干货 | 大规模机器学习框架的四重境界
AI科技评论按,本文作者carbon zhang (https://www.zhihu.com/people/carbon-zhang),该文首发于知乎专栏分布式机器学习系统 (https://zhuanlan.zhihu.com/c_127078572),AI科技评论获其授权转载。
1.背景
自从google发表著名的GFS、MapReduce、BigTable三篇paper以后,互联网正式迎来了大数据时代。大数据的显著特点是大,哪里都大的大。本篇主要针对volume大的数据时,使用机器学习来进行数据处理过程中遇到的架构方面的问题做一个系统的梳理。
有了GFS我们有能力积累海量的数据样本,比如在线广告的曝光和点击数据,天然具有正负样本的特性,累积一两个月往往就能轻松获得百亿、千亿级的训练样本。这样海量的样本如何存储?用什么样的模型可以学习海量样本中有用的pattern?这些问题不止是工程问题,也值得每个做算法的同学去深入思考。
1.1 简单模型or复杂模型
在深度学习概念提出之前,算法工程师手头能用的工具其实并不多,就LR、SVM、感知机等寥寥可数、相对固定的若干个模型和算法;那时候要解决一个实际的问题,算法工程师更多的工作主要是在特征工程方面。而特征工程本身并没有很系统化的指导理论(至少目前没有看到系统介绍特征工程的书籍),所以很多时候特征的构造技法显得光怪陆离,是否有用也取决于问题本身、数据样本、模型以及运气。
在特征工程作为算法工程师主要工作内容的时候,构造新特征的尝试往往很大部分都不能在实际工作中work。据我了解,国内几家大公司在特征构造方面的成功率在后期一般不会超过20%。也就是80%的新构造特征往往并没什么正向提升效果。如果给这种方式起一个名字的话,大概是简单模型+复杂特征;简单模型说的是算法比如LR、SVM本身并不服务,参数和表达能力基本呈现一种线性关系,易于理解。复杂特征则是指特征工程方面不断尝试使用各种奇技淫巧构造的可能有用、可能没用的特征,这部分特征的构造方式可能会有各种trick,比如窗口滑动、离散化、归一化、开方、平方、笛卡尔积、多重笛卡尔积等等;顺便提一句,因为特征工程本身并没有特别系统的理论和总结,所以初入行的同学想要构造特征就需要多读paper,特别是和自己业务场景一样或类似的场景的paper,从里面学习作者分析、理解数据的方法以及对应的构造特征的技法;久而久之,有望形成自己的知识体系。
深度学习概念提出以后,人们发现通过深度神经网络可以进行一定程度的表示学习(representation learning),例如在图像领域,通过CNN提取图像feature并在此基础上进行分类的方法,一举打破了之前算法的天花板,而且是以极大的差距打破。这给所有算法工程师带来了新的思路,既然深度学习本身有提取特征的能力,干嘛还要苦哈哈的自己去做人工特征设计呢?
