详解MLP系列|借助傅里叶变换的高效 token mixer:AFNO

极市导读
本文提出了一种借助傅里叶变换的高效 token mixer,AFNO。模型可以灵活地适应输入分辨率的变化,并且随着输入分辨率的增加呈 quasi-linear 增长。在几个下游任务和 ImageNet 大规模图像识别任务里面得到了超越以往基于傅里叶变换的 token mixer 对应的方法。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
8 AFNO:自适应傅里叶神经算子
(来自 NVIDIA,加州理工,斯坦福大学)
8.1 AFNO 原理分析
8 AFNO:自适应傅里叶神经算子
论文名称:Adaptive Fourier Neural Operators: Efficient Token Mixers for Transformers
论文地址:
https://arxiv.org/pdf/2111.13587.pdf
-
8.1 AFNO 原理分析
本文提出了一种 AFNO 模型,是 NVIDIA,加州理工,斯坦福大学的研究团队在 MLP-like 架构方面的探索。
Vision Transformer 模型使用自注意力机制 (Self-attention) 来捕获长距离的依赖关系,也就是图片块之间的相互关系。
Vision MLP 模型通过用跨空间位置的 MLPs 替换 Self-attention 层,在空域进行 tokens 间信息交换,进一步简化了空域信息的融合操作。
由于不像 CNN 那样引入了归纳偏置 (inductive bias),这两种模型有可能从原始数据中学到空间位置之间更加通用和灵活的关系。
但是,不论是 Vision Transformer 模型还是 Vision MLP 模型,都有个共同的缺点,就是模型在训练和推理时的计算复杂度随着 token (或者 patch) 的数量的增加而二次增长 。那么为了解决这个问题,Vision Transformer 模型和 Vision MLP 模型会首先对图片分 patch,比如一张 的图片,分为一堆 的 patch,那么一共就有14×14=196 个 patch,即 。通过这样的手段来控制计算复杂度不至于过大。
但是,这种设计可能会限制下游密集预测任务的应用,比如检测和分割任务。
为了再解决下游任务的问题,Swin Transformer 给出了一种很有效的解决方案,就是通过人为划分 window 的方式用 Local Self-attention 来取代 Global Self-attention,详细得方案可以参考下面的解读:
https://zhuanlan.zhihu.com/p/404001918
尽管在实践中有效,Local Self-attention 带来了相当多的手工选择 ,例如,窗口大小 (window size),填充策略 (padding strategy) 等。并限制了每一层的感受野大小。
所以,对于一个视觉骨干模型而言,以一种合适的方法去融合不同位置的 token 非常重要。找到一个好的 token mixer 是具有挑战性的,因为它需要:
-
能够适应不同分辨率大小的输入的情况。 -
能够推广到下游任务。
GFNet 提出了全局滤波器网络 (Global Filter Network, GFNet),一种概念简单且计算高效的架构:
https://zhuanlan.zhihu.com/p/418500459
具体是通过如下三个关键操作替代 ViT 中的自注意力层:
-
2D 离散傅里叶变换 (2D discrete Fourier transform):将输入的特征从空间域转化到频域。 -
频域特征与全局可学习滤波器的点乘操作。 -
2D逆傅里叶变换 (2D inverse Fourier transform):将特征从频域再转化到空间域。
由于是采用了傅里叶变换用于混合不同 token 的信息,所以全局滤波器相对于 Self-attention 和 MLP 要有效得多,这要归功于快速傅里叶变换算法 (FFT) 的 理论复杂度。但是缺点也很明显:就是在第2步的 "频域特征与全局可学习滤波器的点乘操作" 操作里面,随着输入分辨率的增加,这个模块的参数也会随之增加。而且,这一步也没有混合不同 channel 的信息。
