【CNN结构设计】无痛的涨点技巧:ACNet
❝论文链接:https://arxiv.org/pdf/1908.03930.pdf
本文转载自:GiantPandaCV
❞
1. 前言
不知道你是否发现了,CNN的结构创新在这两年已经变得相对很少了,同时要做出有影响力并且Solid的工作也变得越来越难,最近CNN结构方面的创新主要包含两个方面:
-
网络结构搜索,以Google Brain的EfficientNet为代表作。 -
获取更好的特征表达,主要是将特征复用,特征细化做得更加极致,以HRNet,Res2Net等为代表作。
本文要介绍的是ICCV 2019的一个新CNN架构ACNet(全称为Asymmetric Convolution Net),但是可能很多同学没有实测或者对里面要表达的核心思想并没有捕捉,因此这篇文章的目的是讲清楚ACNet的原理并总结它的核心思想,另外借助作者开源的Pytorch代码端来加深理解。
2. 介绍
ACNet的切入点为获取更好的特征表达,但和其它方法最大的区别在于它没有带来额外的超参数,而且在推理阶段没有增加计算量,这是十分具有吸引力的。
在正式介绍ACNet之前,首先来明确一下关于卷积计算的一个等式,这个等式表达的意思就是「对于输入特征图 ,先进行K(1)和I卷积,K(2)和I卷积后再对结果进行相加,与先进行K(1)和K(2)的逐点相加后再和I进行卷积得到的结果是一致的」。这也是ACNet在推理阶段不增加任何计算量的理论基础。
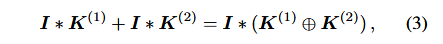
3. ACNet原理
下面的Figure1展示了ACNet的思想:
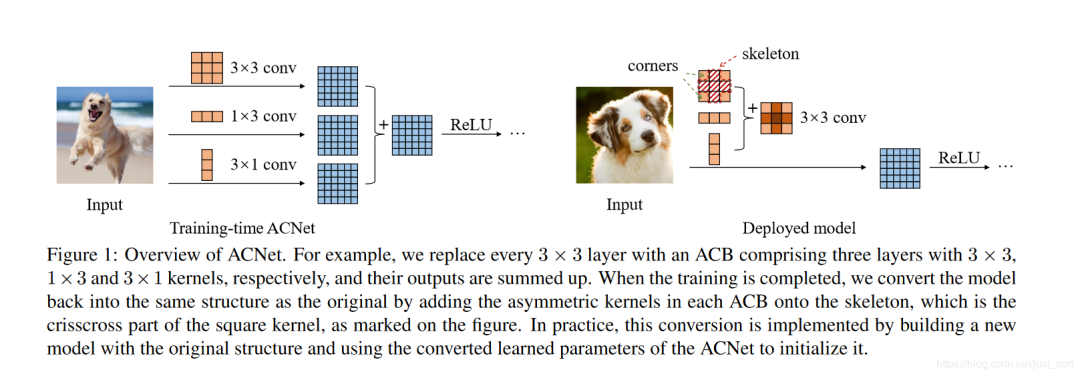
宏观上来看「ACNet分为训练和推理阶段,训练阶段重点在于强化特征提取,实现效果提升。而测试阶段重点在于卷积核融合,不增加任何计算量」。
-
「训练阶段」:因为 卷积是大多数网络的基础组件,因此ACNet的实验都是针对 卷积进行的。训练阶段就是将现有网络中的每一个 卷积换成 卷积+ 卷积+ 卷积共三个卷积层,最终将这三个卷积层的计算结果进行融合获得卷积层的输出。因为这个过程中引入的 卷积和 卷积是非对称的,所以将其命名为Asymmetric Convolution。 -
「推理阶段」:如上图右半部分所示,这部分主要是对三个卷积核进行融合。这部分在实现过程中就是使用融合后的卷积核参数来初始化现有的网络,因此在推理阶段,网络结构和原始网络是完全一样的了,只不过网络参数采用了特征提取能力更强的参数即融合后的卷积核参数,因此在推理阶段不会增加计算量。
总结一下就是ACNet在训练阶段强化了原始网络的特征提取能力,在推理阶段融合卷积核达到不增加计算量的目的。虽然训练时间增加了一些时间,但却换来了在推理阶段速度无痛的精度提升,怎么看都是一笔非常划算的交易。下面的Table3展示了在一些经典网络上应用ACNet的结果,对于AlexNet精度提升了比较多,而对ResNet和DenseNet精度则提升不到一个百分点,不过考虑到这个提升是白赚的也还是非常值得肯定的。

4. 为什么ACNet能涨点?
