谷歌这个大杀器要让英伟达慌了!!!
本文经AI新媒体量子位(公众号ID:qbitai )授权转载,转载请联系出处。
作者丨岳排槐
对于大多数搞深度学习的人来说,英伟达GPU之外其实没有更多选择。然而谷歌TPU芯片的出现,有望改变这一现状。
这个大名鼎鼎的AI芯片,即是谷歌各种AI应用和服务背后的支撑,也是名噪天下的AlphaGo背后的基础。碾压人类顶级围棋选手,只需要四块TPU。
但此前,很少有“外人”能一尝TPU的滋味。
在首次公布9个月后,谷歌TPU终于面向大众开放。10天前,谷歌的Cloud TPU正式发布。只需要每小时6.5美元,你也有可能用上谷歌TPU。
到底Cloud TPU实力如何?RiseML(riseml.com)最近做了一次对比评测。
云上的TPU
首先简单介绍一下测试对象。
第一代TPU面向推理,而第二代的重点是加速训练。在TPUv2的核心里,一个脉动阵列(Systolic array)负责执行矩阵乘法,这在深度学习中被大量使用。
根据Jeff Dean此前放出的PPT显示,每个Cloud TPU由四个TPUv2芯片组成。每个芯片有16GB内存和两个内核,每个内核有两个矩阵乘法单元。
两个内核能够提供45TFLOPs算力,所以每个Cloud TPU能提供180TFLOPs算力和64GB内存。作为对比,这一代英伟达V100 GPU提供125TFLOPs算力和16GB内存。

当你获得配额后,就能在谷歌云上启动Cloud TPU。无需(也没有办法)把一个Cloud TPU分配给指定的VM实例。每个Cloud TPU会有一个名字和IP地址,供用户提供TensorFlow代码。
