[编程经验] 链家23个全国主要城市的现房数据分析

今天起来看到一个公众号发的推文,分析了链家上面成都的房价数据,自己好奇也玩了一把,收集了全国23个主要城市的在售房产数据,并作了对比,拿出来跟大家分享。涉及的城市有广州,大连,杭州,济南,石家庄,武汉,长沙,深圳,郑州,天津,佛山,北京,上海,惠州,沈阳,太原,厦门,重庆,珠海,合肥,成都,中山,南京,西安。爬虫写的比较笨,大神勿喷。
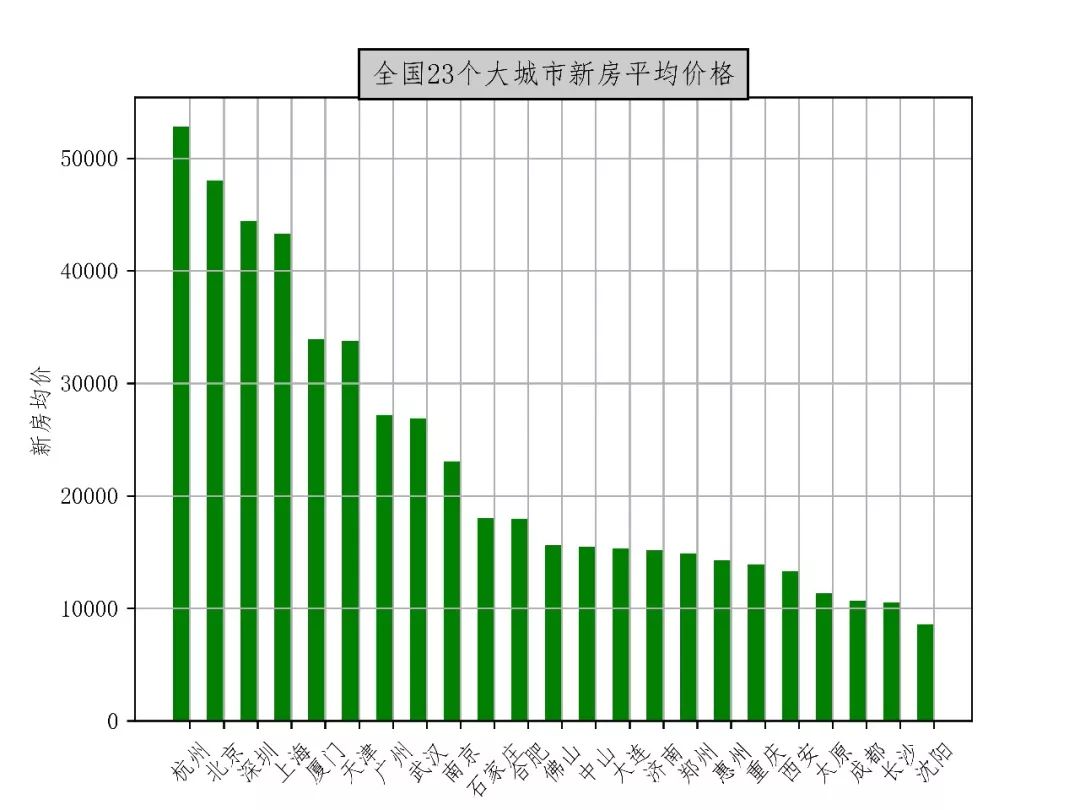
先放一张条形图,感受一下房价。
1. 数据爬取
打开链家的新房主页,任意选择一个城市,然后按楼盘来查找,就是下面这个。
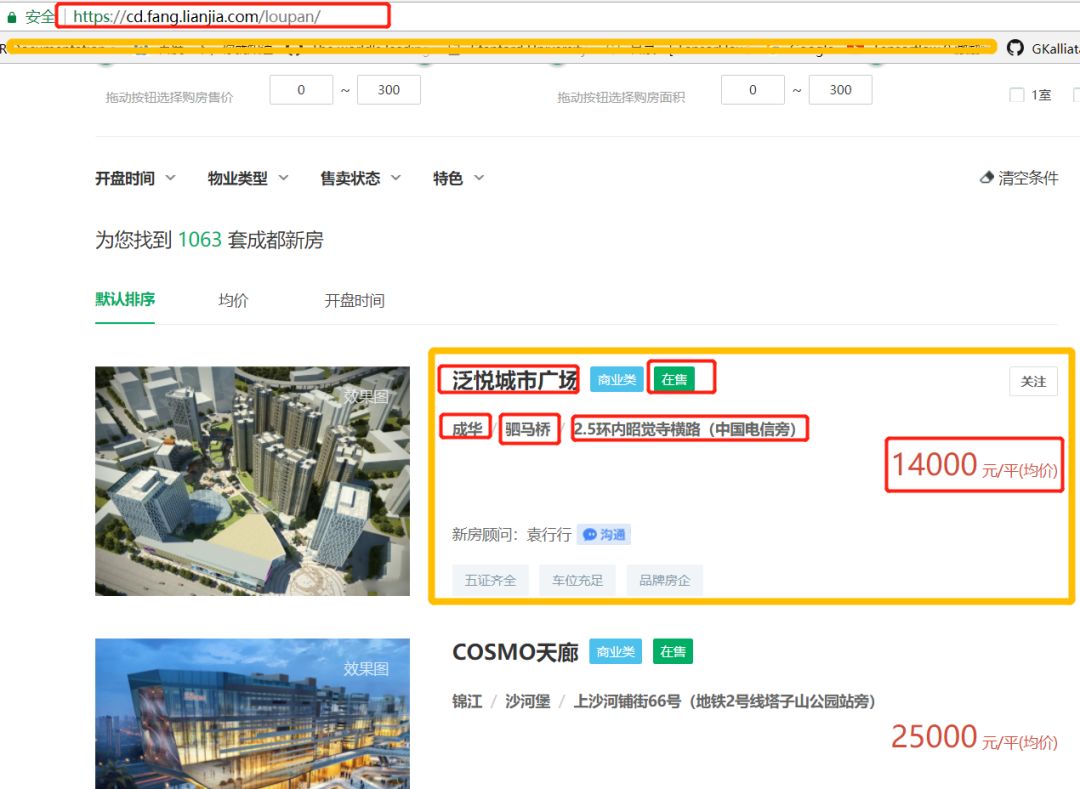
然后我们主要关心的数据有楼盘的名字,售卖状态,地点以及价格等。然后查看网页源码之后发现,我们想要的数据在resblock-list-wrapper这个class里面。所以首先取到这个class下面的全部内容,然后再挨个提取我们想要的数据。
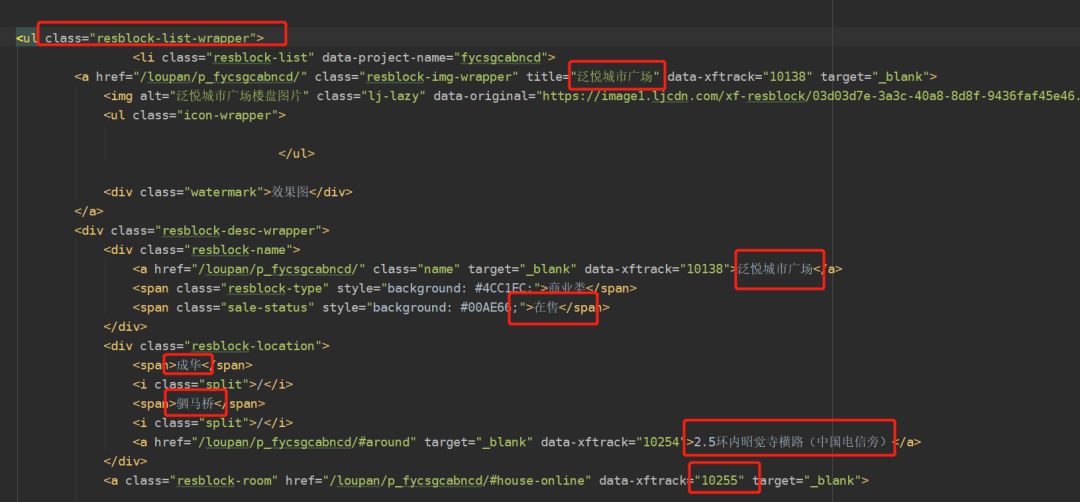
代码如下
import urllib.request
from bs4 import BeautifulSoup
from tqdm import trange
import pandas as pd
import requests
import os
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
citys = {'bj': "北京", 'xa': "西安", 'cd': "成都",
'cq': "重庆", 'sh': "上海", 'sz': "深圳",
'gz': "广州", 'hz': "杭州", 'dl': "大连",
'nj': "南京", 'sjz': "石家庄", 'sy': "沈阳",
'tj': "天津", 'wh': "武汉", 'xm': "厦门",
'cs': '长沙', 'zz': '郑州', 'ty': '太原',
'hf': '合肥', 'fs': "佛山", 'hui': '惠州',
'jn': '济南', 'zs': "中山"}
print(len(citys))
mpl.rcParams['font.sans-serif'] = ['FangSong']
mpl.rcParams['axes.unicode_minus'] = False
for city in citys.keys():
save_data = []
for i in trange(120):
url = "https://{}.fang.lianjia.com/" \
"loupan/pg{}/".format(city, i)
print(requests.get(url).status_code)
if requests.get(url).status_code != 200:
continue
req = urllib.request.Request(url)
req.add_header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64) "
"AppleWebKit/537.36 (KHTML, like Gecko)"
" Chrome/45.0.2454.101 Safari/537.36")
req.add_header("Accept", "*/*")
req.add_header("Accept-Language", "zh-CN,zh;q=0.8")