深度学习虽然一定程度上缓解了特征工程的压力,但这里要强调两点:1.缓解并不等于彻底解决,除了图像这种特定领域,在个性化推荐等领域,深度学习目前还没有完全取得绝对的优势;究其原因,可能还是数据自身内在结构的问题,使得在其他领域目前还没有发现类似图像+CNN这样的完美CP。2.深度学习在缓解特征工程的同时,也带来了模型复杂、不可解释的问题。算法工程师在网络结构设计方面一样要花很多心思来提升效果。概括起来,深度学习代表的简单特征+复杂模型是解决实际问题的另一种方式。
两种模式孰优孰劣还难有定论,以点击率预测为例,在计算广告领域往往以海量特征+LR为主流,根据VC维理论,LR的表达能力和特征个数成正比,因此海量的feature也完全可以使LR拥有足够的描述能力。而在个性化推荐领域,深度学习刚刚萌芽,目前google play采用了WDL的结构[1],youtube采用了双重DNN的结构[2]。
不管是那种模式,当模型足够庞大的时候,都会出现模型参数一台机器无法存放的情况。比如百亿级feature的LR对应的权重w有好几十个G,这在很多单机上存储都是困难的,大规模神经网络则更复杂,不仅难以单机存储,而且参数和参数之间还有逻辑上的强依赖;要对超大规模的模型进行训练势必要借用分布式系统的技法,本文主要是系统总结这方面的一些思路。
1.2 数据并行vs模型并行
数据并行和模型并行是理解大规模机器学习框架的基础概念,其缘起未深究,第一次看到是在姐夫(Jeff Dean)的blog里,当时匆匆一瞥,以为自己懂了。多年以后,再次开始调研这个问题的时候才想起长者的教训,年轻人啊,还是图样,图森破。如果你和我一样曾经忽略过这个概念,今天不放复习一下。
这两个概念在[3]中沐帅曾经给出了一个非常直观而经典的解释,可惜不知道什么原因,当我想引用时却发现已经被删除了。我在这里简单介绍下这个比喻:如果要修两栋楼,有一个工程队,怎么操作?第一个方案是将人分成两组,分别盖楼,改好了就装修;第二种做法是一组人盖楼,等第一栋楼盖好,另一组装修第一栋,然后第一组继续盖第二栋楼,改完以后等装修队装修第二栋楼。咋一看,第二种方法似乎并行度并不高,但第一种方案需要每个工程人员都拥有“盖楼”和“装修”两种能力,而第二个方案只需要每个人拥有其中一种能力即可。第一个方案和数据并行类似,第二个方案则道出了模型并行的精髓。
数据并行理解起来比较简单,当样本比较多的时候,为了使用所有样本来训练模型,我们不妨把数据分布到不同的机器上,然后每台机器都来对模型参数进行迭代,如下图所示
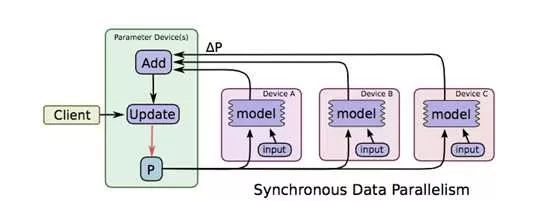
图片取材于TensorFlow的paper[4],图中ABC代表三台不同的机器,上面存储着不同的样本,模型P在各台机器上计算对应的增量,然后在参数存储的机器上进行汇总和更新,这就是数据并行。先忽略synchronous,这是同步机制相关的概念,在第三节会有专门介绍。