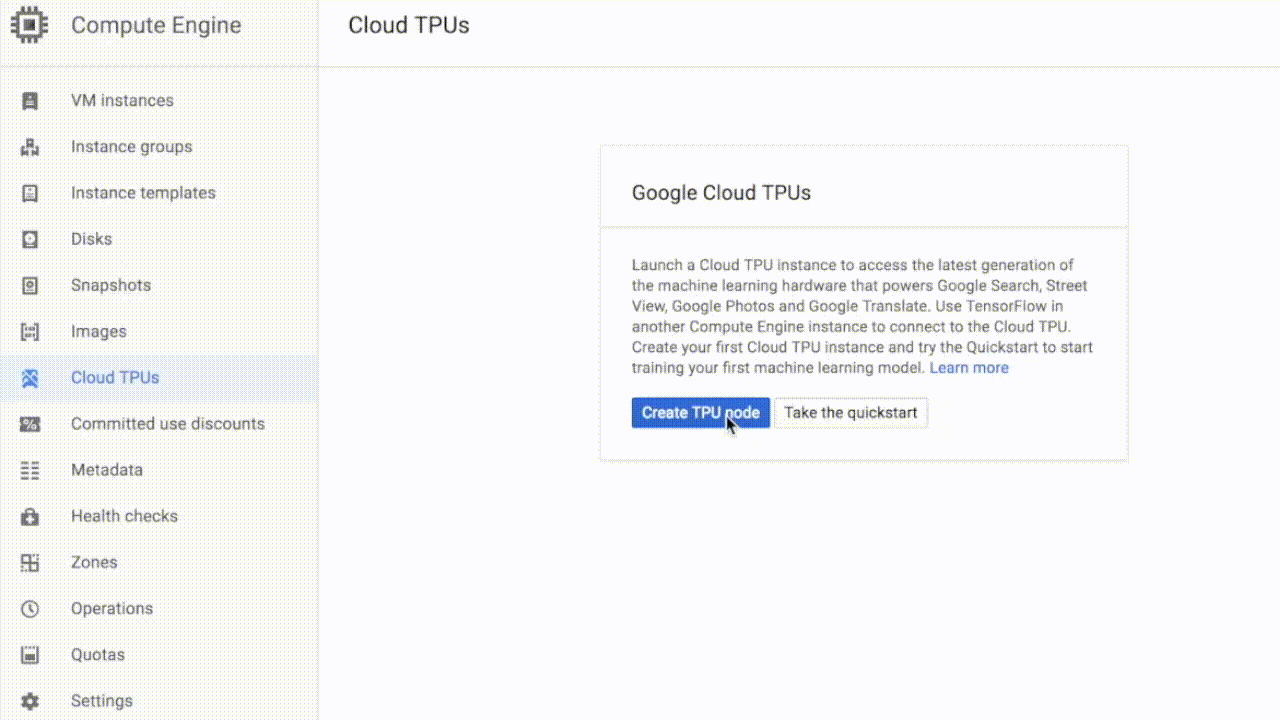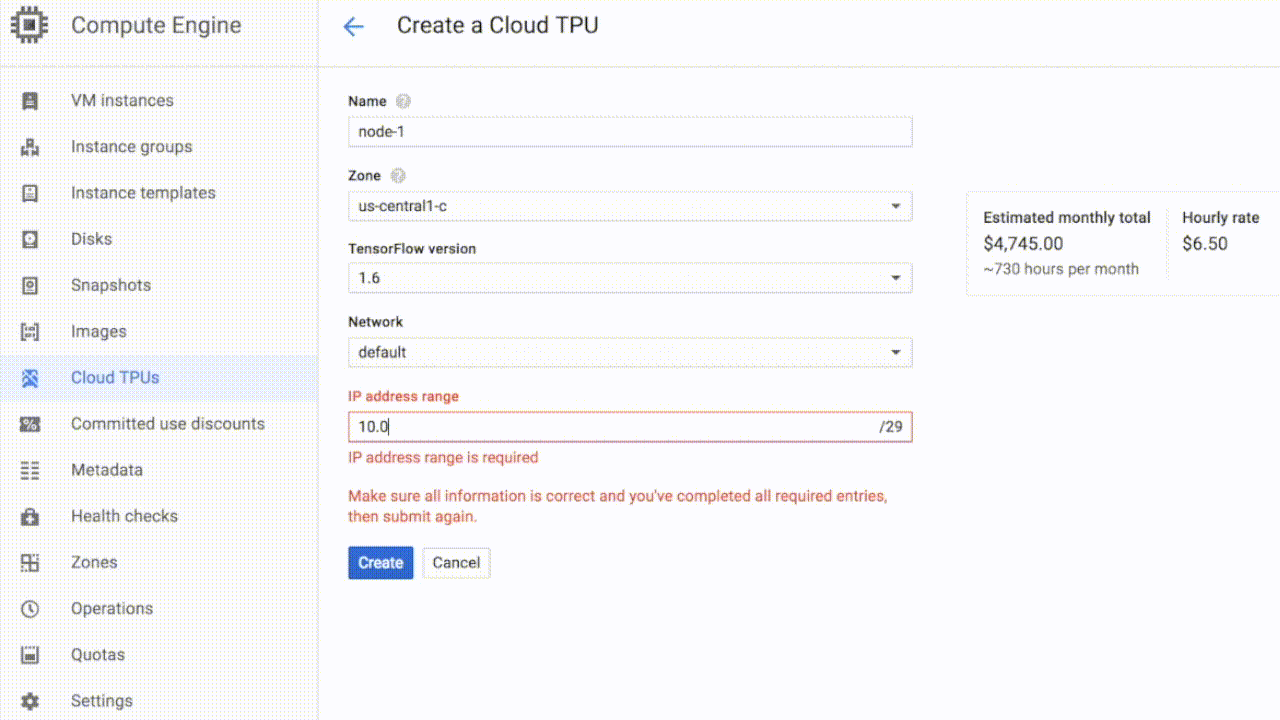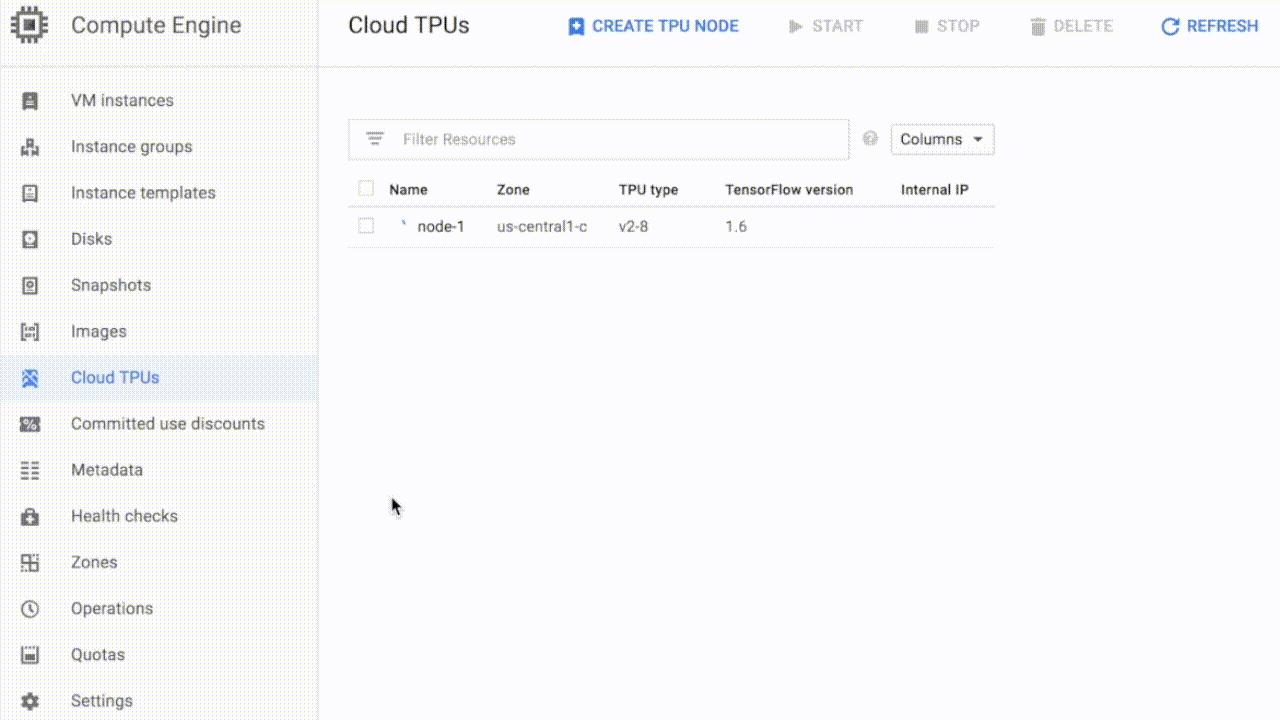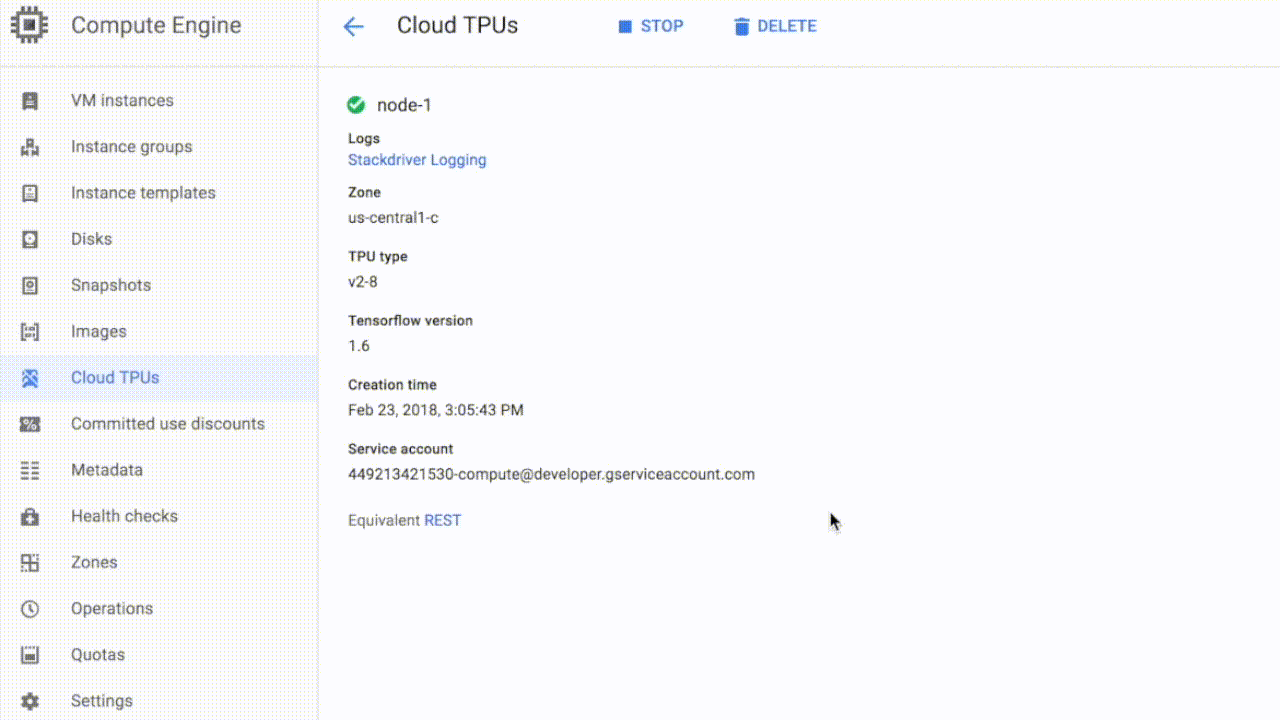
△ 创建一个新的Cloud TPU
Cloud TPU仅支持TensorFlow 1.6版本。除此之外,你的VM实例上不需要任何驱动程序,因为与TPU进行通信所需的所有代码都由TensorFlow本身提供。在TPU上执行的代码经过优化,并由XLA进行实时编译,XLA也是TensorFlow的一部分。
为了有效使用TPU,你的代码应该建立在高级Estimator抽象上。然后可以用TPUEstimator[1]来执行很多必要的任务,这也能更有效的利用TPU。例如,这可以为TPU设置数据队列并在不同的核心之间并行计算。
[1] https://www.tensorflow.org/api_docs/python/tf/contrib/tpu/TPUEstimator
一旦完成所有设置,就能像普通情况一样运行TensorFlow代码。TPU将在启动过程中被发现,然后计算图被编译并传输到TPU。有意思的是,TPU还可以直接从云存储中读取和写入,存储检查点或者事件摘要。当然你需要提供相应的写入和访问权限。
评测设置