data = urllib.request.urlopen(req)
html = data.read().decode('utf-8')
soup = BeautifulSoup(html, "lxml")
resp = soup.findAll('ul',
attrs={
'class':
'resblock-list-wrapper'})
resp = resp[0]
resp = resp.findAll('li', attrs={'class':
'resblock-list'})
for i in range(len(resp)):
housenames = resp[i].findAll(
'div', attrs={'class': 'resblock-name'})
housename = housenames[0].findAll(
'a', attrs={'target': '_blank'})[0].text
herf = housenames.get('herf')
print(herf)
exit(1)
try:
housenames = resp[i].findAll(
'div', attrs={'class': 'resblock-name'})
housename = housenames[0].findAll(
'a', attrs={'target': '_blank'})[0].text
herf = housenames.get('herf')
print(herf)
resblocktype = housenames[0].findAll(
'span', attrs={'class':
'resblock-type'})[0].text
salestatus = housenames[0].findAll(
'span', attrs={'class':
'sale-status'})[0].text
except:
continue
try:
resblocklocation = resp[i].findAll(
'div', attrs={'class':
'resblock-location'})
addressinfolist = \
resblocklocation[0].text.
replace("\n", "")
quyu, address, addressinfo = \
addressinfolist.split("/")[0], \
addressinfolist.split("/")[1], \
addressinfolist.split("/")[2]
except:
continue
try:
resblockroom = resp[i].findAll(
'a', attrs={'class': 'resblock-room',
'target': '_blank'})[
0].text.replace("\n", "")
except:
continue
try:
resblockarea = resp[i].findAll(
'div', attrs={'class': 'resblock-area'})
[0].\
text.replace("\n", "").
replace("建面 ", "")
except:
continue
try:
resblockprice = resp[i].findAll(
'div', attrs={'class': 'main-price'})[0]
priceinfo = resblockprice.findAll(
'span', attrs={'class': 'number'})[0].
