TensorFlow | 自己动手写深度学习模型之全连接神经网络

本文作者王乐,首发于知乎专栏【每天都要机器学习哦】,AI 研习社获得作者授权转载
前半个多月总共写了三篇深度学习相关的理论介绍文章,另外两个月前,我们使用逻辑回归算法对sklearn里面的moons数据集进行了分类实验,最终准确率和召回率都达到了97.9%,详情参看这篇文章:一文打尽:线性回归和逻辑斯蒂线性回归(https://zhuanlan.zhihu.com/p/31075733),今天我们尝试使用神经网络来进行分类。全连接神经网络的搭建本身没什么难度,几句代码就够了,但是本文的真正目的是:
让大家了解Tensorflow 的基本使用方法;
使用 tensorboard 可视化你的神经网络结构和变量的更新情况;
断点保存模型,可以在训练意外中断之后再次运行时接着中断之前的状态继续训练;
展示全连接神经网络是不是真的可以拟合任意函数,拟合效果怎样。
了解以上前三点操作之后,你可以移植到任何网络之中,这样有助于你更好的训练模型,调参。
加载数据
def load_data(noise=0.1):
from sklearn.datasets import make_moons
m = 2000
X_moons, y_moons = make_moons(m, noise=noise, random_state=42)
return X_moons, y_moons
我们在moons 数据集中取2000 个点,其中参数 noise 表示在数据集中随机增加噪声;X_moons 是一个2维的数组,shape 为(2000,2);y_moons 为1维数组,shape为(2000,)。具体数据可以参考线性回归那篇文章。
随机 batch
def random_batch(X_train, y_train, batch_size):
rnd_indices = np.random.randint(0, len(X_train), batch_size)
X_batch = X_train[rnd_indices]
y_batch = y_train[rnd_indices]
return X_batch, y_batch
训练模型时,我们通常会将数据一批一批的丢给模型取训练,而不是每次都把所有数据丢进取训练,这么做的理由和好处在文章 深度学习中的优化问题以及常用优化算法 中已经做过说明。因此在每一步训练中我们需要在训练集中随机取batch_size 个训练数据出来,上述函数实现的就是这个功能。当然这个代码这样写的话,有些训练样本可能一次都不会被取到,有的样本会经常取到,但这是无关紧要的。
划分训练集和测试集
test_ratio = 0.2
test_size = int(len(data) * test_ratio)
X_train = data[:-test_size]
X_test = data[-test_size:]
y_train = label[:-test_size]
y_test = label[-test_size:]
上述代码不需要解释。
建立全连接神经网络层
# regularizer = tf.contrib.layers.l2_regularizer(lambd)def fc_layers(input_tensor,regularizer):
HINDENN1 = 6
HINDENN2 = 4
with tf.name_scope("full-connect-layer"):
fc1 = tf.layers.dense(input_tensor, HINDENN1, activation=tf.nn.elu,\
kernel_regularizer=regularizer, name="fc1")
fc2 = tf.layers.dense(fc1, HINDENN2, activation=tf.nn.elu,\
kernel_regularizer=regularizer, name="fc2")
return fc2
在这个实验中,我直搭建两个隐藏层的全连接网络,第一个隐藏层 6 个神经元,第二层隐藏出 4个神经元。激活函数使用ELU,因为我之前介绍激活函数时说过,我们应该优先选择ELU激活函数。在全连接中使用了L2正则化,lambd 表示正则系数,这里数据量比较少,我取的正则系数也比较小,为0.01。
