数据中心AI Inference芯片今年能达到什么样的性能?
在之前回看AI芯片初创公司的时候,我又看了一下17年底的明星公司Groq的网站。虽然一年多没有更新了,但即使放到现在,他们当时提出的目标性能也还是挺强的。从公开信息来看,目前还没人能做到这个指标。于是我开始思考一个问题:到今年底,数据中心的AI Inference芯片到底能达到什么样的性能?
2017年底到18年初,Groq在他们的网站提出了芯片目标,看起来还是很吸引人的。我当时也写文章做了一点分析,Groq把AI芯片的性能推向新高。一个基本判断是,如果他们沿用Google TPU的Systolic Array(脉动阵列 - 因Google TPU获得新生)架构,用16nm或更先进的工艺,在INT8精度下实现如下图所示400TOPS的峰值运算能力是可能的;8TOPS/W的能耗效率挑战比较大,也不是完全没可能。
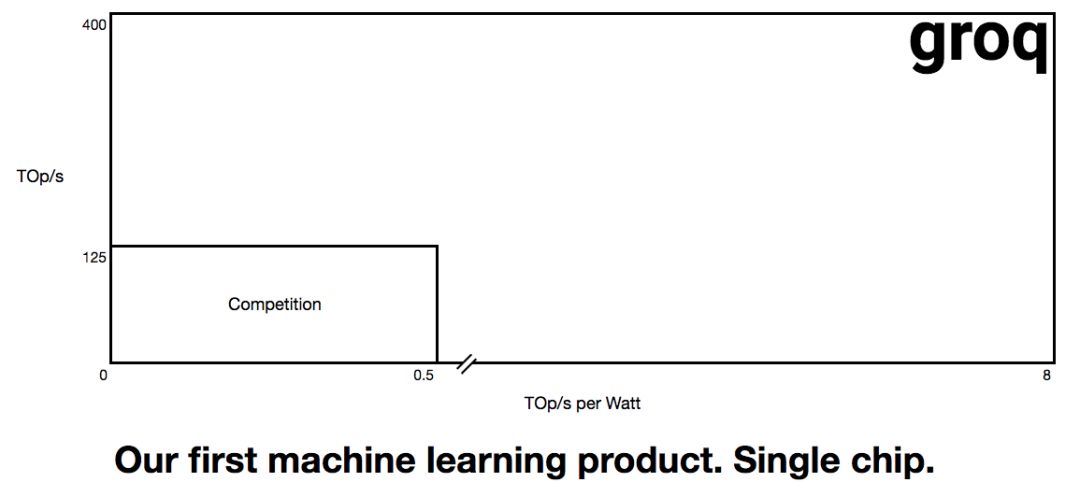
source:groq.com
后来,Groq又放出了另外两个指标(如下图),就更又意思了。
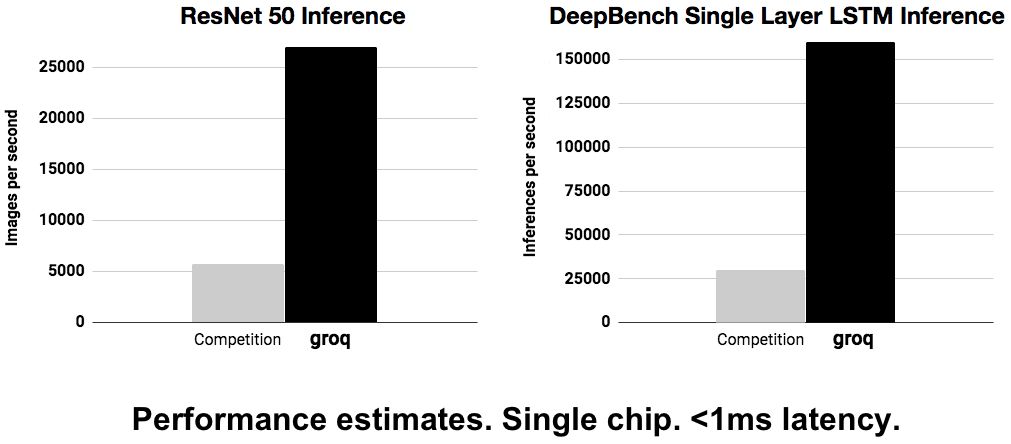
