AAAI2020必读的10篇「知识图谱(Knowledge Graph)」相关论文和代码
【导读】知识图谱一直是学术界和工业界关注的热点。随着AAAI2020的到来,专知小编整理了最新10篇关于知识图谱的论文,来自清华大学、中科大、北航、中山大学、UCL、Facebook、腾讯、阿里巴巴等,包含义原知识图谱、知识图谱表示学习、知识迁移、知识图谱层次表示、常识知识图谱补全等,请大家查看!

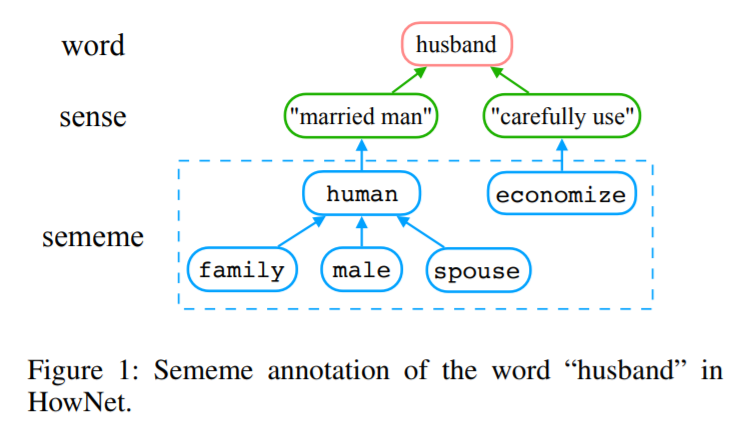
1、Towards Building a Multilingual Sememe Knowledge Base: Predicting Sememes for BabelNet Synsets(建立多语言义原知识库:预测BabelNet Synsets的义原)
AAAI2020 oral ,清华大学
作者:Fanchao Qi, Liang Chang, Maosong Sun, Sicong Ouyang, Zhiyuan Liu
摘要:义原是人类语言中最小的语义单位。义原知识库(KBs)包含了由义原标注的词,已成功地应用于许多自然语言处理任务中。然而,现有的义原KBs仅建立在少数几种语言上,这阻碍了它们的广泛应用。为了解决这个问题,我们提出基于BabelNet(一种多语言百科词典)为多种语言构建统一的义原知识库。我们首先构建一个作为多语言义原知识库种子的数据集。它为超过15000个synset (BabelNet的条目)手工注释义位。然后,我们提出了一种新的自动预测synsets义位的任务,目的是将种子数据集扩展成一个可用的知识库。我们还提出了两个简单有效的模型,利用了不同的synsets信息。最后,我们进行了定量和定性分析,以探索任务中的重要因素和困难。所有的源代码和数据,这项工作可以获得
https://github.com/thunlp/BabelNet-Sememe-Prediction
论文地址:
https://www.zhuanzhi.ai/paper/a9486b11f2d44f239cd36c209b312946
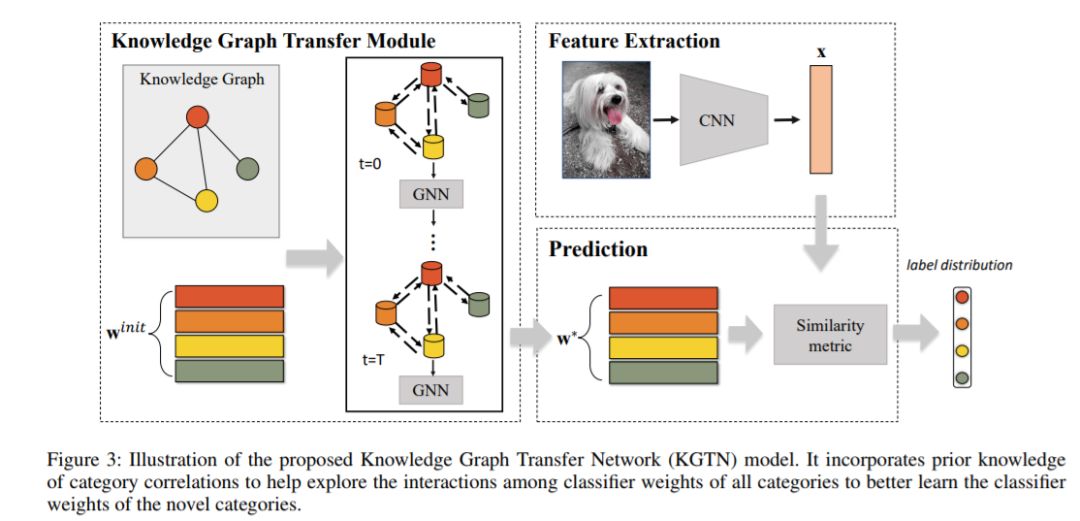
2、Knowledge Graph Transfer Network for Few-Shot Recognition(知识图谱迁移网络小样本识别)
AAAI2020 oral ,中山大学,暗物质
