积模块内,你还有很多其它选择。比如在卷积中,你必须决定过滤器的大小:1x1? 3x3? 5x5? 你还必须决定池化和批量大小的规格。至于 skip connection,你可以选择从第一层到第十层,也可以选择从第一层到第二层。所以需要做的决定非常多,也就存在大量可能的架构。可能性也许能达到数万亿,但人类现在只会检查这些可能中的一小部分。
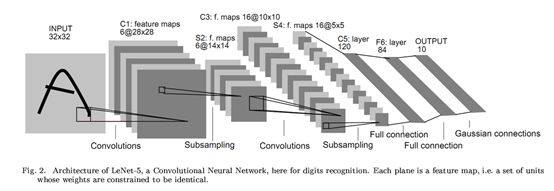
一种常见的卷积架构
您的第一篇 AutoML 相关论文是《Neural Architecture Search (NAS) with Reinforcement Learning(使用强化学习的神经架构搜索)》。自那以后,您的团队已经采用了进化算法并开始使用渐进式神经架构搜索。您能详细谈谈这些改进背后的思路吗?
在原来的论文中,我们是从强化学习开始的,因为我们直觉上认为这类似于人类的处理方法,也就是可以使用试错。但我很好奇,所以我说:「好吧,试试进化方法怎么样?」我们做了很多实验并取得了一些成功,并且认识到这个过程可以使用进化来完成,所以我们修改了核心算法。
更大的一个改变是使用了 ENAS(高效神经架构搜索)。过去,当你生成了大量架构时,每个架构的训练和评估都相对于前一代是独立的。所以一般不会共享任何先验知识或信息。假设说你确实开发了一种共享机制,你可以从之前训练的网络继承某些权重,然后就可以更快速地训练。所以我们就这样做了。
基本而言,我们的想法就是创造一个包含了所有可能性的巨型网络,然后在该网络中搜索一条路径(以最大化在验证集上的预期奖励),这就是所要寻找的架构。某些权重会在下一次实验中得到重复使用。所以会有很多权重共享。因为这种方法,我们实际上能实现很多个数量级的加速。原始的 NAS(神经架构搜索)算法要更灵活得多,但成本太高了。ENAS 基本上是一种更快的新算法,但限制也更多一点。
原始的 NAS 算法可以生成更优的架构以及更好的超参数、更好的数据增强策略、更好的激活函数、更好的初始化等等。目前我们只成功将这种新的 ENAS 算法用在了架构方面,还没用到数据增强以及优化方面。
您的意思是其它参数是人类决定的?
我们将架构搜索和数据增强确定为人类专家很难设计的两个关键领域。所以一旦你做对了这两件事,就能实现大量成果。其余的只用常见的优化技术和标准的实践方法即可。我们只关注能提供最大效益的组件的自动化。
ENAS 是一个很近期的进展。尽管我们还在做大量黑箱中的实验,但这个研究方向进展很快。
我听说有一家创业公司正使用一种名叫生成式合成(generative synthesis)的技术。另外还有使用 GAN 的?不同的搜索算法各有哪些优缺点?
我不确定有谁真在用 GAN 来做架构生成。我认为这是可能的,但我不是很了解。
进化和强化学习具有相似的通用性,但同样,如果你不做任何假设,它们的速度会非常慢。所以人们发展出了渐进式神经架构搜索的思想,即先搜索一个小组件,然后再不断增添。我认为这是一个非常好的想法。
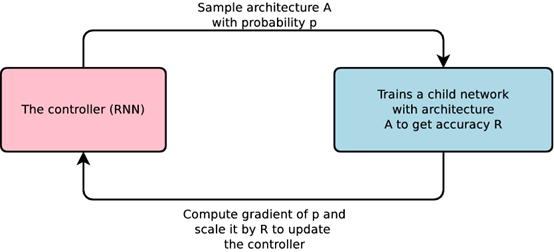
神经架构搜索概况
说到 ENAS,基本而言核心思想就是权重共享。你想开发一个大架构,然后找到一条路径。ENAS 基于一些其它思想,比如 one-shot architecture search,也就是构建多个模型,然后想办法在它们之间共享权重。我认为强化学习和进化方法的优势是它们非常灵活。它们可用于机器学习流程中任何组件的自动化。但它们也成本高昂。ENAS 和渐进式架构搜索等大多数针对特定方面的算法都会有某些前提假设,所以它们的通用性和灵活性更差,但它们一般速度更快。我对 GAN 方面不太了解。我认为人们会使用 GAN 来生成更好的图像,但我不认为人们会使用 GAN 来生成更好的架构。
迁移学习在 AutoML 技术中扮演怎样的角色?