source:groq.com
在这个图里,groq提出了两个Inference应用的指标。首先是针对图像的ResNet 50 Inference,实现超过25,000张图像/秒。ResNet50做一幅图的前向大约需要3.9GMAC,将近8GOPS。如果达到groq所提指标,每秒的运算超过25000 x 8 = 200,000GOPs=200TOPs。如果他们的峰值性能是400T,则在做ResNet50时的实际利用率超过50%。另外,groq的指标里还提出单芯片的延时小于1ms。
作为对比,我们看一下目前公开数据中inference性能最高的Habana的Goya芯片,其性能如下图。ResNet-50 inference的处理能力是15,012张图像/秒,其延时为1.3ms。
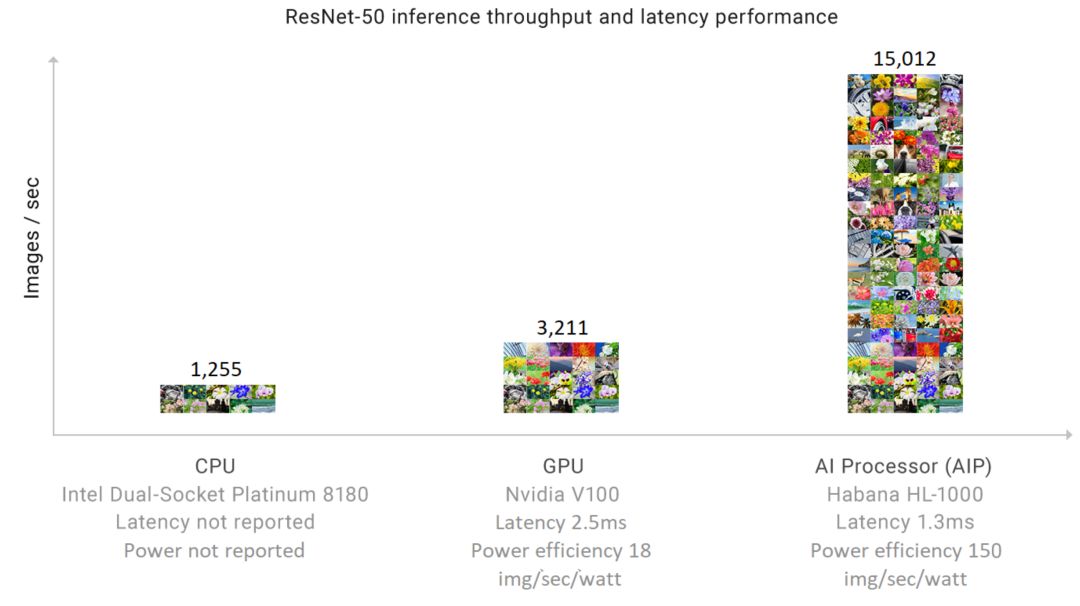
source: habana.ai
以下是和其它一些Inference方案的对比。

source: habana.ai