作者:Riquan Chen, Tianshui Chen, Xiaolu Hui, Hefeng Wu, Guanbin Li, Liang Lin
摘要:小样本学习的目标是在给定一些基类有充足训练样本的情况下,从非常少的样本中学习新的类别。这个任务的主要挑战是新类很容易由颜色、质地、形状的物体或背景上下文(即特异性),这特别是对于训练样本少且不常见的相应的类别非常突出(见图1)。幸运的是,我们发现迁移信息的相关类别可以帮助学习新概念,从而避免新概念主导的特异性。此外,结合不同类别之间的语义关联可以有效地规范这种信息传递。在本文中,我们将语义关联以结构化的知识图谱的形式表示出来,并将此图集成到深度神经网络中,通过一种新的知识图谱传输网络(KGTN)来促进小样本学习。具体地,通过使用对应类别的分类器权值初始化每个节点,学习一种传播机制,通过图来自适应地传播节点消息,探索节点间的交互,将基类的分类器信息传递给新类别的分类器信息。在ImageNet数据集上的大量实验表明,与当前领先的对比方法相比,性能有了显著的改进。此外,我们还构建了一个覆盖更大范围类别的ImageNet-6K数据集。在这个数据集上的实验进一步证明了我们提出的模型的有效性。
论文地址:
https://www.zhuanzhi.ai/paper/391fa8f7db194b700d66a14a75b714bd
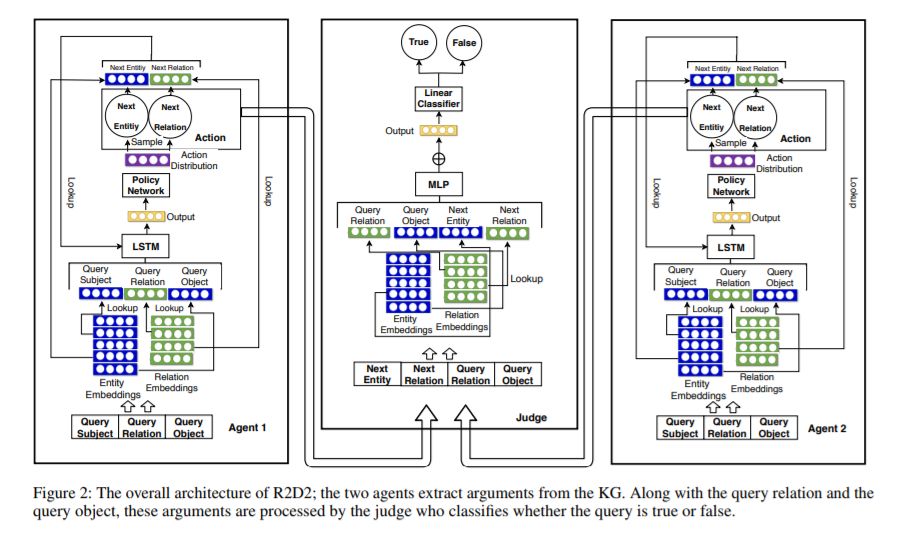
3、Reasoning on Knowledge Graphs with Debate Dynamics(基于辩论动力学的知识图谱推理)
AAAI2020 ,Siemens Corporate Technology
作者:Marcel Hildebrandt, Jorge Andres Quintero Serna, Yunpu Ma, Martin Ringsquandl, Mitchell Joblin, Volker Tresp
摘要:我们提出了一种基于辩论动力学的知识图谱自动推理方法。其主要思想是将三元组分类任务框定为两个抽取论点(知识图谱中的路径)的强化学习代理之间的辩论游戏,目标分别是促进事实为真(正题)或事实为假(反题)。基于这些论据,一个叫做“法官”的二元分类器决定事实是对还是错。这两个代理可以被看作是稀疏的、对抗性的特征生成器,它们为正题或反题提供了可解释的证据。与其他黑盒方法相比,这些参数允许用户了解法官的决定。由于这项工作的重点是创建一个可解释的方法,以保持一个有竞争力的预测精度,我们基准的三重分类和链接预测任务我们的方法。因此,我们发现我们的方法优于基准数据集FB15k-237、WN18RR和Hetionet上的几个基线。我们也进行了一个调查,发现提取的参数对用户是有益的。
