TensorFlow 2.0正式版官宣!深度集成Keras

新智元报道
新智元报道
来源:medium、GitHub
编辑:小芹、大明
【新智元导读】TensorFlow 2.0正式版终于发布了!深度集成Keras,更简单、更易用,GPU训练性能提升。这是一个革命性的新版本,欢迎来到 TensorFlow 2.0!>>> 人工智能改变中国,我们还要跨越这三座大山 | 献礼 70 周年
TensorFlow 2.0正式版终于发布了!
谷歌今天宣布,开源机器学习库TensorFlow 2.0现在可供公众使用。
TensorFlow 2.0的Alpha版本今年初在TensorFlow开发者大会上首次发布,经过近7个月的不断修改、更新,TensorFlow 2.0正式版可谓是千呼万唤始出来。

作为最受欢迎的机器学习库之一,自2015年谷歌大脑团队发布TensorFlow以来,TensorFlow框架已被下载超过4000万次。
为了提高易用性,TensorFlow 2.0进行了许多修改,如取消了一些被认为是多余的API,并紧密集成和依赖tf.keras作为中央高级API。TensorFlow与Keras深度学习库的集成化最初始于2017年2月发布的TensorFlow1.0,本次更新让二者的集成程度进一步提高。
此外,当在Nvidia的Volta和Turing GPU上运行时,新版本的性能表现可以提高三倍。
下面,我们带来对TensorFlow 2.0 新特性的具体介绍。
TensorFlow 2.0专注于简单性和易用性,主要更新如下:
可使用Keras轻松进行模型构建,可立即执行,直观调试。
在任何平台上的生产中都可以进行稳健的模型部署。
提供强大的研究实验支持。
减少了重复,移除了不建议使用的端点,简化了API。

