xYOLO | 最新最快的实时目标检测
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
随着物联网(IoT)、边缘计算和自主机器人等领域的车载视觉处理技术的出现,人们对复合高效卷积神经网络模型在资源受限的硬件设备上进行实时目标检测的需求越来越大。Tiny-YOLO通常被认为是低端设备中速度更快的对象探测器之一,这个也是今天作者工作的基础。

相关工作
传统上,在机器人杯类人机器人比赛中,基于颜色分割的技术被用来检测足球场的特征,如球门和球。这些技术是快速和可以实现良好的精度在简单的环境,例如使用橙色的球,控制室内照明和黄色的目标。然而,根据RoboCup 2050年的球门,球队已经看到了自然光照条件(暴露在阳光下)、白色背景的球门和各种颜色的国际足联球。基于颜色分割的技术在这些具有挑战性的场景中无法发挥作用,主要推动了实现多种神经网络方法的竞争。
基于CNN的模型在复杂场景中的目标检测精度方面取得了很大进展。然而,这些基于cnn的高性能计算机视觉系统,虽然比全连接的网络精简得多,但仍然具有相当大的内存和计算消耗,并且只有在高端GPU设备上才能实现实时性。因此,这些型号中的大多数不适合于低端设备,如智能手机或移动机器人。这就限制了它们在实时应用中的应用,比如自主的仿人机器人踢足球,因为有权力和重量方面的考虑。因此,开发轻量级、计算效率高的模型,使CNN能够使用更少的内存和最少的计算资源,是一个活跃的研究领域。

最近发表了大量关于适合于低端硬件设备的目标检测的轻量级深入学习模型的研究论文。这些模型大多基于SSD、SqueezeNet、AlexNet和GoogleNet。在这些模型中,目标检测流水线通常包含预处理、大量卷积层和后处理等几个部分。分类器在图像中的不同位置和多尺度上使用滑动窗口方法或区域候选方法进行评估。这些复杂的目标检测计算量大,因此速度慢。XNOR-Net使用二进制运算的近似卷积,与传统卷积中使用的浮点数相比计算效率高。XNOR网络的一个明显的缺点是类似大小的网络的准确性下降。