论文地址:
https://www.zhuanzhi.ai/paper/81aa00f925a022ed59d97dcce89c11d6
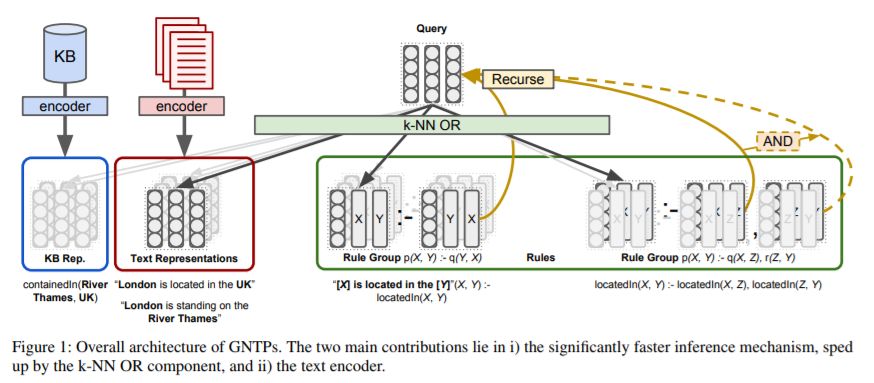
4、Differentiable Reasoning on Large Knowledge Bases and Natural Language(大规模知识库与自然语言上的可微分推理)
AAAI2020 ,UCL Centre for Artificial Intelligence, University College London,Facebook AI Research
作者:Pasquale Minervini, Matko Bošnjak, Tim Rocktäschel, Sebastian Riedel, Edward Grefenstette
摘要:用自然语言和知识库(KBs)表达的知识进行推理是人工智能面临的主要挑战,在机器阅读、对话和问题回答等方面都有应用。联合学习文本表示和转换的一些神经体系结构非常缺乏数据效率,很难分析它们的推理过程。这些问题由端到端的可微推理系统(如神经定理证明程序(NTPs))来解决,尽管它们只能用于小型符号KBs。在本文中,我们首先提出贪心NTPs (GNTPs),这是NTPs的扩展,解决了它们的复杂性和可伸缩性限制,从而使它们适用于真实世界的数据集。该结果是通过动态构建NTPs的计算图来实现的,并且只包含推理过程中最有希望的证明路径,从而获得更有效的模型。然后,我们提出了一种新的方法,通过在一个共享的嵌入空间中嵌入逻辑事实和自然语言句子来联合推理KBs和篇章提及。我们发现,GNTPs的性能与NTPs相当,但成本仅为NTPs的一小部分,同时在大型数据集上获得了具有竞争力的链接预测结果,为预测提供了解释,并引入了可解释的模型。源代码,数据集,和补充材料可在网上
https://github.com/uclnlp/gntp
论文地址:
https://www.zhuanzhi.ai/paper/5c5ba7a95bb0678315804cffdac41599
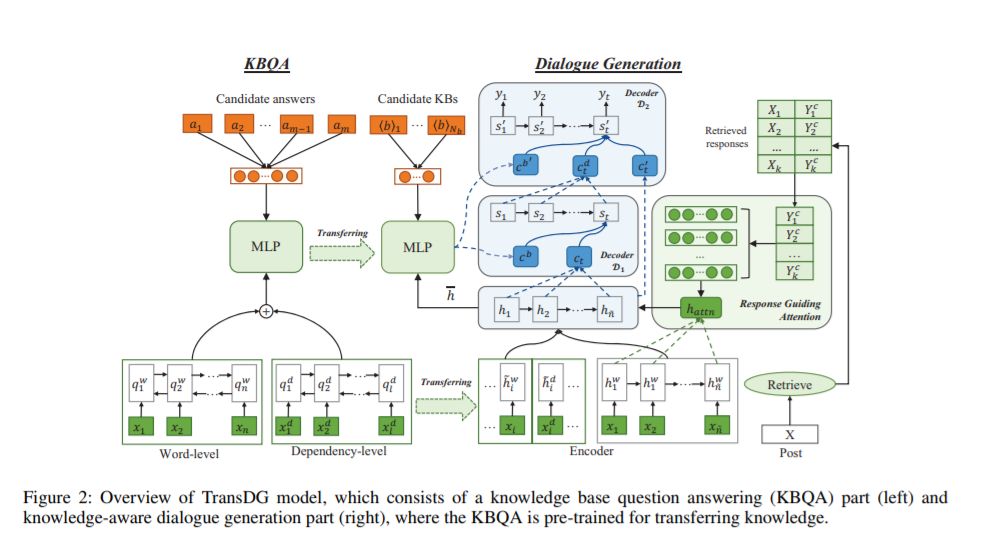