这个评测最想得到的回答,当然是TPU速度有多快。
TensorFlow在GitHub上提供了一个针对TPU的模型仓库。地址在:https://github.com/tensorflow/tpu。
接下来的评测,基于ResNet和Inception。
我们还想知道,没有针对TPU进行优化的模型运行起来什么样,所以还有一个进行文本分类的LSTM模型运行在TPU上。而且这还是一个小模型,我们也想看看效果,因为通常谷歌建议在TPU上运行较大的模型。
所有的模型,都有会分别在单个Cloud TPU和单个英伟达P100、V100 GPU上进行训练,然后进行速度比较。当然,彻底的比较还应包括模型的最终质量、收敛性等。但是这次的评测,只关注了训练速度,更多情况稍后再详细研究。
在TPU和P100上的实验,运行于谷歌云平台的n1-standard-16实例(16 vCPUs Intel Haswell, 60 GB memory)。在V100上的实验,使用了亚马逊云的p3.2xlarge实例(8 vCPUs, 60 GB memory)。
所有的系统都运行于Ubuntu 16.04。对于TPU,我们从PyPi仓库安装了TensorFlow 1.6.0-rc1。GPU实验中运行了nvidia-docker[2],使用了TensorFlow 1.5(tensorflow:1.5.0-gpu-py3)其中包括CUDA 9.0和cuDNN 7.0。
[2] https://github.com/NVIDIA/nvidia-docker
实验结果:TPU优化的模型