数据并行概念简单,而且不依赖于具体的模型,因此数据并行机制可以作为框架的一种基础功能,对所有算法都生效。与之不同的是,模型并行因为参数间存在依赖关系(其实数据并行参数更新也可能会依赖所有的参数,但区别在于往往是依赖于上一个迭代的全量参数。而模型并行往往是同一个迭代内的参数之间有强依赖关系,比如DNN网络的不同层之间的参数依照BP算法形成的先后依赖),无法类比数据并行这样直接将模型参数分片而破坏其依赖关系,所以模型并行不仅要对模型分片,同时需要调度器来控制参数间的依赖关系。而每个模型的依赖关系往往并不同,所以模型并行的调度器因模型而异,较难做到完全通用。关于这个问题,CMU的Erix Xing在[5]中有所介绍,感兴趣的可以参考。
模型并行的问题定义可以参考姐夫的[6],这篇paper也是tensorflow的前身相关的总结,其中图
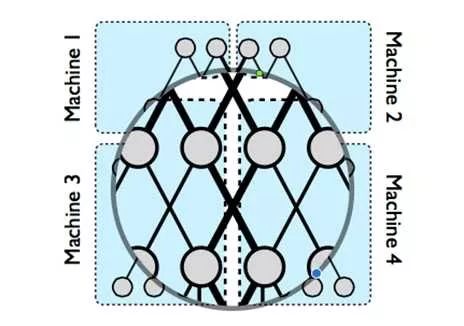
解释了模型并行的物理图景,当一个超大神经网络无法存储在一台机器上时,我们可以切割网络存到不同的机器上,但是为了保持不同参数分片之间的依赖,如图中粗黑线的部分,则需要在不同的机器之间进行concurrent控制;同一个机器内部的参数依赖,即途中细黑线部分在机器内即可完成控制。
黑线部分如何有效控制呢?如下图所示
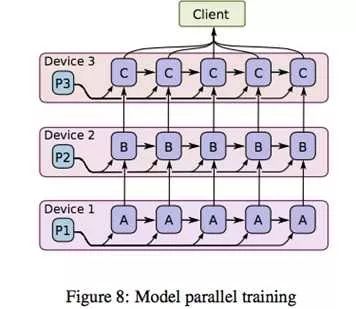
在将模型切分到不同机器以后,我们将参数和样本一起在不同机器间流转,图中ABC代表模型的不同部分的参数;假设C依赖B,B依赖A,机器1上得到A的一个迭代后,将A和必要的样本信息一起传到机器2,机器2根据A和样本对P2更新得到,以此类推;当机器2计算B的时候,机器1可以展开A的第二个迭代的计算。了解CPU流水线操作的同学一定感到熟悉,是的,模型并行是通过数据流水线来实现并行的。想想那个盖楼的第二种方案,就能理解模型并行的精髓了。
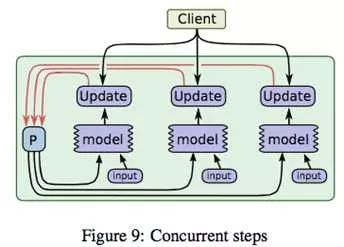
上图则是对控制模型参数依赖的调度器的一个示意图,实际框架中一般都会用DAG(有向无环图)调度技术来实现类似功能,未深入研究,以后有机会再补充说明。
理解了数据并行和模型并行对后面参数服务器的理解至关重要,但现在让我先荡开一笔,简单介绍下并行计算框架的一些背景信息。
2. 并行算法演进
2.1 MapReduce路线
从函数式编程中的受到启发,google发布了MapReduce[7]的分布式计算方式;通过将任务切分成多个叠加的Map+Reduce任务,来完成复杂的计算任务,示意图如下
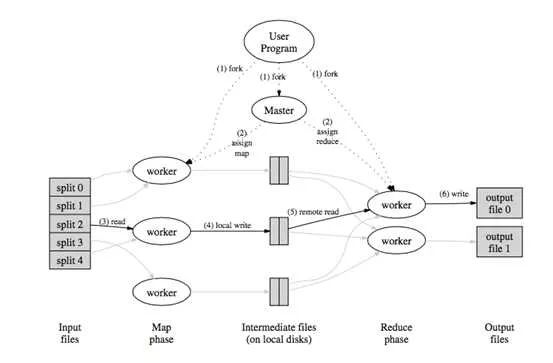
MapReduce的主要问题有两个,一是原语的语义过于低级,直接使用其来写复杂算法,开发量比较大;另一个问题是依赖于磁盘进行数据传递,性能跟不上业务需求。
为了解决MapReduce的两个问题,Matei在[8]中提出了一种新的数据结构RDD,并构建了Spark框架。Spark框架在MR语义之上封装了DAG调度器,极大降低了算法使用的门槛。较长时间内spark几乎可以说是大规模机器学习的代表,直至后来沐帅的参数服务器进一步开拓了大规模机器学习的领域以后,spark才暴露出一点点不足。如下图
