麻省理工学院(MIT)提出的自动微分框架 Enzyme 在 NeurIPS 2020 大会上引起过不少人的兴趣,现在人们已经可以尝试使用这套工具了。
当前,PyTorch、TensorFlow 等机器学习框架已经成为了人们开发的重要工具。计算反向传播、贝叶斯推理、不确定性量化和概率编程等算法的梯度时,我们需要把所有的代码以微分型写入框架内。这对于将机器学习引入新领域带来了问题:在物理模拟、游戏引擎、气候模型中,原领域组件不是由机器学习框架的特定领域语言(DSL)编写的。因此在将机器学习引入科学计算时,重写需求成为了一个挑战。
为了解决这一问题,现在的发展趋势包含构建新的 DSL,让重写过程变得简单,或者在编程时直接进行构建。这些方法可以让我们获得有效的梯度,但是仍然需要使用 DSL 或可微分的编程语言进行重写。
开发者们自然会希望使用机器学习框架以外的代码重用已有工具,或在一种语言里写好损失函数,然后为其用例提供更简单的抽象。尽管目前已经出现了一些针对不同语言的反向自动微分框架(AD),但我们很难在 ML 框架外的代码上自动使用它们,因为其仍需要重写,且对于跨语言 AD 和库的支持有限。
为了方便开发者,来自 MIT 的研究者开源了 Enzyme,一种用于 LLVM 编译器框架的高性能自动微分(AD)编译器插件。该插件能够合成以 LLVM 中间表示(IR)表示的静态可分析程序的梯度。Enzyme 能够合成任何以面向 LLVM IR 编译器为语言编写的程序的梯度,包括 C、C ++、Fortran、Julia、Rust、Swift、MLIR 等,从而提供这些语言的本机 AD 功能。
据作者介绍,与传统的源到源和 operator-overloading 工具不同,Enzyme 在优化的 IR 上执行 AD。
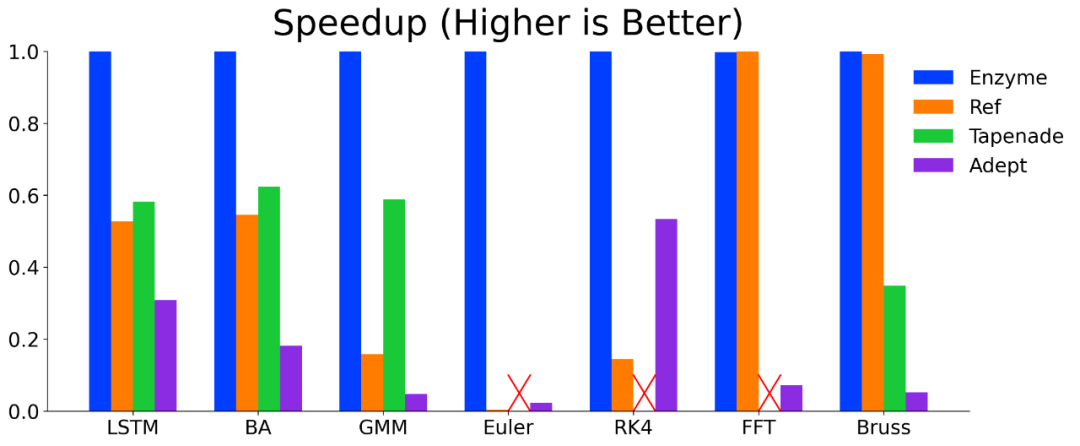
在包括微软 ADBench 在内的以机器学习为重点的基准套件上,经过优化的 IR 上的 AD 的几何平均速度比未经过优化的 IR 上 AD 的几何平均速度提高了 4.5 倍,这使得 Enzyme 达到了最高的性能。
此外,Enzyme 方便使用,在 PyTorch 和 TensorFlow 上都有程序包,可让开发者便捷访问具有最新性能的外来代码梯度,从而使外来代码可直接合并到现有的机器学习工作流程中。
Enzyme,一种用于 LLVM 的编译器插件,可以合成可静态微分的 LLVM IR 的快速梯度。包括 C、C ++、Fortran、Rust、Swift 等编译器前端生成的中间表示(IR)。
PyTorch-Enzyme/TensorFlow-Enzyme,一个外部功能接口,允许机器学习研究者使用 PyTorch 和 TensorFlow 使用以 LLVM 编译语言编写的外部代码。
Enzyme.jl,一个 Julia 包,通过动态高级语言编写的代码,仅使用低层信息获得梯度。
通过链接时优化(LTO)支持了多来源 AD 和静态库支持。
研究表明优化后运行 AD,在标准机器学习基准测试上可获得显著性能提升,并达到 SOTA 水平。
![]()
上图为 relu(pow(x,3)) 的梯度合成示例。左侧为 LLVM IR 上的原始计算。左侧注释中展示了将添加到前向传递中的活动变量的影子分配。右侧则是 Enzyme 将生成的反向传递。完整的合成梯度函数将结合使用这些函数(添加影子分配),将 if.end 中的返回替换为 reverse_if.end 的分支。
Enzyme 项目是一个用于可静态分析 LLVM IR 的反向模式自动微分(AD)工具。它允许开发者可以自动创建基于源代码的梯度,而无需更多额外工作。
double foo(double);
double grad_foo(double x) { return __enzyme_autodiff(foo, x);}
通过优化微分后的代码,Enzyme 可以比现有的优化工具提供更快的微分速度:
![]()
可选的预处理阶段,该阶段执行对 AD 有用的较小转换。
一种新的过程间类型分析,可推断出内存位置的基础类型。
活动分析,确定哪些指令或值会影响导数计算(在现有 AD 系统中很常见)。
优化遍历可创建任何必需的派生函数,用生成的函数替换对__enzyme_autodiff 的调用。
更多详细介绍,可查看 MIT 研究者们提交的 NeurIPS 2020 论文:
![]()
论文地址:
https://arxiv.org/pdf/2010.01709.pdf
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com