5、Improving Knowledge-aware Dialogue Generation via Knowledge Base Question Answering(通过知识库问题回答来改进知识感知对话的生成)
AAAI2020 ,华南理工,腾讯
作者:Jian Wang, Junhao Liu, Wei Bi, Xiaojiang Liu, Kejing He, Ruifeng Xu, Min Yang
摘要:神经网络模型常常面临将常识引入开放域对话系统的挑战。本文提出了一种新的知识感知对话生成模型(TransDG),该模型将基于知识库问答(KBQA)任务的问题表示和知识匹配能力进行转换,以促进话语理解和对话生成的事实知识选择。此外,我们提出了一种响应引导注意和多步骤解码策略,以指导我们的模型将重点放在用于响应生成的相关特征上。在两个基准数据集上的实验表明,该模型在生成信息丰富、流畅的对话方面具有较强的优越性。我们的代码在
https://github.com/siat-nlp/TransDG.
论文地址:
https://www.zhuanzhi.ai/paper/9a1e55686d9b78f5c2569a607fa504b2
6、Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction(用于链接预测的学习层次感知知识图嵌入)
AAAI2020 ,中科大
作者:Zhanqiu Zhang, Jianyu Cai, Yongdong Zhang, Jie Wang
摘要:知识图谱嵌入的目的是将实体和关系表示为低维向量(或矩阵、张量等),已经被证明是一种预测知识图谱中缺失链接的强大技术。现有的知识图谱嵌入模型主要侧重于对称/反对称、反转、复合等关系模式的建模。然而,许多现有的方法无法对语义层次结构建模,而这在实际应用程序中是很常见的。为了解决这一问题,我们提出了一种新的知识图谱嵌入模型——层次感知知识图谱嵌入(HAKE),它将实体映射到极坐标系统中。HAKE的灵感来自于这样一个事实,即在极坐标系统中的同心圆可以自然地反映层次结构。具体来说,径向坐标的目标是在层次结构的不同层次上对实体进行建模,半径较小的实体被期望在更高的层次上;角坐标的目的是区分层次结构中同一层次上的实体,这些实体的半径大致相同,但角度不同。实验表明,HAKE可以有效地对知识图谱中的语义层次进行建模,并在链接预测任务的基准数据集上显著优于现有的最先进的方法。
.