搭积木一样搭建整个模型的结构
n_inputs = X_train.shape[1]
n_outputs = len(set(y_train))
with tf.name_scope("input"):
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y")
regularizer = tf.contrib.layers.l2_regularizer(lambd)
fc2 = fc_layers(X,regularizer)
with tf.name_scope("output"):
logits = tf.layers.dense(fc2, n_outputs, kernel_regularizer=regularizer,name="output")
with tf.name_scope('loss'):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels = y, logits= logits)
loss = tf.reduce_mean(xentropy, name = 'loss')
loss_summary = tf.summary.scalar('loss', loss)
global_step = tf.Variable(0, trainable = False)
with tf.name_scope('train'):
optimizer = tf.train.AdamOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
with tf.name_scope('eval'):
predictions = tf.argmax(logits, 1)
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
acc_summary = tf.summary.scalar('acc', accuracy)
summary_op = tf.summary.merge([loss_summary, acc_summary])
这里建立了输入层"input",输出层"output",输出层也是使用全连接网络,它将第二个隐藏层和输出层(2个输出神经元)连接起来;使用交叉熵计算损失,建立损失节点'loss',使用语句tf.summary.scalar('loss', loss) 将每一步的损失值写入到文件中;在‘train’节点中,使用了 Adam 优化算法,之前我在在介绍优化算法时叶说过,应该优先考虑使用 Adam 优化算法;最后是 'eval' 节点,这里有预测输出结果 predictions,预测结果中正确的个数 correct ,根据预测正确与否计算准确率 accuracy ,语句 tf.summary.scalar('acc', accuracy) 将正确率数值实时写入文件中;使用 tf.summary.merge([loss_summary, acc_summary]) 语句将上述两个需要写入文件的值 merge ,方便之后tensorflow 计算。
模型结构如下:
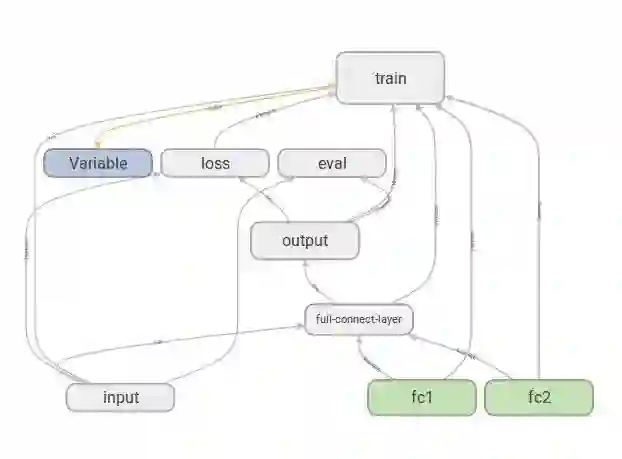
定义模型和变量的保存地址
checkpoint_path = "./chickpoints/model.ckpt"
checkpoint_epoch_path = checkpoint_path + ".epoch"
final_model_path = "./chickpoints/model"
now = datetime.utcnow().strftime("%Y%m%d%H%M%S")
logdir = './logs/'+ now
file_writer = tf.summary.FileWriter(logdir, tf.get_default_graph())
saver = tf.train.Saver()
为了防止训练的意外终止,我们需要定期保存模型,checkpoint_path 就是我们临时保存模型的路径;checkpoint_epoch_path 路径保存我们每一次的 epoch数目,如果模型在epoch = 100时中断,那么我可以设置在下次继续运行代码时让代码接着在中断的 100 epoch这里继续运行,而不需要从头开始,这样节省很多时间;final_model_path 为最终模型的保存路径;logdir 为日志文件路径,就是我们保存 tensorboard 文件的地址。