本文提出了一个叫做自适应傅里叶神经算子 (Adaptive Fourier Neural Operators) 的东西作为 token mixer,它是基于傅里叶神经算子 (Fourier Neural operators, FNOs)。
下文定义模型中间层的特征为 , 为序列长度。定义第 个 token 为 。
把 Self-attention 写成核函数的形式
Definition 1 (Self Attention) Self-attention 的定义是 :
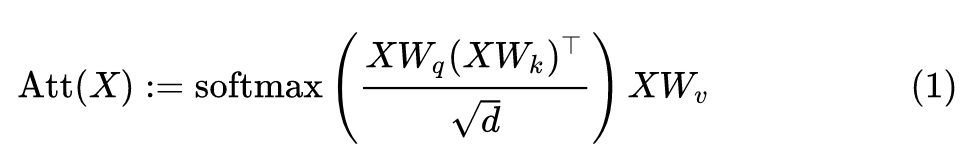
其中, 分别是 Query,Key 和 Value 矩阵, 是 attention 矩阵。Self-attention 的过程可以被写成下面的核函数的形式:
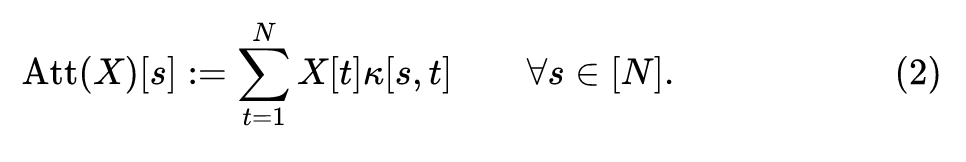
简单解释下这个公式的含义: 代表 矩阵的第 行,是一个 维的向量。它是一系列的 维向量 的加权和,其中 对应的权值是 。Attention 的这个过程可以看做是一个核函数:
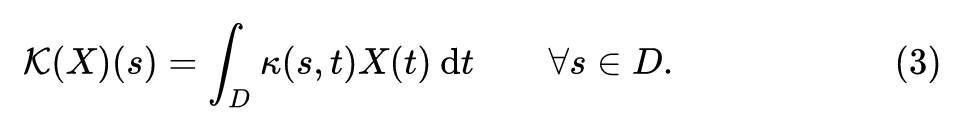
Fourier Neural Operator 的定义是:
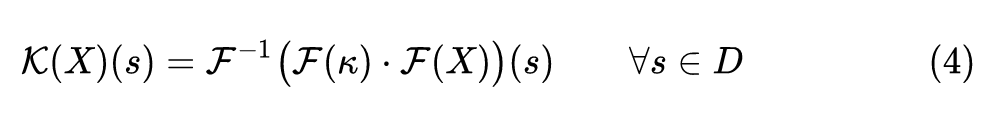
其中, 代表矩阵乘法,而 代表连续傅里叶变换及其逆变换。
本文基于 Fourier Neural Operator 的离散形式:
经离散化以后就变成了:
经离散化以后就变成了:
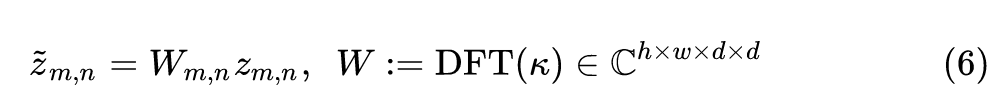
经离散化以后就变成了:
以上就是 Discrete FNO 的形式。相比于 GFNet,Discrete FNO 将第2步的 element-wise multiplication 改成了矩阵乘法。但是, 的参数依然是固定的,使得模型无法灵活地适应输入分辨率的变化。
所以本文的 Adaptive Fourier Neural Operator (AFNO) 就是为了解决这个问题。Discrete FNO 的参数量是 ,AFNO 把这个复数权值 分解为一堆共享的权重,每个权重的维度是 。这样,上式6就变成了:
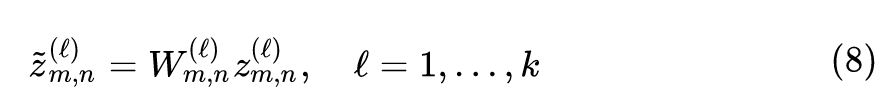
具体而言,作者使用的是一个双层的 MLP 结构:
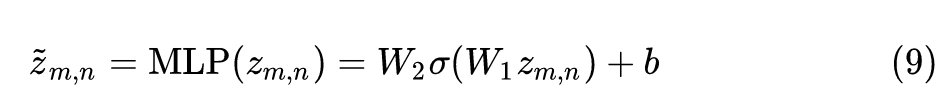
对于所有的 token 共享 。
AFNO 还使用了 Soft-Thresholding and Shrinkage 操作,目的是借助 LASSO 的思想为了让 token 尽量稀疏化。
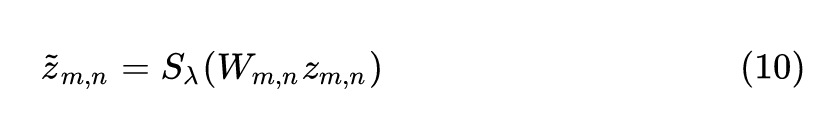
式中, ,其中 是控制稀疏度的调谐参数。另外值得注意的是,提升后的稀疏度还可以正则化网络,提高鲁棒性。
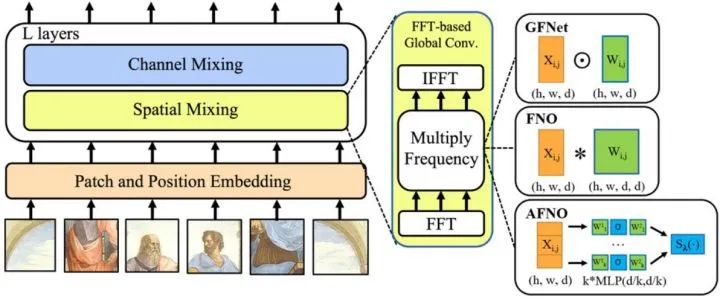
结合以上描述,AFNO 的伪代码和方法示意图如下图1所示。
def AFNO(x)
bias = x
x = RFFT2(x)
x = x.reshape(b, h, w//2+1, k, d/k)
x = BlockMLP(x)
x = x.reshape(b, h, w//2+1, d)
x = SoftShrink(x)
x = IRFFT2(x)
return x + bias
def BlockMLP(x):
x = MatMul(x, W_1) + b_1
x = ReLU(x)
return MatMul(x, W_2) + b_2
x = Tensor[b, h, w, d]
W_1, W_2 = ComplexTensor[k, d/k, d/k]
b_1, b_2 = ComplexTensor[k, d/k]
实验结果
Image Impainting 实验
作者对比了几个 token mixer 的 Image Impainting 实验结果。如下图2所示,AFNO 的性能与 Self-attention 相似,但是所需的计算量却比 Self-attention 要少很多。与 LS 和 GFN 相比,AFNO 在 PSNR 和 SSIM 的成绩明显更好。

