GPT-3王者来袭!1750亿参数少样本无需微调,网友:「调参侠」都没的当了

新智元报道
新智元报道
来源:arXiv等
编辑:白峰、鹏飞
【新智元导读】近日OpenAI发布GPT-3,万亿数据训练,1750亿参数,无监督学习效果接近SOTA,要做本年度最强语言模型!
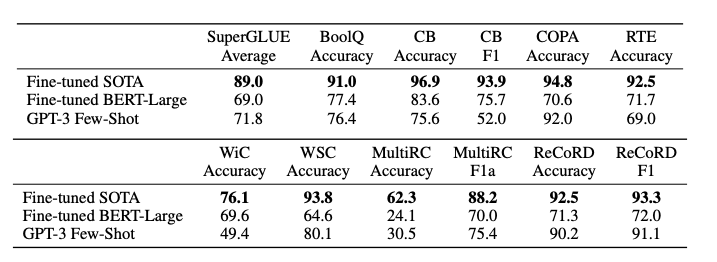
OpenAI最强预训练语言模型GPT-3周四发表在预印本 arXiv 上,1750亿参数!

GPT家族又添新

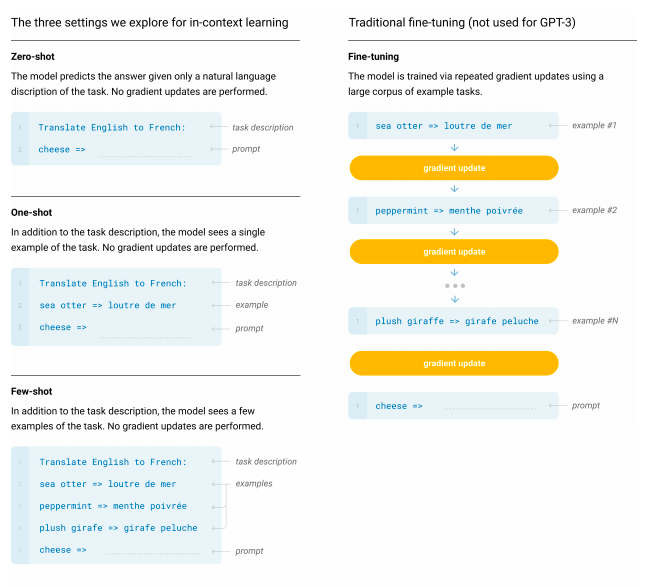
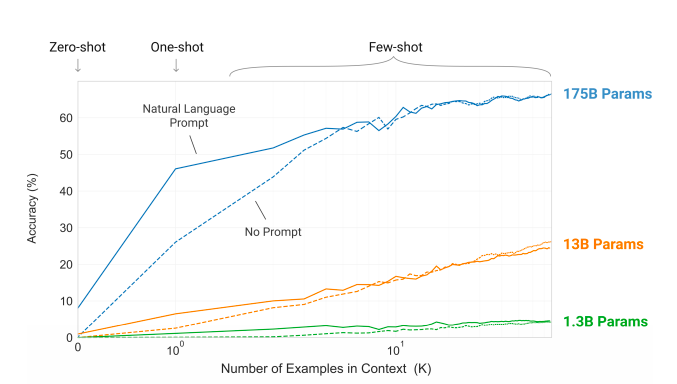
少样本学习无需微调,以后都不能自黑「调参侠」了

OpenAI这次不光拼参数量,还要拼作者数量?
OpenAI这次不光拼参数量,还要拼作者数量?



参考链接:
https://www.zhihu.com/question/398114261
https://arxiv.org/abs/2005.14165

登录查看更多
相关内容
Arxiv
5+阅读 · 2019年9月26日

相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2019年9月26日