训练和验证
n_epochs = n_epochsbatch_size = batch_sizen_batches = int(np.ceil(len(data) / batch_size))with tf.Session() as sess:
init = tf.global_variables_initializer()
if os.path.isfile(checkpoint_epoch_path):
# if the checkpoint file exists, restore the model and load the epoch number
with open(checkpoint_epoch_path, "rb") as f:
start_epoch = int(f.read())
print("Training was interrupted. Continuing at epoch", start_epoch)
saver.restore(sess, checkpoint_path)
else:
start_epoch = 0
sess.run(init)
for epoch in range(start_epoch, n_epochs):
for batch_index in range(n_batches):
X_batch, y_batch = random_batch(X_train, y_train, batch_size)
sess.run(train_op, feed_dict={X: X_batch, y: y_batch})
loss_val, summary_str,test_pred, test_acc = sess.run(
[loss, summary_op,predictions, accuracy],\
feed_dict={X: X_test, y: y_test})
file_writer.add_summary(summary_str, epoch)
if epoch % 50 == 0:
print("Epoch:", epoch, "\tLoss:", loss_val,"\tAcc:",test_acc)
saver.save(sess, checkpoint_path)
with open(checkpoint_epoch_path, "wb") as f:
f.write(b"%d" % (epoch + 1))
saver.save(sess, final_model_path)
y_pred = predictions.eval(feed_dict={X: X_test, y: y_test})
print('precision_score',precision_score(y_test, y_pred))
print('recall_score',recall_score(y_test, y_pred))
sess.close()
if os.path.isfile(checkpoint_epoch_path) 语句检查是否存在上次运行程序所保存的模型,如果存在,直接加载,然后从中断的位置继续跑程序rugosa不存在,则从头开始跑。sess.run(train_op, feed_dict={X: X_batch, y: y_batch}) 语句表示训练过程,所有训练过程包括前向过程、反向传播过程/梯度下降过程、计算损失等都包括在前文的 train_op 中了;这里代码没有打印训练时的实时 损失和正确率情况,如果你跑大数据集,你可以在这一段加一些语句,实时打印模型的情况。每一个 epoch 我们将训练的模型在测试集上进行验证准确率等,loss_val, summary_str,test_pred, test_acc = sess.run(
[loss, summary_op,predictions, accuracy],\