论文地址:
https://www.zhuanzhi.ai/paper/1369a6bd83e18cd1e6eeb97d883bb652
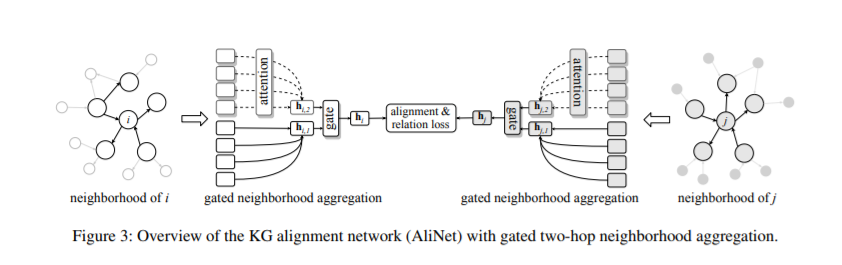
7、Knowledge Graph Alignment Network with Gated Multi-hop Neighborhood Aggregation(用具有门控多跳邻居聚合的知识图谱对齐网络)
AAAI2020 ,南京大学,阿里巴巴
作者:Zequn Sun, Chengming Wang, Wei Hu, Muhao Chen, Jian Dai, Wei Zhang, Yuzhong Qu
摘要:图神经网络由于具有识别同构子图的能力,已经成为一种强大的基于嵌入的实体对齐范式。然而,在实知识图(KGs)中,对应实体通常具有非同构的邻域结构,这很容易导致gnn产生不同的表示。为了解决这一问题,我们提出了一种新的KG对齐网络,即AliNet,旨在以端到端方式缓解邻域结构的非同构性。由于模式异构性,对等实体的直接邻居通常是不相似的,AliNet引入了远程邻居来扩展它们的邻居结构之间的重叠。它采用了一种注意机制,以突出有益的遥远的邻居和减少噪音。然后,利用门控机制控制直接和远处邻居信息的聚合。我们进一步提出了一个关系损失来细化实体表示。我们进行了深入的实验,详细的烧蚀研究和分析的五个实体对齐数据集,证明了AliNet的有效性。
.