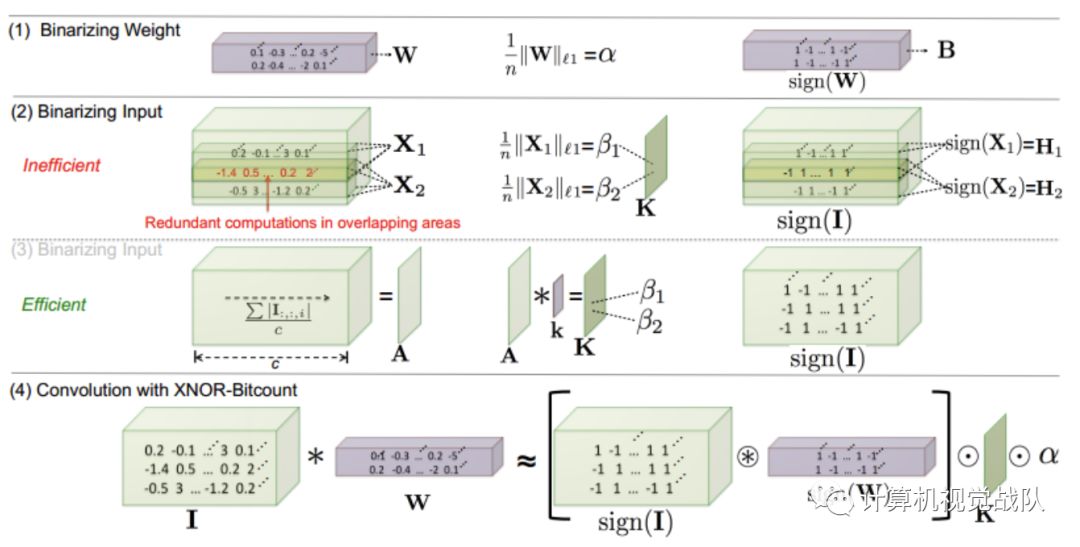
另一方面,在you only look once(YOLO),目标检测是一个单一的回归问题。YOLO工作在边界框级别,而不是像素级别,即YOLO同时预测边界框和相关的类概率,从整个图像中在一个“看”。YOLO的一个主要优点是它能够对上下文信息进行编码,因此在混淆目标图像中的背景时出错较少。
“Lighter”版本的YOLO v3,称为Tiny-YOLO,设计时考虑到了速度,并被普遍报道为表现较好的模型之一,在速度和准确性的权衡。Tiny-YOLO有九个卷积层和两个全连接层。实验表明,Tiny-YOLO能够在Raspberry PI 3上实现0.14 FPS,这与实时目标检测相差很远。
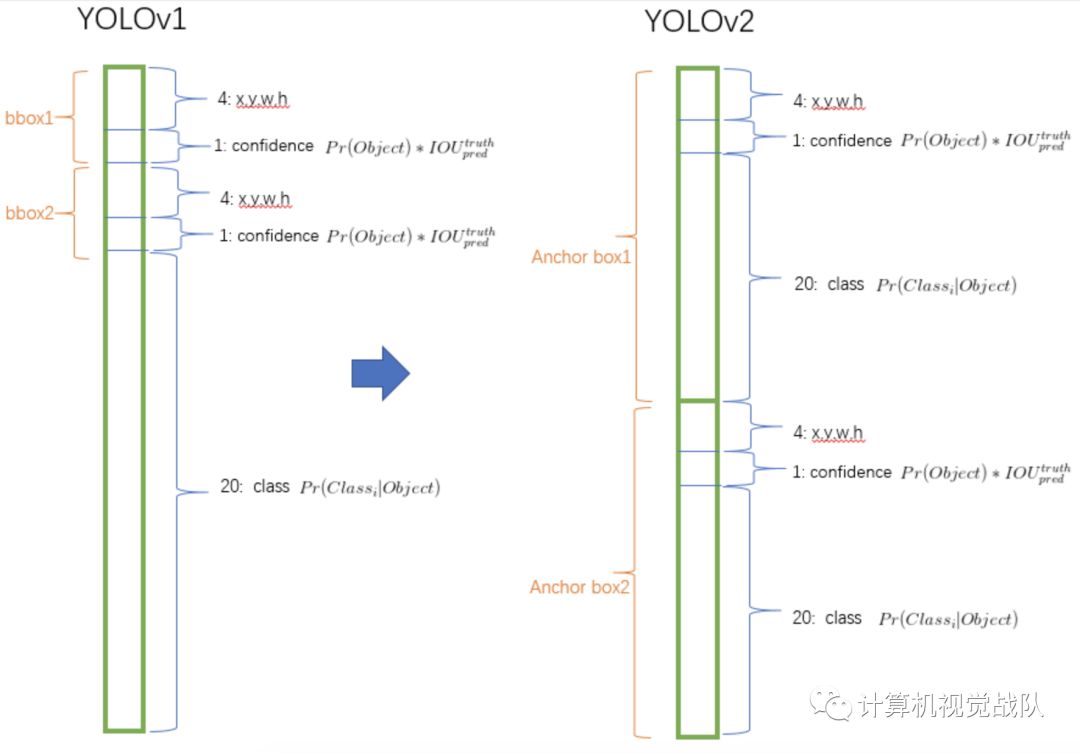
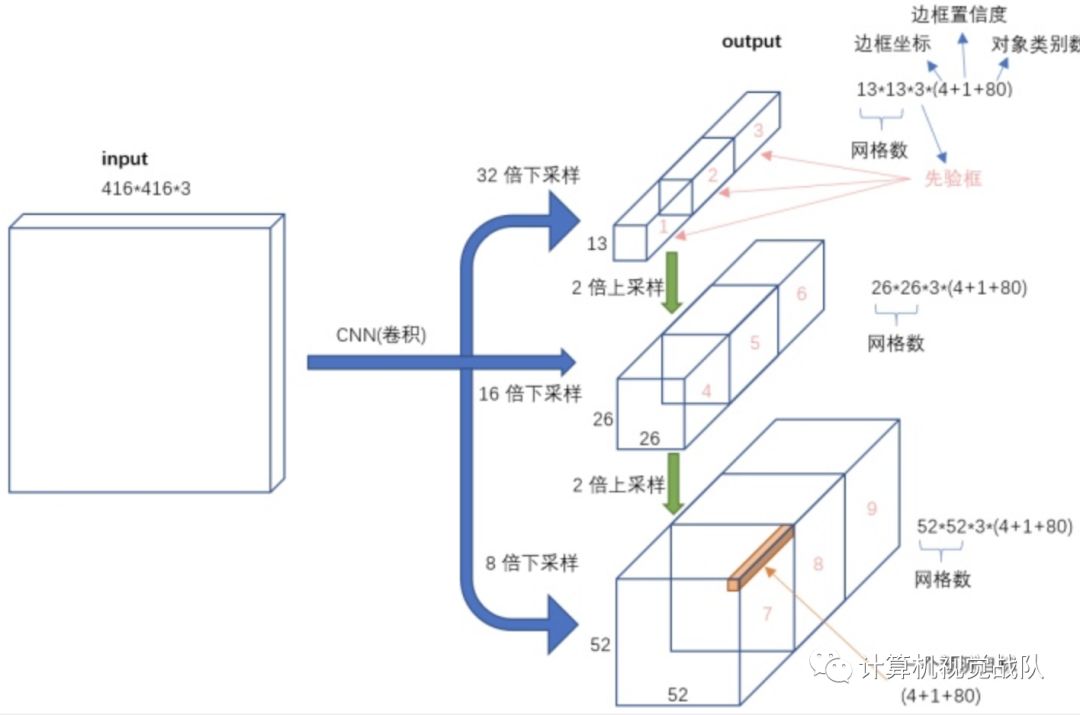