首先来看看第一组结果,针对TPU优化过的模型表现如何。下面,可以看到性能对比,衡量标准是每秒能处理的图片数。
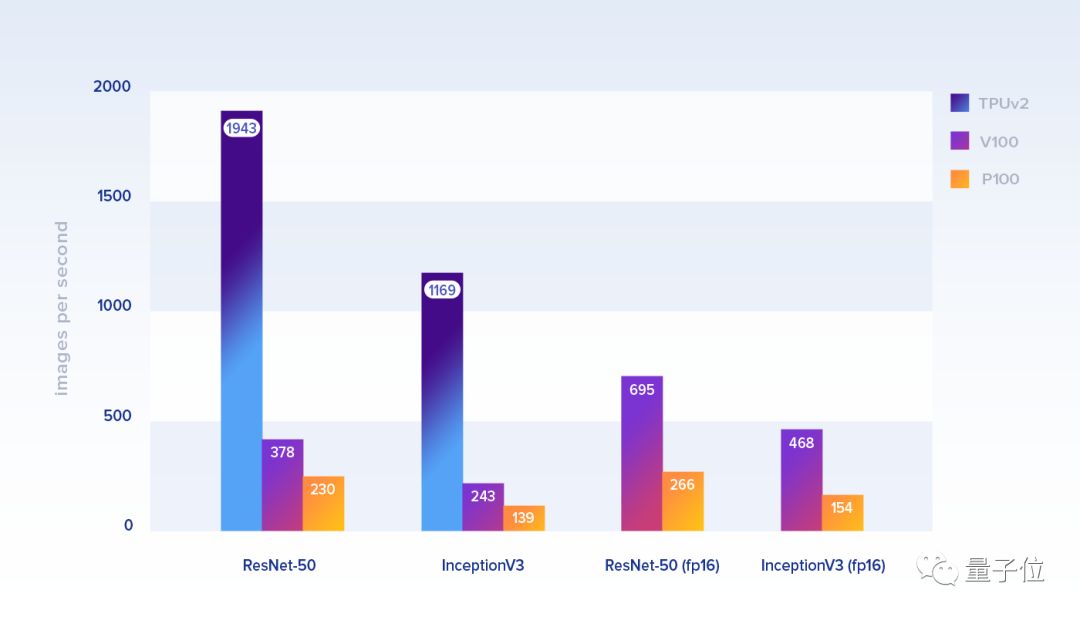
TPU的batch大小是1024,GPU是128。对于GPU,我们使用了TensorFlow基准仓库的实现,地址:https://github.com/tensorflow/benchmarks。训练数据是谷歌提供的伪ImageNet数据集,存储在云端(为TPU)和本地磁盘(为GPU)。
在ResNet-50上,单个Cloud TPU比单个P100快8.4倍,比V100快5.1倍。对于InceptionV3,结果差不多,分别快8.4倍和4.8倍。另外,如果把精度降低(fp16),V100的提速更加明显。
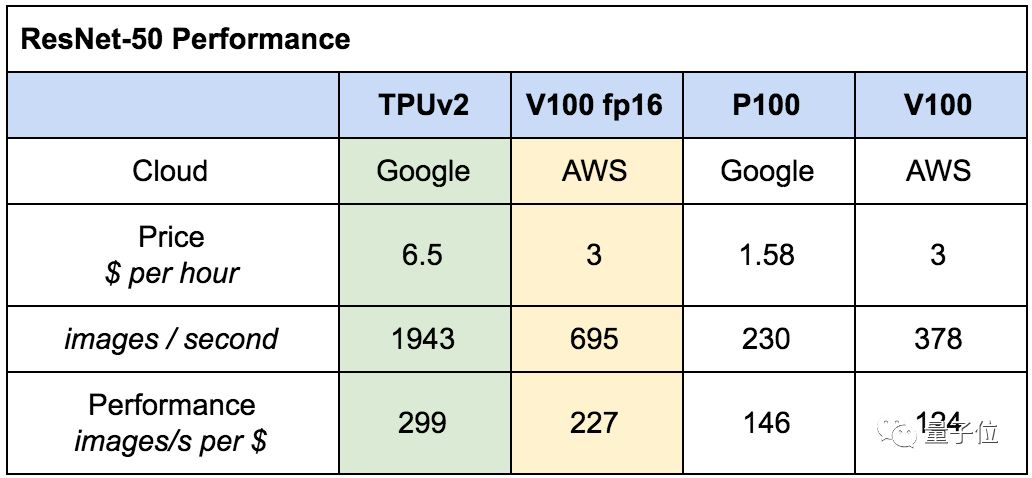
除了速度之外,成本也是重要考虑因素。下面这个表格显示,如果都在云端计算,TPU的性价比还是最高的。
实验结果:自定义的LSTM模型
我们自定义的模型时双向LSTM,使用1024隐藏单元进行文本分类。LSTM是当今NLP的一个基本构建模块,而上述官方模型都是基于计算机视觉。
源代码已经使用了Estimator框架,所以将其用于TPUEstimator非常简单。但是需要注意的是:在TPU上我们无法让模型收敛,而GPU上相同模型(batch大小等)工作正常。这应该是一个bug,或者是代码问题或是是TensorFlow的问题。