迁移学习有两种类型。第一种是架构迁移学习,比如找到一个在图像识别数据集上的好架构之后再迁移用于目标检测。另一种迁移学习是权重迁移学习——如果你在公共数据集上训练你的网络,你会得到一个结果,然后再在你自己的数据集上再训练该网络。
让我们假设这样的情况:我们想做鲜花检测。ImageNet 有大约 100 万张图像,包含花的图像有大约 1000 张。你可以根据 ImageNet 找到最佳的架构,然后复用这些权重;或者你可以直接取一个 Inception V3 这样的先进模型,然后在 ImageNet 上训练,再在花上迁移学习,之后复用其权重。SOTA 方法是只迁移权重,因为大多数人都不做架构生成。你必须先让你的 Inception V3 或 ResNet 在 ImageNet 上训练。完成这个训练之后,你再做微调。
我想说的是,实际上你既需要架构迁移学习,也需要权重迁移学习;两者可以通过如下方式结合起来:
结合方法一:首先做架构迁移学习,然后再做权重迁移学习。
结合方法二:直接在你的数据集上进行架构搜索,并在 ImageNet 上做权重迁移学习。
结合方法三:直接使用 ResNet 和权重迁移学习。这是当前最佳的方法。
结合方法〇:只在你的目标数据集上进行架构搜索,不做迁移学习。
因数据集不同,适用的结合方法也不同,因为有的数据集更大,有的则更小。不同的结合方式是在数据集的不同侧面发挥作用。
我预测未来几年,组合方法〇(即纯粹的架构搜索)将能得到质量更好的网络。我们在这一领域做了大量研究,我们知道这种方法实际上更好。

Quoc Le 在接受机器之心视频采访期间进行板书
麻省理工学校和上海交通大学的一篇研究论文提出了一种路径层面的网络到网络变换(arXiv: 1806.02639),您怎么看?
这是个很棒的思路。在我决定研究架构搜索时我就想过尝试这一思路:首先从一个优良的初始架构开始,然后修改再修改,总是尽力做到越来越好。但我感觉这有点点胸无大志,我希望能做些更雄心勃勃的事情!
写论文的一大好处是当我们发表时,我们会发现很多人都有一样的哲学思想。而且他们确实对这些算法进行了修改,我们实际上也能从这些研究思想中学到东西,帮助改进我们自己的研究。
AutoML 的哪些部分仍需人类干预?
我们还必须做一些设计搜索空间的工作。在架构搜索方面,可以使用进化、强化学习或这种高效的算法。但我们也必须定义一个卷积网络或全连接网络的构建模块所处的空间。有些决定还是必须人来做,因为目前 AutoML 的计算能力有限。我们并不能直接搜索一切,因为那样的话搜索空间就太大了。因为这样的原因,我们必须设计一个带有所有可能性的更小的搜索空间。
深度学习仍然是一种黑箱技术。AutoML 能帮助用户更好地理解模型吗?
我们能得到一些见解。比如,这样的搜索过程会生成很多看起来类似的架构。你可以检查这些架构,然后识别出特定的模式。你也可以得出一些直觉理解,帮助你了解哪种架构对你的数据集而言最好。比如在 ImageNet 上,由 AutoML 发现的网络的层中通常都有多个分支(不同于每层仅有一个或少量分支的更传统的网络)。在分支的层面上看,很难解释发生了什么。
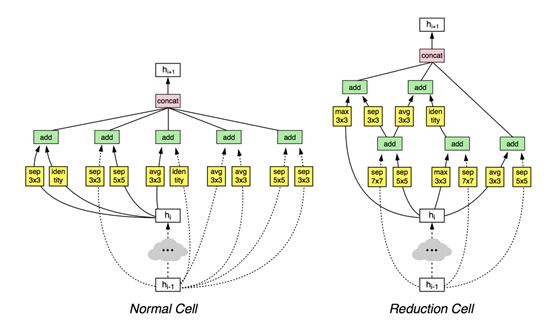
在 ImageNet 中,目标和图像的尺寸各有不同。有时候巨大醒目的目标出现在图像正中,有时候图像中的目标非常小,比如一个小零件。所以你会有不同大小的过滤器。通过组合不同的分支,能得到更好的结果。我们会继续研究这个问题。
AutoML 的挑战和未来
您认为 AutoML 研究目前所面临的最大难题是什么?