论文地址:
https://www.zhuanzhi.ai/paper/bc1ac5e992eb35a3f3a5f7fffee3368a
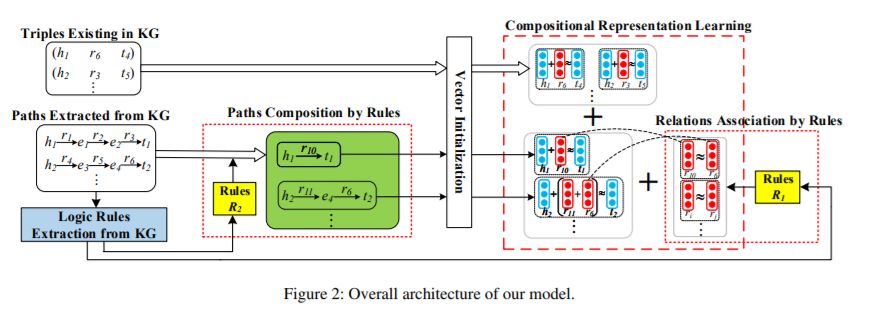
8、Rule-Guided Compositional Representation Learning on Knowledge Graphs(规则指导的知识图谱组合式表示学习)
AAAI2020 ,北航
作者:Guanglin Niu, Yongfei Zhang, Bo Li, Peng Cui, Si Liu, Jingyang Li, Xiaowei Zhang
摘要:知识图谱的表示学习是将知识图中的实体和关系嵌入到低维连续向量空间中。早期的KG嵌入方法只关注三元组编码的结构化信息,由于KGs的结构稀疏性,导致其性能有限。最近的一些尝试考虑路径信息来扩展KGs的结构,但在获取路径表示的过程中缺乏可解释性。本文提出了一种新的基于规则和路径的联合嵌入(RPJE)方案,该方案充分利用了逻辑规则的可解释性和准确性、KG嵌入的泛化性以及路径的补充语义结构。具体来说,首先从KG中挖掘出不同长度(规则体中的关系数)的Horn子句形式的逻辑规则,并对其进行编码,用于表示学习。然后,利用长度2的规则来精确地组合路径,而使用长度1的规则来明确地创建关系之间的语义关联和约束关系嵌入。优化时还考虑了规则的置信度,保证了规则在表示学习中的可用性。大量的实验结果表明,RPJE在KG完成任务上的表现优于其他最先进的基线,这也证明了利用逻辑规则和路径来提高表示学习的准确性和可解释性的优越性。
.
论文地址:
https://www.zhuanzhi.ai/paper/bc1ac5e992eb35a3f3a5f7fffee3368a
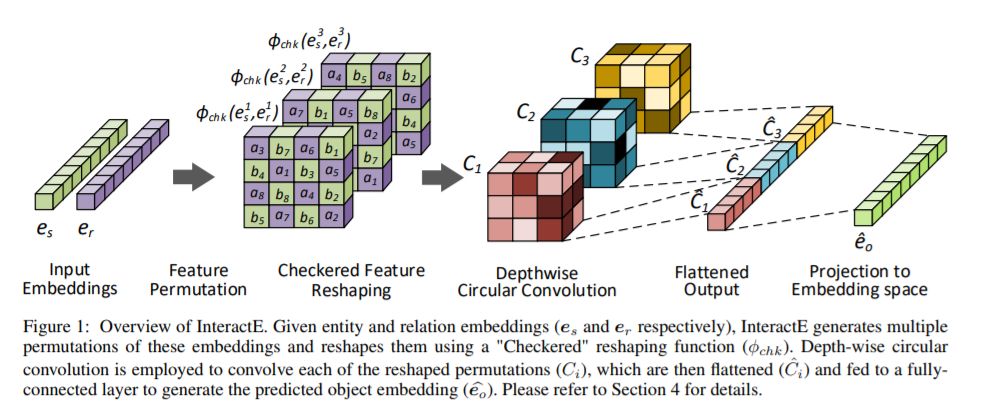
9、InteractE: Improving Convolution-based Knowledge Graph Embeddings by Increasing Feature Interactions(规InteractE:通过增加特征交互来改进基于卷积的知识图谱嵌入)
AAAI2020 ,Indian Institute of Science, Columbia University
作者:Shikhar Vashishth, Soumya Sanyal, Vikram Nitin, Nilesh Agrawal, Partha Talukdar
摘要:现有的知识图谱大多存在不完备性,可以通过基于已知事实推断缺失的链接来缓解不完备性。一种流行的方法是生成实体和关系的低维嵌入,并使用它们进行推论。ConvE是最近提出的一种方法,它将卷积滤波器应用于实体和关系嵌入的二维重塑,以捕获其组件之间丰富的交互。然而,ConvE能够捕获的交互的数量是有限的。在这篇论文中,我们分析了增加这些相互作用的数量如何影响链路预测性能,并利用我们的观测结果提出了相互作用。InteractE基于三个关键思想:特征置换、新颖的特征重塑和循环卷积。通过大量的实验,我们发现InteractE在FB15k-237上的性能优于最先进的卷积链路预测基线。此外,InteractE在FB15k-237、WN18RR和YAGO3-10数据集上的MRR评分分别比ConvE高9%、7.5%和23%。结果验证了我们的中心假设——增加特征交互有助于链接预测性能。我们提供InteractE的源代码,以鼓励可重复的研究。
http://github.com/malllabiisc/ InteractE.