Habana最近还公布了更详细的benchmark结果,如下图。可以看出ResNet-50最好的情况是batch size为10,达到15,393张图/秒,此时的延时是1.01ms(如果batch size为1,延时则为0.29)。
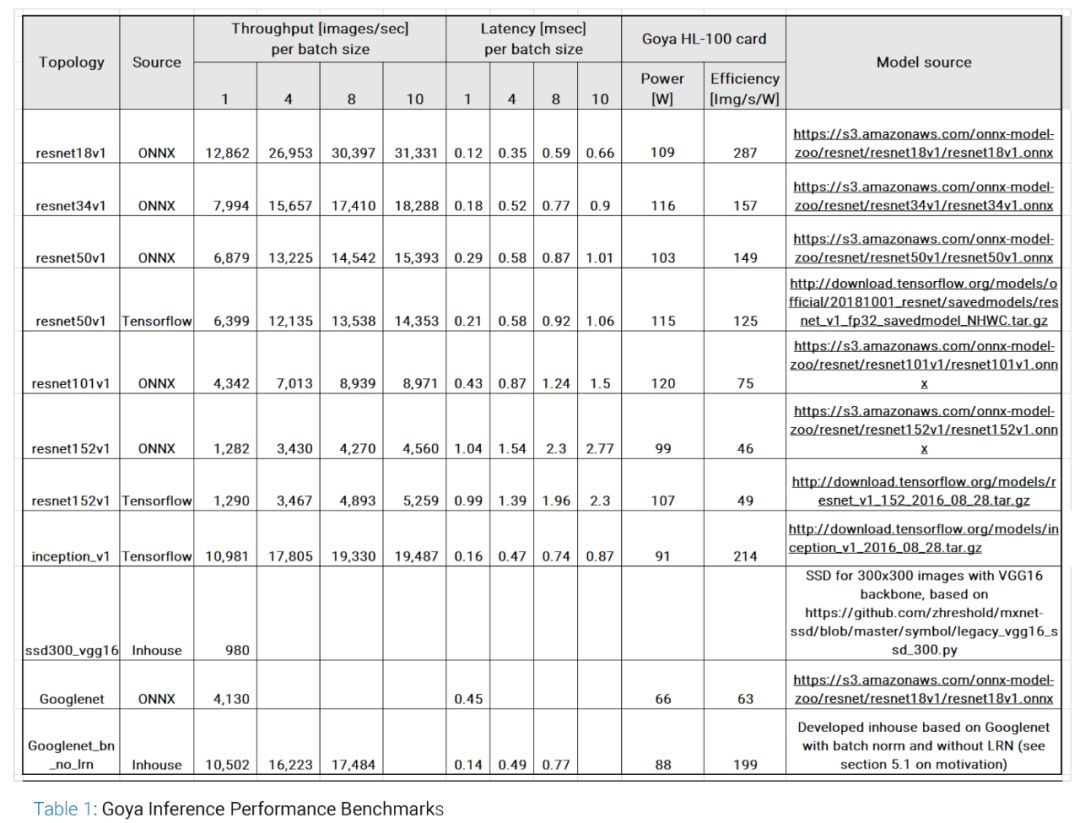
source: habana.ai
我们再看看能耗效率,最好的情况是使用inception_v1网络时的214 img/s/W,最差为ResNet-152(ONNX)的49 img/s/W。由于每种网络的运算特征不太一样,我们还是看看ResNet-50(ONNX),149 img/s/W。149 img/s大约相当于1.2TOPS,因此Habana Goya芯片实测的能耗效率是高于1TOPS/W的。
综合来看,Habana Goya芯片虽然是目前公开信息且有产品的芯片中性能最好的Inference芯片,其性能距离Groq最初订下的目标还是有差距的,而能耗效率的差距就更大了。当然,Groq毕竟还没拿出东西,也只能做个参考了。
我们再看一下第二个应用指标,DeepBench Single Layer LSTM Inference。DeepBench(给DNN处理器跑个分 - 设计篇)中的LSTM有很多种情况,groq提出的这个数据具体针对哪种我们还不好说。