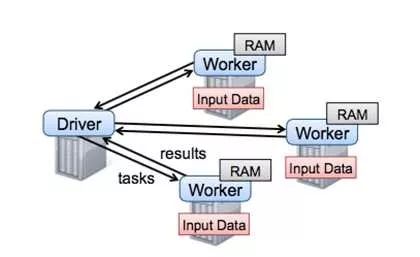
从图中可以看出,spark框架以Driver为核心,任务调度和参数汇总都在driver,而driver是单机结构,所以spark的瓶颈非常明显,就在Driver这里。当模型规模大到一台机器存不下的时候,Spark就无法正常运行了。所以从今天的眼光来看,Spark只能称为一个中等规模的机器学习框架。剧透一句,公司开源的Angel通过修改Driver的底层协议将Spark扩展到了一个高一层的境界。后面还会再详细介绍这部分。
MapReduce不仅是一个框架,还是一种思想,google开创性的工作为我们找到了大数据分析的一个可行方向,时至今日,仍不过时。只是逐渐从业务层下沉到底层语义应该处于的框架下层。
2.2 MPI技术
沐帅在[9]中对MPI的前景做了简要介绍;和Spark不同,MPI是类似socket的一种系统通信API,只是支持了消息广播等功能。因为对MPI研究不深入,这里简单介绍下优点和缺点吧;优点是系统级支持,性能杠杠的;缺点也比较多,一是和MR一样因为原语过于低级,用MPI写算法,往往代码量比较大。另一方面是基于MPI的集群,如果某个任务失败,往往需要重启整个集群,而MPI集群的任务成功率并不高。阿里在[10]中给出了下图:
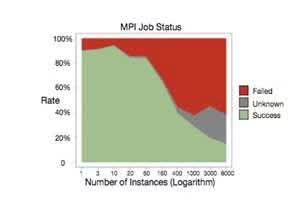
从图中可以看出,MPI作业失败的几率接近五成。MPI也并不是完全没有可取之处,正如沐帅所说,在超算集群上还是有场景的。对于工业届依赖于云计算、依赖于commodity计算机来说,则显得性价比不够高。当然如果在参数服务器的框架下,对单组worker再使用MPI未尝不是个好的尝试,[10]的鲲鹏系统正式这么设计的。
3. 参数服务器演进
3.1 历史演进
沐帅在[12]中将参数服务器的历史划分为三个阶段,第一代参数服务器萌芽于沐帅的导师Smola的[11],如下图所示:
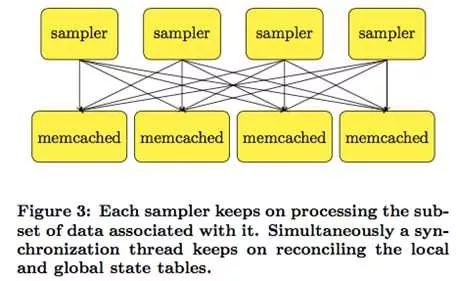
这个工作中仅仅引入memcached来存放key-value数据,不同的处理进程并行对其进行处理。[13]中也有类似的想法,第二代参数服务器叫application-specific参数服务器,主要针对特定应用而开发,其中最典型的代表应该是tensorflow的前身[6]。
第三代参数服务器,也即是通用参数服务器框架是由百度少帅李沐正式提出的,和前两代不同,第三代参数服务器从设计上就是作为一个通用大规模机器学习框架来定位的。要摆脱具体应用、算法的束缚,做一个通用的大规模机器学习框架,首先就要定义好框架的功能;而所谓框架,往往就是把大量重复的、琐碎的、做了一次就不想再来第二次的脏活、累活进行良好而优雅的封装,让使用框架的人可以只关注与自己的核心逻辑。第三代参数服务器要对那些功能进行封装呢?沐帅总结了这几点,我照搬如下:
1)高效的网络通信:因为不管是模型还是样本都十分巨大,因此对网络通信的高效支持以及高配的网络设备都是大规模机器学习系统不可缺少的;