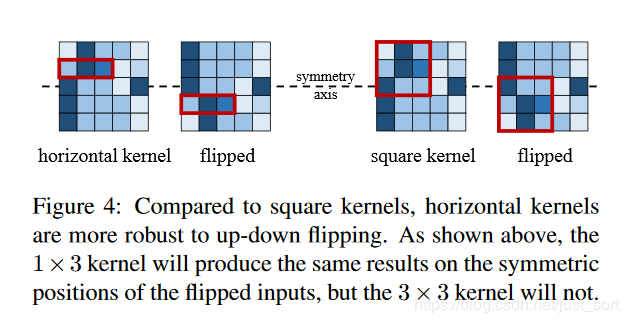
为什么ACNet这个看起来十分简单的操作能为各种网络带来涨点?论文中提到,ACNet有一个特点是「它提升了模型对图像翻转和旋转的鲁棒性」,例如训练好后的 卷积和在图像翻转后仍然能提取正确的特征(如Figure4左图所示,2个红色矩形框就是图像翻转前后的特征提取操作,在输入图像的相同位置处提取出来的特征还是一样的)。那么假设训练阶段只用 卷积核,当图像上下翻转之后,如Figure4右图所示,提取出来的特征显然是不一样的。
因此,引入 这样的水平卷积核可以提升模型对图像上下翻转的鲁棒性,竖直方向的 卷积核同理。
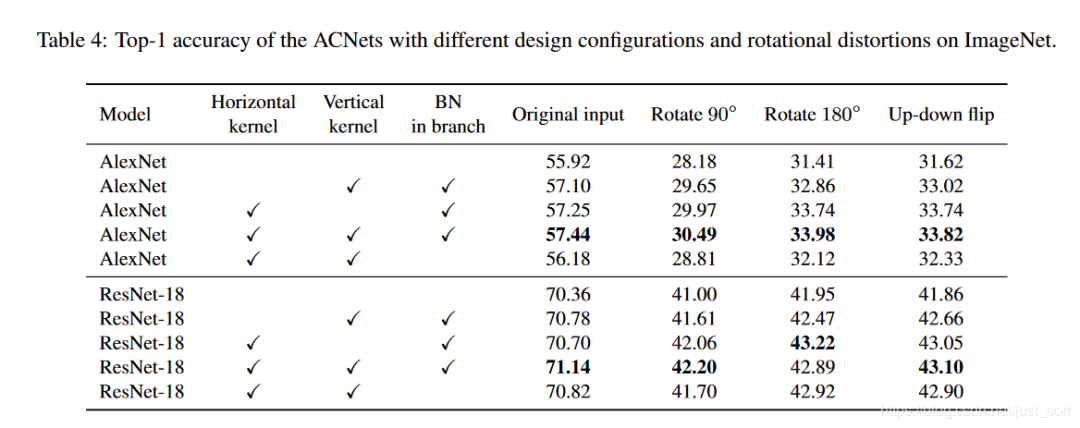
下面的Table4则继续从实验角度解释了这种鲁棒性:
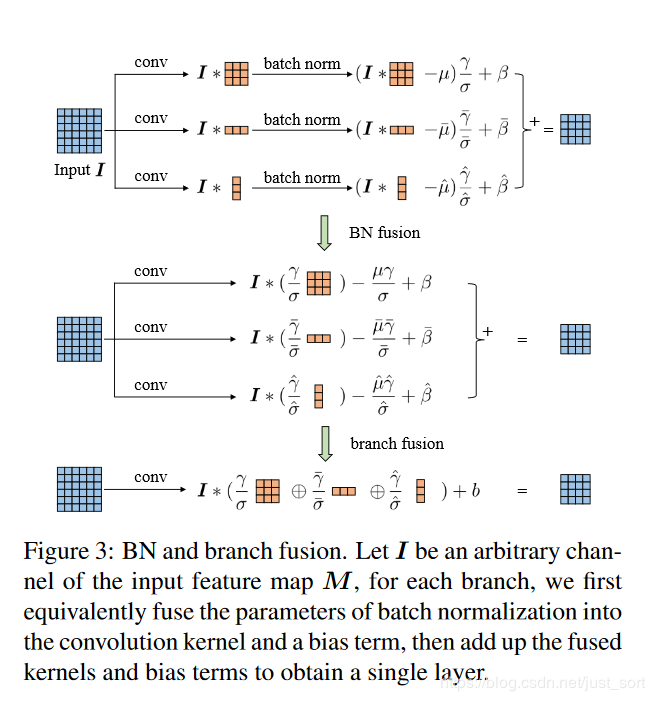
5. 推理阶段的卷积核融合
推理阶段的融合操作如Figure3所示,在论文中提到具体的融合操作是和BN层一起的,然后融合操作时发生在BN之后的。但是其实也可以把融合操作放在BN层之前,也就是三个卷积层计算完之后就开始融合。论文对这两种融合方式进行了实验,在上面的Table4中BN in branch这一列有√的话表示融合是在BN之后,可以看到这种方式使得效果确实会更好一些。
6. Pytorch代码实现
我们来看一下作者的ACNet基础结构Pytorch实现,即将原始的 卷积变成 :
# 去掉因为3x3卷积的padding多出来的行或者列
class CropLayer(nn.Module):
# E.g., (-1, 0) means this layer should crop the first and last rows of the feature map. And (0, -1) crops the first and last columns
def __init__(self, crop_set):
super(CropLayer, self).__init__()
self.rows_to_crop = - crop_set[0]
self.cols_to_crop = - crop_set[1]
assert self.rows_to_crop >= 0
assert self.cols_to_crop >= 0
def forward(self, input):
return input[:, :, self.rows_to_crop:-self.rows_to_crop, self.cols_to_crop:-self.cols_to_crop]
# 论文提出的3x3+1x3+3x1
class ACBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', deploy=False):
super(ACBlock, self).__init__()
self.deploy = deploy
if deploy:
self.fused_conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(kernel_size,kernel_size), stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)
else:
self.square_conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=(kernel_size, kernel_size), stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=False,
padding_mode=padding_mode)
self.square_bn = nn.BatchNorm2d(num_features=out_channels)
center_offset_from_origin_border = padding - kernel_size // 2
ver_pad_or_crop = (center_offset_from_origin_border + 1, center_offset_from_origin_border)
hor_pad_or_crop = (center_offset_from_origin_border, center_offset_from_origin_border + 1)
if center_offset_from_origin_border >= 0:
self.ver_conv_crop_layer = nn.Identity()
ver_conv_padding = ver_pad_or_crop
self.hor_conv_crop_layer = nn.Identity()