从有些文章中的结果可以看出,这些目标检测器不能在计算资源最少的低端硬件上提供实时性能(例如,以Raspberry PI作为计算资源的类人机器人)。在作者使用的机器人中,使用一个计算资源来处理几个不同的过程,例如行走引擎、自我定位等。视觉系统只剩下一个核心来执行所有的目标检测。
新的框架方法
作者提出的网络xYOLO是从YOLO v3 tiny派生而来的,具体而言,使用AlexeyAB的DarkNet,它允许XNOR层,并建立在下图所示的Raspberry PI的基础上,xYOLO在训练和recall中都使用了正常的卷积层和XNOR层。
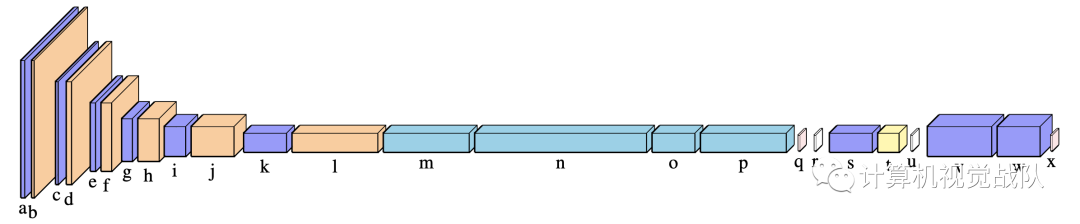


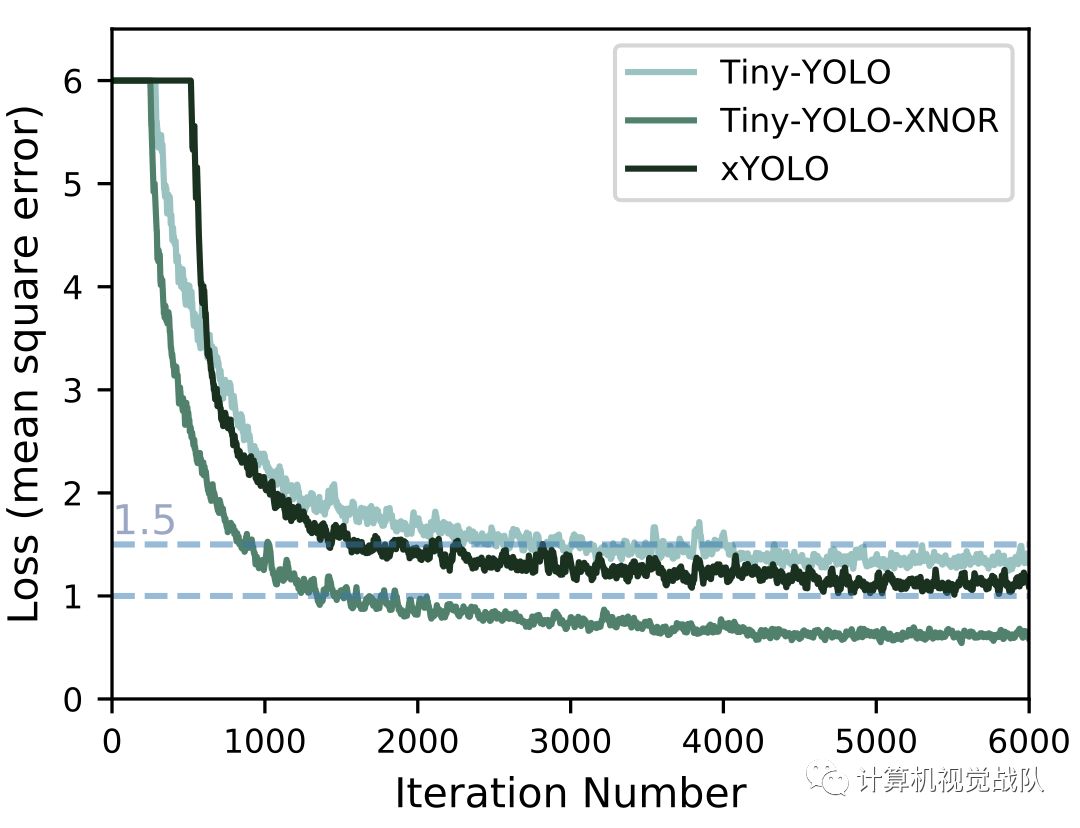
实验及结果
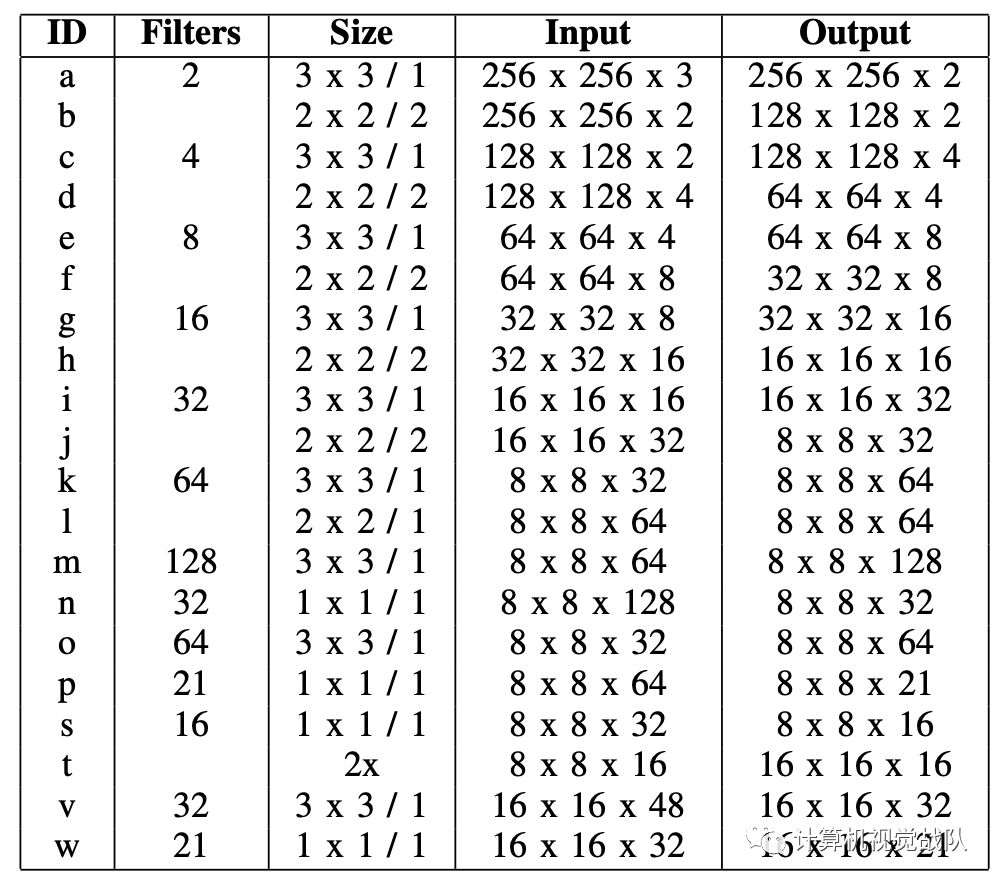
下面是xYOLO网络的结构:
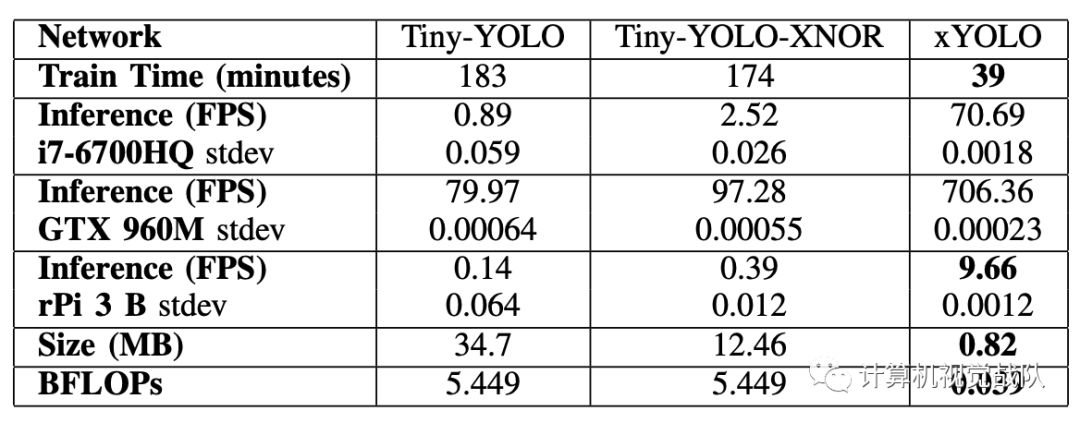
如下表所示,与其他测试模型相比,xYOLO在计算效率方面取得了更好的性能。