我们可以参考一下Grapcore的一个Benchmark结果(如下图所示)。这里要说明一下,Gorphcore的目标应用是training,所以这个inference参数只能做个参考。
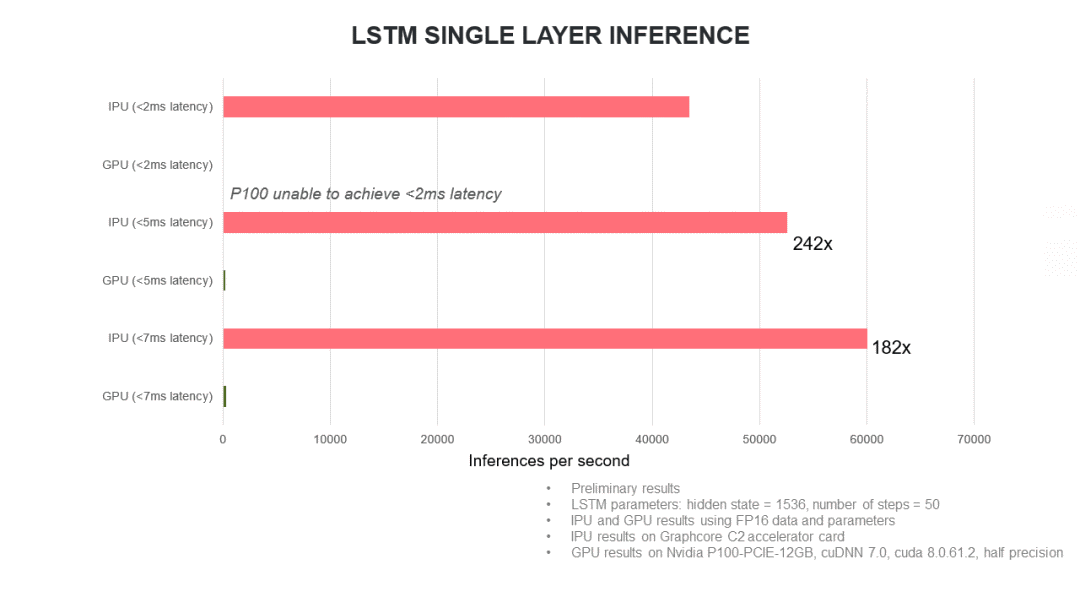
source:www.graphcore.ai
这个数据使用的配置是1536个hidden state,50 timestep,半精度数值。猜想Groq的指标大约也是这个配置,INT8精度,每秒能够做超过150,000次inference。这里值得注意的是,groq同时提出了两个指标,分别针对CNN和RNN。而我们知道一款芯片很难同时有效的支持这两类运算。比如,我们看Google第一代TPU给出的数据,跑LSTM的效率就很低(下图)。因此Groq同时提着两个指标是否现实还是有疑问的。
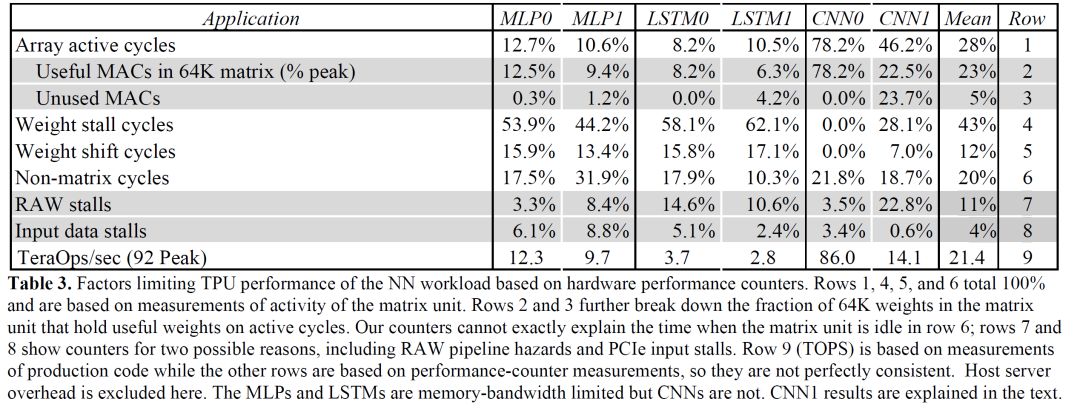
source:Google
下面回到我们的问题:到今年底,数据中心的AI Inference芯片到底能达到什么样的指标?