text
except:
continue
try:
secondprice = resp[i].findAll(
'div', attrs={'class': 'second'})[0].\
text.replace("总价", "").
replace("万/套起", "")
except:
continue
rows = {'housename': housename,
'resblocktype': resblocktype,
'salestatus': salestatus,
'address': address,
'addressinfo': addressinfo,
'resblockroom': resblockroom,
'resblockarea': resblockarea,
'priceinfo': priceinfo,
'secondprice': secondprice}
save_data.append(rows)
df = pd.DataFrame(save_data)
df.to_csv("./datasets/{}.csv".format(city),
line_terminator="\n", index=None)
2. 数据分析
然后分析每平米的价格数据,做个条形图
def analyse():
path = './datasets'
mean_price = []
for file in os.listdir(path):
filename = os.path.join(path, file)
data = pd.read_csv(filename,
usecols=['priceinfo']).values
prices = []
for x in data:
if str(x[0]).isdigit():
prices.append(int(x[0]))
pricesmean = np.mean(prices)
rows = {'city': citys[file.split(".")[0]],
'meanprice': pricesmean}
mean_price.append(rows)
df = pd.DataFrame(mean_price)
df = df.sort_values(by='meanprice', ascending=False)
labels = df['city']
price = df['meanprice']
width = 0.5
ind = np.linspace(1, 23, 23)
fig = plt.figure(dpi=600)
ax = fig.add_subplot(111)
ax.bar(ind - width / 2, price, width, color='green')
ax.set_xticks(ind)
ax.set_xticklabels(labels)
ax.set_ylabel('新房均价')
ax.set_title('全国23个大城市新房平均价格',
bbox={'facecolor': '0.8', 'pad': 5})
plt.grid(True)
plt.xticks(rotation=45)
plt.savefig("bar.jpg")
plt.close()
然后就是这个图了
从这个图可以看到,房价最高的不是北京和上海,而是杭州,并且成都的房价要低于西安,这个是我之前没有想到的。
花了大半天的时间,做了这些,然后链家里面有价值的数据我觉得还有房源的评论数据,这个数据其实也不难爬,可以给大家看看。我们点房源的评论,网页就跳转到这个页面,url后面跟的这个是什么呢?