feed_dict={X: X_test, y: y_test}),并且将要保存的日志信息写入文件 file_writer.add_summary(summary_str, epoch)。每 50 epoch 打印测试集上的损失和正确率 print("Epoch:", epoch, "\tLoss:", loss_val,"\tAcc:",test_acc) ,并且保存临时模型。在模型跑完之后,我们对测试集进行预测 y_pred = predictions.eval(feed_dict={X: X_test, y: y_test}),得到预测结果之后计算测试集的精确率和找回率,打印输出。
整个过程到这里结束。我们看看模型在测试集上的表现:
首先,我们将数据集的 noise 设置为0.1,并且不设置正则化,可以看到,效果非常好,精确率和召回率都达到100%;
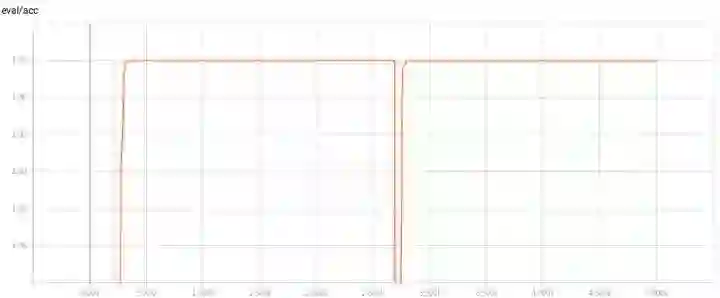
在500 epoch 之前就达到100%,并一直保持
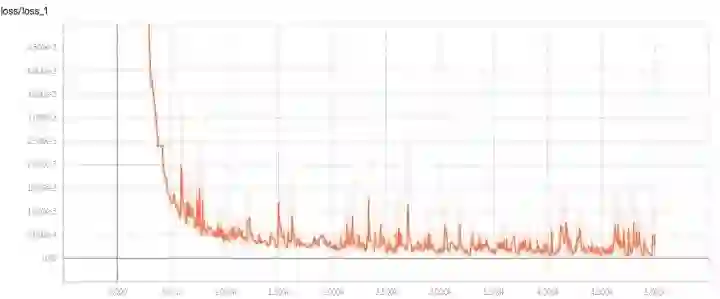
在1500epoch左右损失值降到最低,单从noise 设置为0.1看,训练次数多了,可以适当降低epoch次数
但是如果将测试集的noise 设置为0.2和0.3时,模型的表现分别如下:
noise=0.2
Training was interrupted. Continuing at epoch 4951
precision_score 0.9681818181818181
recall_score 0.9770642201834863
noise=0.3
Training was interrupted. Continuing at epoch 4951
precision_score 0.9339622641509434
recall_score 0.908256880733945
效果就变的比较差了,泛化能力较差,甚至低于逻辑回归算法。当然逻辑回归使用的噪声只有0.1,不能直接比,但是仍然可以看到当测试数据集噪声大时,模型效果不是很好的。
接下来使用正则化,测试集的noise 分别设置为0.2和0.3,模型效果如下:
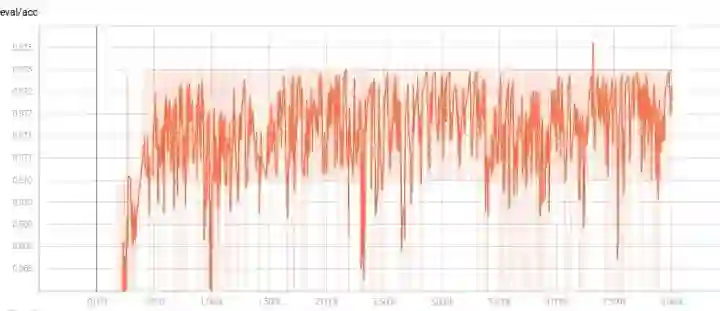
模型的准确率在0.970至0.973之间震荡
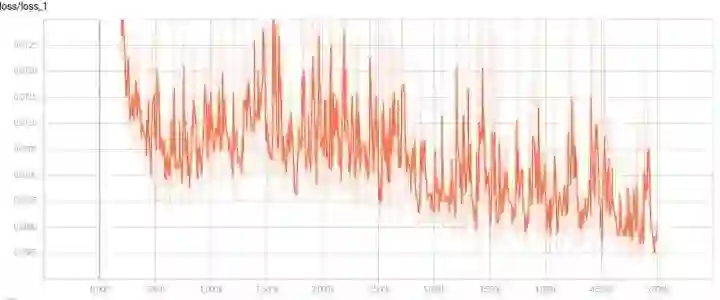
模型在测试集上的损失虽然很震荡,但是可以看出一直有下降的趋势,我这里设置的5000epoch应该不够,可以加大epoch次数
Training was interrupted. Continuing at epoch 4951
precision_score 1.0
recall_score 1.0
noise=0.3
Training was interrupted. Continuing at epoch 4951
precision_score 0.9308755760368663
recall_score 0.926605504587156
加正则化之后,泛化效果还是提升不少。最后可以看到,全连接神经网络本身是一个很好的分类器,所以你会在很多网络结构中的最后几层看到全连接神经网络,当然有些模型没有全连接,也不需要见怪不怪,因为有许多算法或者网络结构可以替代全连接分类器。
在接下来的三篇文章我回先介绍卷积神经网络,再像本文一样使用tensorflow搭建一个卷积模型做图像分类,然后接着会有一篇迁移模型的搭建文章。如果喜欢就给个赞呗……
完整代码
https://github.com/wangle1218/Depp-learning-TensorFlow-tutorials/blob/master/fc_clf.pygithub.com
参考资料
Aurélien Géron,《 Hands-On Machine Learning with Scikit-Learn and TensoFlow》
郑泽宇,顾思宇,《TensorFlow -- 实战Google 深度学习框架》

NLP 工程师入门实践班:基于深度学习的自然语言处理
三大模块,五大应用,手把手快速入门 NLP
海外博士讲师,丰富项目经验
算法 + 实践,搭配典型行业应用
随到随学,专业社群,讲师在线答疑
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
TensorFlow 实现神经网络入门篇
▼▼▼