我认为未来两年中最大的难题将是如何让搜索更高效,因为我认为很多人都不想使用一百个 GPU 来解决某个小数据集的问题。所以寻找能在降低成本的同时又不影响质量的方法会成为一个非常重大的问题。
第二个大难题是如何降低设计搜索空间所需的人力工作。因为现在的搜索空间中具有某些先验的知识,所以即使我们宣称我们用 AutoML 做一切工作,特定的先验知识元素仍会进入搜索空间。我认为这还不够理想,我也想研究这个问题。
但我可以告诉你,AutoML beta 版的质量已经很好了,谷歌云的人也很满意。我不能说产品的细节,但我认为质量已经很好。而且接受情况也很棒。

参阅机器之心文章:https://www.jiqizhixin.com/articles/2018-02-06-23
在 AutoML 的鲁棒性提升方面是否还有机会?
一般而言,当我们做 AutoML 时,我们会有另外一个验证数据集。这样我们就可以不断在那个数据集上进行验证来评估质量。鲁棒性实际上已经是 AutoML 的目标函数的一部分。现在在添加约束方面,事实证明 AutoML 有能力做到,比如制作对对抗噪声更鲁棒的模型,或将其它外部约束条件添加进 AutoML 中。这是一种非常棒的能力,因为很多时候当你有新的约束条件时,人类很难找到将其植入到模型中的方法。但是 AutoML 可以使用一个奖励函数作为准确度和鲁棒性之间的权衡。然后进化,最后会找到一个在准确度和稳健性之间有良好权衡的模型。
说个案例。我们之前有位研究者在研究如何设计出更好的网络来防御对抗样本。我们在 CIFAR-10 上进行了小规模的实验。他找到了一个对对抗攻击非常稳健的网络,由于之前最佳。这个结果非常好,能做到这一点的原因是人类很难直观地想出一种防御攻击的方法。但 AutoML 不在乎,它只是尝试了一些网络,然后其中一个网络不知怎的本身就具有防御攻击的机制。
有办法有效地比较目前市面上的这些各不相同的 AutoML 解决方案吗?
可以做到。只要你有一个任务,你就应该单独创建一个数据集。你将其输入 AutoML,然后它会得出某些预测模型,然后你在你的测试集上评估这些预测模型——这个测试集应该被看作是你的基准集。在基准集上的准确度是衡量模型表现的好标准。我不能过多地评论我们的方法与市面上其它方法的比较情况,但我认为人们都可以自己去看去比较。
您认为 AutoML 能够生成下一代颠覆性网络架构吗,类似 Inception 或 ResNet?
我认为它已经做到了。我们近期使用了架构搜索来寻找可用于移动手机的更好的网络。这是一个很艰难的领域,很多人都在研究。超过 MobileNet v2 是很困难的,这是现在的行业标准。我们生成了一个显著更优的网络,在移动手机上同样速度下好 2%。
而这仅仅是个开始。我认为这样的事还会继续发生。我预计未来两年内,至少在计算机视觉领域内,最好的网络会是生成的,而不是人工设计的。
您怎么看待围绕 AutoML 的炒作?
我很难评论围绕 AutoML 的炒作,但当我看到很多人都想使用机器学习时,我认为在帮助机器学习更广泛可用方面还存在很大的能做出成绩的空间。特定的技术可能比其它一些技术炒得更凶,但我认为随着时间推移,我们能带来影响的领域将非常广阔。
很少有研究者能在机器学习领域多次取得突破。您是如何维持自己的创造力的?
首先,出色的研究者有很多,他们都非常有创造力,工作非常出色,所以我并不特殊。对于我自己,我有一些我一直很好奇并想要解决的问题,而且我非常热爱解决这些问题。我只是跟随着自己的好奇心并为世界带来了积极的影响。这是好奇心与毅力的结合。我也会在周末踢足球,而且我爱好园艺。我不知道这是否有助于我的研究工作,但这确实能帮助我放松身心。
我不得不问:您如何应对失败?
如果你热爱,那你就会坚持不懈去追寻,对吧?我非常热爱机器学习。教机器如何学习是一种做计算机编程的新方法:不用再写程序了,可以教机器来做。我从根本上喜欢这个概念。所以即便遭遇失败时,我也乐在其中!

点击「阅读原文」,查看大会官网信息。机器之心读者限时特别优惠折扣码(25% off):P25JH