2)灵活的一致性模型:不同的一致性模型其实是在模型收敛速度和集群计算量之间做tradeoff;要理解这个概念需要对模型性能的评价做些分析,暂且留到下节再介绍。
3)弹性可扩展:显而易见
4)容灾容错:大规模集群协作进行计算任务的时候,出现Straggler或者机器故障是非常常见的事,因此系统设计本身就要考虑到应对;没有故障的时候,也可能因为对任务时效性要求的变化而随时更改集群的机器配置。这也需要框架能在不影响任务的情况下能做到机器的热插拔。
5)易用性:主要针对使用框架进行算法调优的工程师而言,显然,一个难用的框架是没有生命力的。
在正式介绍第三代参数服务器的主要技术之前,先从另一个角度来看下大规模机器学习框架的演进
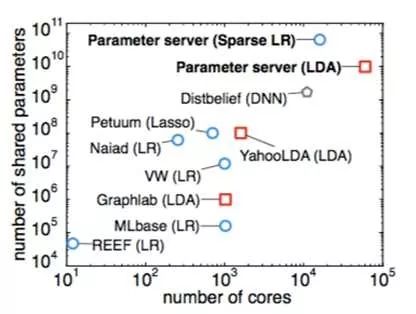
这张图可以看出,在参数服务器出来之前,人们已经做了多方面的并行尝试,不过往往只是针对某个特定算法或特定领域,比如YahooLDA是针对LDA算法的。当模型参数突破十亿以后,则可以看出参数服务器一统江湖,再无敌手。
首先我们看看第三代参数服务器的基本架构
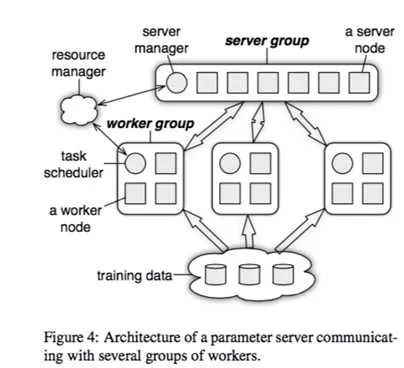
上图的resource manager可以先放一放,因为实际系统中这部分往往是复用现有的资源管理系统,比如yarn或者mesos;底下的training data毋庸置疑的需要类似GFS的分布式文件系统的支持;剩下的部分就是参数服务器的核心组件了。
图中画了一个server group和三个worker group;实际应用中往往也是类似,server group用一个,而worker group按需配置;server manager是server group中的管理节点,一般不会有什么逻辑,只有当有server node加入或退出的时候,为了维持一致性哈希而做一些调整。
Worker group中的task schedule则是一个简单的任务协调器,一个具体任务运行的时候,task schedule负责通知每个worker加载自己对应的数据,然后去server node上拉取一个要更新的参数分片,用本地数据样本计算参数分片对应的变化量,然后同步给server node;server node在收到本机负责的参数分片对应的所有worker的更新后,对参数分片做一次update。
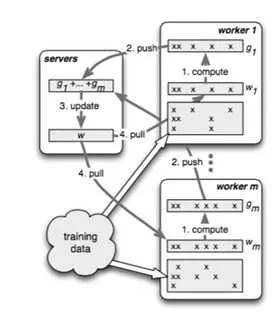
如图所示,不同的worker同时并行运算的时候,可能因为网络、机器配置等外界原因,导致不同的worker的进度是不一样的,如何控制worker的同步机制是一个比较重要的课题。详见下节分解。
3.2 同步协议
本节假设读者已经对随机梯度优化算法比较熟悉,如果不熟悉的同学请参考吴恩达经典课程机器学习中对SGD的介绍,或者我之前多次推荐过的书籍《最优化导论》。