Few-Shot Segmentation 实验
作者对比了几个 token mixer 的 Few-Shot Segmentation 实验结果。如下图3所示,显然,AFNO 的表现与 Self-attention 不相上下。此外,对于 out-of-domain 的数据集,如 ADE-Cars 或者 LSUNCats,它略优于 Self-attention,这部分归因于 AFNO 中赋予的稀疏正则化。

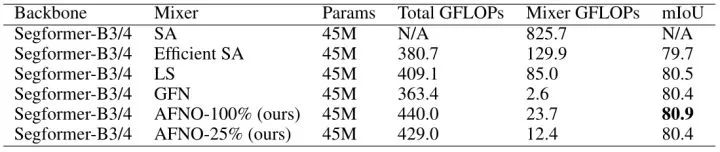
Cityscapes Segmentation 实验
作者也对比了 Cityscapes 数据集高分辨率 (1024×1024) 语义分割实验。模型使用的是 SegFormer-B3 backbone,实验结果如下表4所示。就 mIoU 指标而言,AFNO-100% 优于所有其他方法。AFNO-25% 仅保留25% 的低频,AFNO-100% 保留所有的频段。AFNO-25% 只损失了 0.05 mIoU,且与其他方法的性能相当。
ImageNet 实验结果
作者在以 ViT 为 backbone 的模型上面测试了 ImageNet 的实验结果,只替换不同的 token mixer。下图5展示了不同的 token mixer 的分类精度。可以观察到,AFNO 的 top-1 Accuracy 超过了 GFNet 多达2%,说明了 adaptive weight sharing 的有效性。

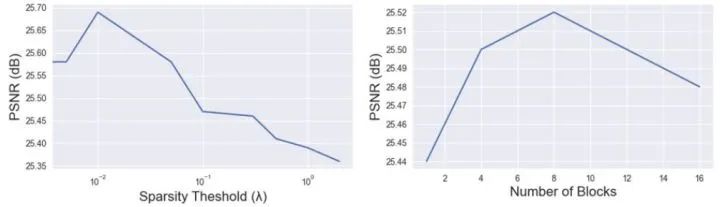
对比实验1:稀疏度阈值 和块的数量 的影响
如下图6所示为Sparsity Threshold 和模型深度的影响, 是 Soft-Thresholding and Shrinkage 里面的超参数,是控制模型稀疏度的超参数。对于每个 ,作者首先对网络进行预训练,然后在 CelebA-Faces 数据集上对分割模型进行微调。结果显示 时 PSNR 达到了峰值,证明当前条件的稀疏度是最有效的。作者也对比了8式中 值的影响,结果显示 时 PSNR 达到了峰值。
对比实验2:稀疏度阈值 和块的数量 的影响
如下图7所示为去除 adaptive weights,或者使用 hard thresholding 对实验结果的影响,hard thresholding 仅保留35%的低频模式。AFNO 的结果是最优的。

总结
本文提出了一种借助傅里叶变换的高效 token mixer,AFNO。模型可以灵活地适应输入分辨率的变化,并且随着输入分辨率的增加呈 quasi-linear 增长。AFNO 通过对复数权重进行分块操作,一方面融合不同 channel 的信息,另一方面控制参数量的增长。通过 Soft-Thresholding and Shrinkage 来控制 token 的稀疏度,提升模型的泛化性能。最终在几个下游任务和 ImageNet 大规模图像识别任务里面得到了超越以往基于傅里叶变换的 token mixer 对应的方法。
公众号后台回复“小目标检测”获取小目标检测数据集下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选