hor_conv_padding = hor_pad_or_crop
else:
self.ver_conv_crop_layer = CropLayer(crop_set=ver_pad_or_crop)
ver_conv_padding = (0, 0)
self.hor_conv_crop_layer = CropLayer(crop_set=hor_pad_or_crop)
hor_conv_padding = (0, 0)
self.ver_conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(3, 1),
stride=stride,
padding=ver_conv_padding, dilation=dilation, groups=groups, bias=False,
padding_mode=padding_mode)
self.hor_conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(1, 3),
stride=stride,
padding=hor_conv_padding, dilation=dilation, groups=groups, bias=False,
padding_mode=padding_mode)
self.ver_bn = nn.BatchNorm2d(num_features=out_channels)
self.hor_bn = nn.BatchNorm2d(num_features=out_channels)
# forward函数
def forward(self, input):
if self.deploy:
return self.fused_conv(input)
else:
square_outputs = self.square_conv(input)
square_outputs = self.square_bn(square_outputs)
# print(square_outputs.size())
# return square_outputs
vertical_outputs = self.ver_conv_crop_layer(input)
vertical_outputs = self.ver_conv(vertical_outputs)
vertical_outputs = self.ver_bn(vertical_outputs)
# print(vertical_outputs.size())
horizontal_outputs = self.hor_conv_crop_layer(input)
horizontal_outputs = self.hor_conv(horizontal_outputs)
horizontal_outputs = self.hor_bn(horizontal_outputs)
# print(horizontal_outputs.size())
return square_outputs + vertical_outputs + horizontal_outputs
然后在推理阶段进行卷积核融合的代码实现地址为:https://github.com/DingXiaoH/ACNet/blob/master/acnet/acnet_fusion.py,对照Figure3就比较好理解了,介于篇幅这里就不贴这段代码了。
7. 思考
从实验结果中可以看到,在推理阶段即使融合操作放在BN层之前,相比原始网络仍有一定提升(AlexNet的56.18% vs 55.92%,ResNet-18的70.82% vs 70.36%),作者没有讲解这部分的原理,我比较同意魏凯峰大佬的观点,如下:
❝这部分的原因个人理解是来自梯度差异化,原来只有一个 卷积层,梯度可以看出一份,而添加了 和 卷积层后,部分位置的梯度变为2份和3份,也是更加细化了。而且理论上可以融合无数个卷积层不断逼近现有网络的效果极限,融合方式不限于相加(训练和推理阶段一致即可),融合的卷积层也不限于 或 尺寸。
❞
个人将ACNet的结构用在一个业务数据中并取得了2%的精度提升,这一方法确实是非常有用并且也是推理无痛的,建议大家可以在自己的数据上进行尝试。
8. 总结
本文简要讲述了ACNet这个无痛的调参方法,这种方法创新点是非常棒的,我们不一定需要重型BackBone去提取特征,也不一定需要复杂的结构复用特征,像ACNet这样的优雅并且有效的作品确实让人眼前一亮。
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1250+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
麻烦给我一个在看!