我们可以以Habana的实测结果作为一个参考,如果他们年内推出下一代采用新工艺的Inference芯片,性能提升50%以上是很有可能的,这样就可以接近Groq提出的> 25,000 img/s的指标。因此我们不妨把图像处理能力的预期定在这个指标。而根据Habana目前的测试结果,在这个指标下延时小于1ms也是合理的预期。比较难估计的是功耗效率,Groq提出的目标是8 TOPS/W,而目前Habana大约是1~2TOPS/W,差别还是比较大的。因此,如果年内可以实现>4TOPS/W的实测功耗效率,应该也是个不错的结果。综上,我们可以大胆预测一下,数据中心的Inference芯片,在图像处理方面,今年内应该可以达到如下指标:
Resnet-50 inference throughput:>25,000 image/sec (INT8)
Resnet-50 Latency (batch size for max throughput): < 1ms
Power efficiency:>4 TOPS/W
这里有几个问题解释一下:
首先是选什么指标的问题。到目前为止,大家还是多用TOPS(或者TMAC/s等等)和TOPS/W来描述AI芯片的处理能力和功耗效率。但这两个指标往往反映的是理想情况,基本是芯片中放了多少MAC再乘上时钟频率。而在运行实际应用的时候,这样的理论值是很难达到的,甚至相差很大,能到50%已经相当不错了。而实际的利用率,既和神经网络的类型和应用的运行环节相关,又和芯片架构,软件工具等因素有关。所以比较好的方式还是用实际应用运行的情况来作为评价指标。但是,实际的应用(网络)五花八门,如果都作为指标也不现实。因此,从目前的实践来看,针对图像的应用的Inference芯片,以ResNet-50为参考网络,以每秒能处理多少张图像作为指标是相对比较合理的,也很可能在一段时间内成为业界公认的标准。对于Inference芯片来说,对特定应用实现的效率是最重要的。而对于Training芯片则必须能够支持所有的应用,还是用MLPerf做Benchmark比较好。我之前对Benchmark已经做过相当多的讨论,大家可以参考“如何评测AI系统?”,“给DNN处理器跑个分 - BenchIP”,“给DNN处理器跑个分 - 指标篇”,“给DNN处理器跑个分 - 设计篇”。当然,我们在后面的产品发布的时候还是会看到对指标的不同选择,这个也无可厚非,毕竟大家都希望拿出一个比较亮眼的成绩,只要指标是合理真实就可以。
值得注意的是,讨论这个指标还需要明确数据类型,对数据中的inference来说,INT8是比较常用的选择。因此,我上面的预测也是针对INT8的。当然,这里不是说芯片只支持INT8,一般还会支持其它的数据类型,比如FP16/FP32等等,只是我们在讨论性能指标的时候必须说明该数据针对的数据类型。
芯片工艺对最终的性能指标影响还是很大的。上述指标相信对7nm芯片来说是比较容易实现的。如果今年的主流还是10~16nm,那么实现起来需要芯片架构,软件工具都做到比较优化。
上述指标主要还是描述一个比较通用的Inference的能力,有可能有些芯片在这个能力之上有其它的侧重点,比如有的更偏视频处理,那么可能要看一些其它的指标。
另一个有待观察的问题是云端Inference芯片对于RNN类网络的支持。Groq提出LSTM Inference的指标和Graphcore给出的测试结果可能都不具备代表性,所以我们也很难做出预测。现在还不清楚未来NLP和其它依靠RNN的应用是否能够催生专门对其优化的芯片,又或者Inference芯片还是主要以CNN加速为主,只是尽量兼顾RNN的效率。
最后,上述预测只能算一个小小的思维游戏,可能有很多不严谨的地方,所以结果不用太当真,也欢迎大家在留言区提出自己的看法。
- END-
推荐阅读:
Petascale AI芯片Vathys:靠谱项目?清奇脑洞?还是放卫星?
题图来自网络,版权归原作者所有
本文为个人兴趣之作,仅代表本人观点,与就职单位无关