实验结果表明,在自定义的LSTM模型上,TPU还是更快。TPU(21402 examples/s)比P100(1658 examples/s)快16.9倍,比V100(2778 examples/s)快7.7倍。
由于这个模型相对较小,而且没有任何优化调整,所以结果喜人啊。当然bug还没修复,所以上述结果只是初步结果,仅供参考。
结论
上述参与测试的结果表明,谷歌Cloud TPU与英伟达最新一代GPU相比,性能更好而且经济实惠。虽然谷歌为TPU进行了更大规模模型的优化,但小型模型仍然受益于此。总的来说,尽管只是beta测试阶段,但Cloud TPU表现已经很好了。
RiseML最后给出结论:
一旦TPU能够容纳更多的用户使用,就可以成为英伟达GPU真正的替代者。

如何申请使用
最后说说,怎么才能用上数量有限的Cloud TPU。
要使用beta版的Cloud TPU,需要填个表,描述一下你要用TPU干什么,向谷歌申请配额:https://services.google.com/fb/forms/cloud-tpu-beta-request/
谷歌说,会尽快让你用上Cloud TPU。
此前的博客文章中,谷歌提到了两家客户使用Cloud TPU的感受。
一家是投资公司Two Sigma。他们的深度学习研究现在主要在云上进行,该公司CTO Alfred Spector说:“将TensorFlow工作负载转移到TPU上,大大降低了编程新模型的复杂性,缩短了训练时间。”
另一家是共享出行公司Lyft。深度学习正在成为这家公司无人车研究的重要组成部分。