TensorFlow 2.0使得机器学习应用的开发更加容易。通过将Keras紧密集成到TensorFlow中、默认eager execution,以及Python函数执行,TensorFlow 2.0开发应用程序的经验会让Python开发者很熟悉。对于那些想要突破机器学习边界的研究人员来说,我们在TensorFlow的底层API上投入了大量的精力:我们现在导出了所有内部使用的操作,并且为诸如变量和checkpoint等关键概念提供了可继承的接口。允许用户构建TensorFlow的内部构件,而无需重建TensorFlow。
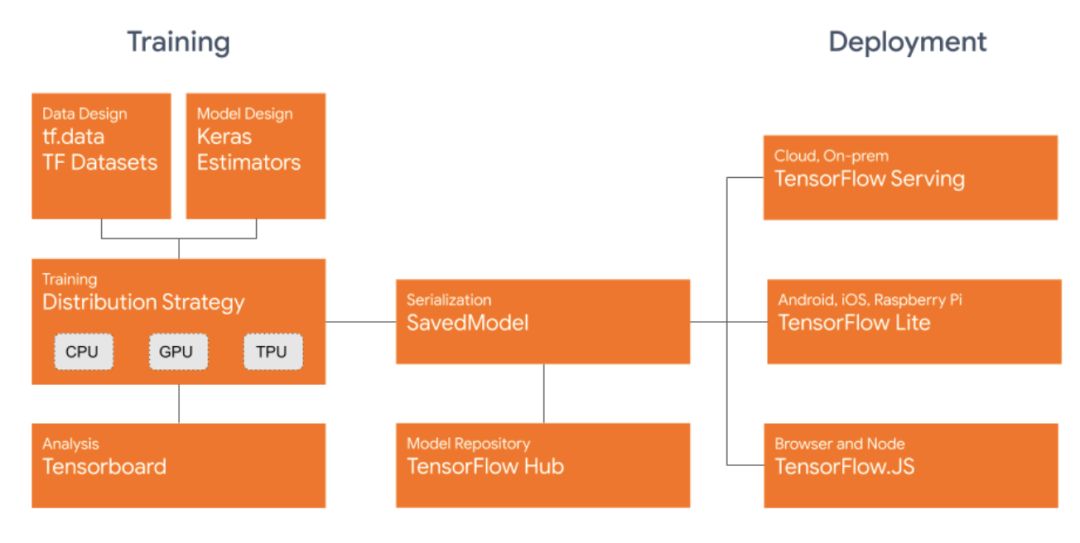
能够在各种runtimes(包括云、web、浏览器和Node.js,移动和嵌入式系统)上运行模型,我们对SavedModel文件格式进行了标准化。这允许用户使用TensorFlow运行模型,使用TensorFlow服务部署模型,使用TensorFlow Lite在移动和嵌入式系统上使用模型,使用TensorFlow.js在浏览器或Node.js上训练和运行模型。
对于高性能的训练场景,你可以使用 Distribution Strategy API以最小的代码更改来分布训练,并获得出色的开箱即用性能。它通过 Keras 的 Model.fit 支持分布式训练,还支持自定义训练循环。此外,现在可以使用多GPU支持,Cloud TPU支持将在未来发布。
查看分布式训练指南了解更多:
https://www.tensorflow.org/guide/distributed_training
TensorFlow 2.0在GPU上提供了许多性能改进。TensorFlow 2.0通过在Volta和Turing GPU上使用混合精度和几行代码(例如在ResNet-50和BERT中使用的),将训练性能提高了 3 倍。TensorFlow 2.0与TensorRT紧密集成,并使用改进的API在谷歌云上的NVIDIA T4 Cloud GPU上进行推理时提供更好的可用性和高性能。
在TensorFlow中构建模型时,对训练和验证数据的有效访问是至关重要的。我们引入了TensorFlow Datasets,为包含各种数据类型(如图像、文本、视频等)的大量数据集提供了一个标准接口。
虽然仍然保留了传统的基于会话的编程模型,但我们建议使用常规的Python开发和eager execution。tf.function可用于将代码转换成可远程执行的、序列化和性能优化的图形。此外,Autograph还可以将常规的Python控制流直接转换为TensorFlow控制流。
如果你使用过TensorFlow 1.x,这里有一个迁移到2.0的官方指南:
https://www.tensorflow.org/guide/migrate
TensorFlow 2.0也包括一个自动转换脚本。
我们已经与谷歌内部和TensorFlow社区的许多用户合作,测试了TensorFlow 2.0的功能,并对反馈感到非常兴奋。例如,谷歌新闻团队在TensorFlow 2.0中启用了基于BERT的语言理解模型,从而极大地改进了新闻报道的覆盖率。TensorFlow 2.0提供易于使用的API和快速实现新想法的灵活性,模型训练和服务被无缝地集成到现有的基础架构中。
而且,ML不仅是Python开发者专属—JavaScript开发者可以使用TensorFlow.js进行训练和推理。Swift语言的支持也正在进行中。
主要特点和功能改进
将Keras作为构建和训练模型的中央高级API。 Keras提供了一些模型构建API,如顺序列化、函数化、子类化以及立即执行(用于立即迭代和直观调试)、tf.data(用于构建可扩展的输入pipeline)等。
更灵活的资源分配策略:TF 2.0用户将可以使用tf.distribute.StrategyAPI,通过最少的代码修正来分配训练策略,从而获得出色的现成性能。TF 2.0支持Keras model.fit以及自定义训练循环的分布式训练,还提供多GPU支持,以及对多工作人员和Cloud TPU的实验性支持。
建议使用函数,而不是会话。TF 2.0不鼓励使用传统的声明式编程模型来构建图形,再通过tf.Session执行,而是建议编写常规Python函数来代替这一过程。使用tf.function装饰器,可以将这些函数转换为图形,这些图形可以远程执行,序列化并针对性能进行优化。
实现tf.train.Optimizers和tf.keras.Optimizers的统一。对TF2.0使用tf.keras.Optimizers。作为公共API删除了compute_gradients,使用GradientTape计算梯度。
AutoGraph将Python控制流转换为TensorFlow表达式,允许用户在有tf.function的函数中编写常规Python语句。AutoGraph也适用于与tf.data,tf.distribute和tf.keras API一起使用的函数。
将交换格式统一为SavedModel。所有TensorFlow生态系统项目(TensorFlow Lite,TensorFlow JS,TensorFlow Serving,TensorFlow Hub)都接受SavedModels。模型状态应保存到SavedModels或从SavedModels恢复。
一些API的更改:部分API符号被重命名或删除,参数名称也已更改。许多更改都是出于提高一致性和清晰性的考虑。TF 1.x版本API在compat.v1模块中仍然可用。
清理了一些API:移除了tf.app,tf.flags和tf.logging以支持absl-py。不再使用如tf.global_variables_initializer和tf.get_global_step之类的辅助方法的全局变量。
自动混合精度图形优化器简化了将模型转换为float 16的过程,更便于在Volta和Turing张量核心上进行加速。可以使用tf.train.experimental.enable_mixed_precision_graph_rewrite()包装优化器类来启用此功能。
添加环境变量TF_CUDNN_DETERMINISTIC。设置为TRUE或“ 1”将强制选择确定性cuDNN卷积和最大池算法。启用此功能后,算法选择过程本身也是确定性的。
这里有一个方便的指南,了解如何有效使用TensorFlow 2.0中的所有新功能:
https://www.tensorflow.org/guide/effective_tf2
此外,为了简化TensorFlow 2.0的入门工作,官方发布了几个使用2.0 API的常用ML模型的参考实现:
https://www.tensorflow.org/resources/models-datasets
最后,两个免费在线课程不容错过:
https://www.coursera.org/learn/introduction-tensorflow
https://www.udacity.com/course/intro-to-tensorflow-for-deep-learning--ud187
GitHub:
https://github.com/tensorflow/tensorflow/releases/tag/v2.0.0
更多阅读:
TensorFlow 2.0 新鲜出炉!新版本,新架构,新特性
GitHub 12万星!TensorFlow 2.0 Beta新鲜出炉,最终API已定