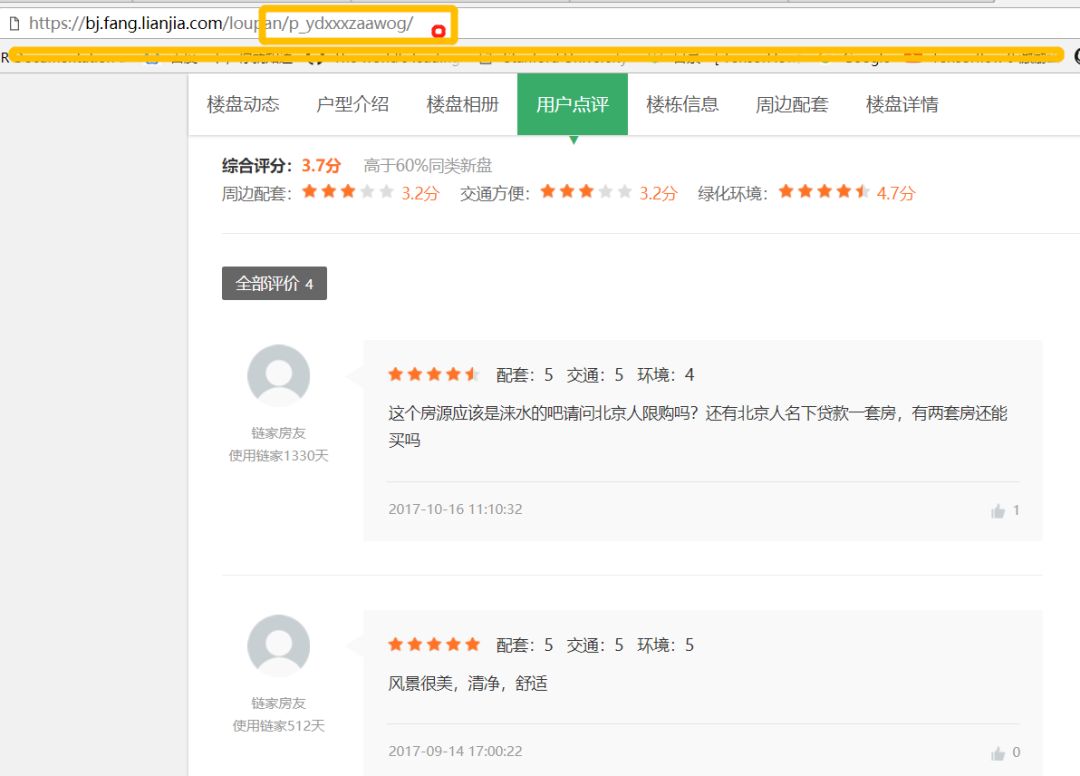
回到上一页,点楼盘名称,然后查看源代码,然后看到这个herf后面跟着的就是评论的url后面的。
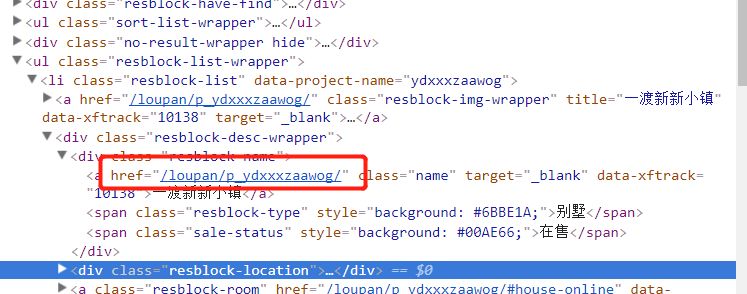
所以想要爬取评论数据,只要提取出这个herf,然后跟在前面的url后面就可以了。然后提取具体的评论语料就简单了哈。
有需要的童鞋可以下载本文代码:
链接:https://pan.baidu.com/s/1dOTXTk 密码:i5uh
登录查看更多
相关内容

专知会员服务
19+阅读 · 2019年10月22日
Arxiv
10+阅读 · 2018年1月29日



相关VIP内容
专知会员服务
19+阅读 · 2019年10月22日
相关资讯
相关论文
Arxiv
10+阅读 · 2018年1月29日