我们先看一个单机算法的运行过程,假设一个模型的参数切分成三个分片k1,k2,k3;比如你可以假设是一个逻辑回归算法的权重向量被分成三段。我们将训练样本集合也切分成三个分片s1,s2,s3;在单机运行的情况下,我们假设运行的序列是(k1,s1)、(k2,s1)、(k3、s1)、(k1、s2)、(k2、s2)、(k3、s2)。。。看明白了吗?就是假设先用s1中的样本一次对参数分片k1、k2、k3进行训练,然后换s2;这就是典型的单机运行的情况,而我们知道这样的运行序列最后算法会收敛。
现在我们开始并行化,假设k1、k2、k3分布在三个server node上,s1、s2、s3分布在三个worker上,这时候如果我们还要保持之前的计算顺序,则会变成怎样?work1计算的时候,work2和worker3只能等待,同样worker2计算的时候,worker1和work3都得等待,以此类推;可以看出这样的并行化并没有提升性能;但是也算简单解决了超大规模模型的存储问题。
为了解决性能的问题,业界开始探索这里的一致性模型,最先出来的版本是前面提到的[11]中的ASP模式,就是完全不顾worker之间的顺序,每个worker按照自己的节奏走,跑完一个迭代就update,然后继续,这应该是大规模机器学习中的freestyle了,如图所示
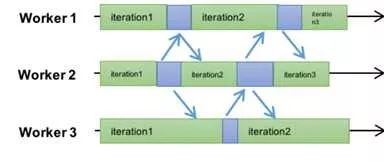
ASP的优势是最大限度利用了集群的计算能力,所有的worker所在的机器都不用等待,但缺点也显而易见,除了少数几个模型,比如LDA,ASP协议可能导致模型无法收敛。也就是SGD彻底跑飞了,梯度不知道飞到哪里去了。
在ASP之后提出了另一种相对极端的同步协议BSP,spark用的就是这种方式,如图所示
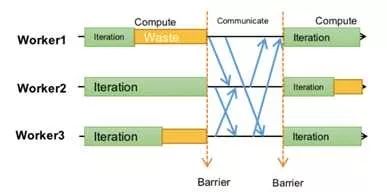
每个worker都必须在同一个迭代运行,只有一个迭代任务所有的worker都完成了,才会进行一次worker和server之间的同步和分片更新。这个算法和严格一直的算法非常类似,区别仅仅在于单机版本的batch size在BSP的时候变成了有所有worker的单个batch size求和得到的总的butch size替换。毫无疑问,BSP的模式和单机串行因为仅仅是batch size的区别,所以在模型收敛性上是完全一样的。同时,因为每个worker在一个周期内是可以并行计算的,所以有了一定的并行能力。
以此协议为基础的spark在很长时间内成为机器学习领域实际的霸主,不是没有理由的。此种协议的缺陷之处在于,整个worker group的性能由其中最慢的worker决定;这个worker一般称为straggler。读过GFS文章的同学应该都知道straggler的存在是非常普遍的现象。
能否将ASP和BSP做一下折中呢?答案当然是可以的,这就是目前我认为最好的同步协议SSP;SSP的思路其实很简单,既然ASP是允许不同worker之间的迭代次数间隔任意大,而BSP则只允许为0,那我是否可以取一个常数s?如图所示
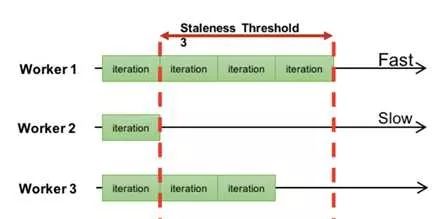
不同的worker之间允许有迭代的间隔,但这个间隔数不允许超出一个指定的数值s,图中s=3.