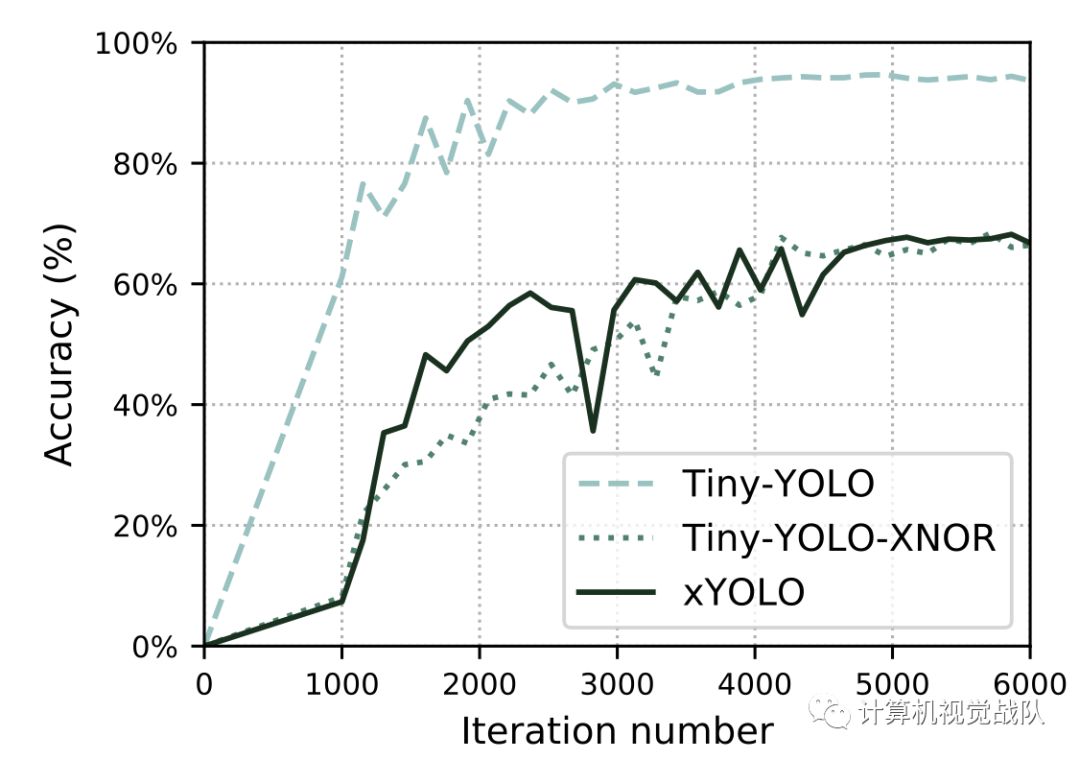
观察到上图,模型在训练和未见测试集上都取得了相似的精度。与其他模型相比,Tiny-YOLO实现了更好的目标检测精度。在验证数据集上,xYOLO能够达到约68%的准确率,在测试集上达到约67%,这在考虑到xYOLO的速度和大小时是很好的。


示例目标检测结果由模型产生。左侧:Tiny-YOLO,中间:xYOLO,右侧:Tiny-YOLO-XNOR。当每个网络识别达到检测阈值的对象时,球和球门被标记。可以观察到,xYOLO的目标检测结果优于Tiny-YOLO-XNOR,其结果与Tiny-YOLO具有可比性。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、检测分割识别、三维视觉、医学影像、GAN、自动驾驶、计算摄影、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life
推荐阅读
最新AI干货,我在看