.
论文地址:
https://www.zhuanzhi.ai/paper/5bbb1f49b1b4b26b6d1de5c7dce3a953
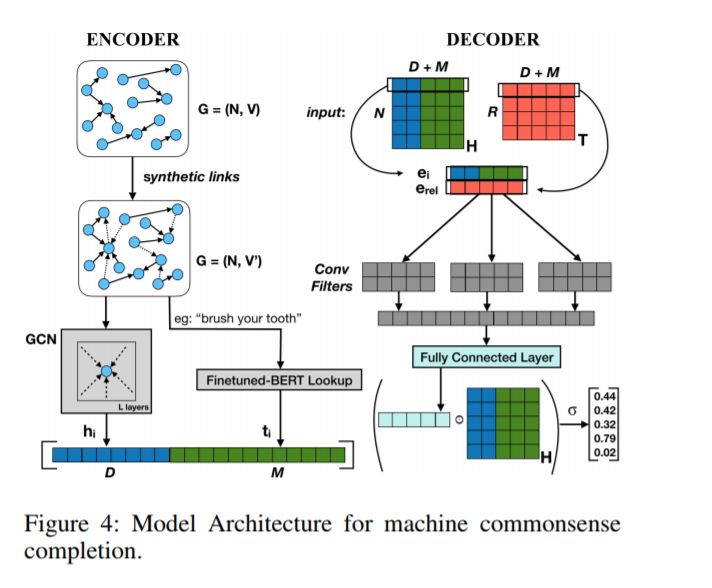
10、Commonsense Knowledge Base Completion with Structural and Semantic Context(具有结构和语义上下文的常识知识库的完成)
AAAI2020 ,Allen Institute for Artificial Intelligence 华盛顿大学
作者:Chaitanya Malaviya, Chandra Bhagavatula, Antoine Bosselut, Yejin Choi
摘要:与经过大量研究的传统知识库(如Freebase)相比,对常识知识图谱(如原子图和概念图)的自动知识库补全带来了独特的挑战。常识知识图谱使用自由格式的文本来表示节点,这使得节点的数量比传统KBs多了几个数量级(ATOMIC比Freebase多18倍(FB15K-237))。重要的是,这意味着图数据结构将显著稀疏化——这是现有KB补全方法面临的主要挑战,因为这些方法在相对较小的节点集上采用密集连接的图数据。在本文中,我们提出了新的知识库完成模型,该模型可以通过利用节点的结构和语义上下文来解决这些挑战。具体来说,我们研究了两个关键的思想: (1) 从局部图结构学习,使用图卷积网络和自动图加密,(2) 从预先训练的语言模型学习到知识图谱,以增强知识的上下文表示。我们描述了将来自这两个来源的信息合并到一个联合模型中的方法,并提供了原子知识库完成和使用ConceptNet上的排名指标进行评估的第一个经验结果。我们的结果证明了语言模型表示在提高链接预测性能方面的有效性,以及在训练子图以提高计算效率时从局部图结构(对ConceptNet的MRR +1.5分)学习的优势。对模型预测的进一步分析揭示了语言模型能够很好地捕捉到的常识类型。
.
论文地址:
https://www.zhuanzhi.ai/paper/535d810640d4b84fb46f3fd7e678f423
便捷查看下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“KG20” 就可以获取《AAAI2020必读的10篇「知识图谱(Knowledge Graph)」相关论文和代码》专知下载链接索引