SSP协议的详细介绍参见[14],CMU的大拿Eric Xing在其中详细介绍了SSP的定义,以及其收敛性的保证。理论推导证明常数s不等于无穷大的情况下,算法一定可以在若干次迭代以后进入收敛状态。其实在Eric提出理论证明之前,工业界已经这么尝试过了:)
顺便提一句,考察分布式算法的性能,一般会分为statistical performance和hard performance来看。前者指不同的同步协议导致算法收敛需要的迭代次数的多少,后者是单次迭代所对应的耗时。两者的关系和precision\recall关系类似,就不赘述了。有了SSP,BSP就可以通过指定s=0而得到。而ASP同样可以通过制定s=∞来达到。
3.3 核心技术
除了参数服务器的架构、同步协议之外,本节再对其他技术做一个简要的介绍,详细的了解请直接阅读沐帅的博士论文和相关发表的论文。
热备、冷备技术:为了防止server node挂掉,导致任务中断,可以采用两个技术,一个是对参数分片进行热备,每个分片存储在三个不同的server node中,以master-slave的形式存活。如果master挂掉,可以快速从slave获取并重启相关task。
除了热备,还可以定时写入checkpoint文件到分布式文件系统来对参数分片及其状态进行备份。进一步保证其安全性。
Server node管理:可以使用一致性哈希技术来解决server node的加入和退出问题,如图所示
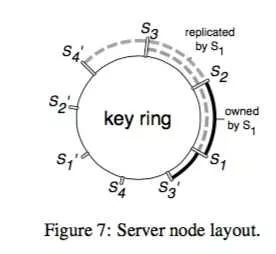
当有server node加入或退出的时候,server manager负责对参数进行重新分片或者合并。注意在对参数进行分片管理的情况下,一个分片只需要一把锁,这大大提升了系统的性能,也是参数服务器可以实用的一个关键点。
4. 大规模机器学习的四重境界
到这里可以回到我们的标题了,大规模机器学习的四重境界到底是什么呢?
这四重境界的划分是作者个人阅读总结的一种想法,并不是业界标准,仅供大家参考。
境界1:参数可单机存储和更新
此种境界较为简单,但仍可以使用参数服务器,通过数据并行来加速模型的训练。
境界2:参数不可单机存储,可以单机更新
此种情况对应的是一些简单模型,比如sparse logistic regression;当feature的数量突破百亿的时候,LR的权重参数不太可能在一台机器上完全存下,此时必须使用参数服务器架构对模型参数进行分片。但是注意一点,SGD的更新公式
w’=w-α,其中可以分开到单个维度进行计算,但是单个维度的wi=f(w)xi
这里的f(w)表示是全部参数w的一个函数,具体推倒比较简单,这里篇幅所限就不赘述了。只是想说明worker在计算梯度的时候可能需要使用到上一轮迭代的所有参数。而我们之所以对参数进行分片就是因为我们无法将所有参数存放到一台机器,现在单个worker有需要使用所有的参数才能计算某个参数分片的梯度,这不是矛盾吗?可能吗?
答案是可能的,因为单个样本的feature具有很高的稀疏性(sparseness)。例如一个百亿feature的模型,单个训练样本往往只在其中很小一部分feature上有取值,其他都为0(假设feature取值都已经离散化了)。因此计算f(w)的时候可以只拉取不为0的feature对应的那部分w即可。有文章统计一般这个级别的系统,稀疏性往往在0.1%(or 0.01%,记得不是很准,大致这样)以下。这样的稀疏性,可以让单机没有任何阻碍的计算f(w)。
目前公司开源的angel和AILab正在做的系统都处于这个境界。而原生spark还没有达到这个境界,只能在中小规模的圈子里厮混。Angel改造的基于Angel的Spark则达到了这个境界。
境界3:参数不可单机存储,不可单机更新,但无需模型并行
境界3顺延境界2二来,当百亿级feature且feature比较稠密的时候,就需要计算框架进入到这层境界了,此时单个worker的能力有限,无法完整加载一个样本,也无法完整计算f(w)。怎么办呢?其实很简单,学过线性代数的都知道,矩阵可以分块。向量是最简单的矩阵,自然可以切成一段一段的来计算。只是调度器需要支持算符分段而已了。
境界4:参数不可单机存储,不可单机更新,需要模型并行
进入到这个层次的计算框架,可以算是世界一流了。可以处理超大规模的神经网络。这也是最典型的应用场景。此时不仅模型的参数不能单机存储,而且同一个迭代内,模型参数之间还有强的依赖关系,可以参见姐夫对distbelief的介绍里的模型切分。
此时首先需要增加一个coordinator组件来进行模型并行的concurrent控制。同时参数服务器框架需要支持namespace切分,coordinator将依赖关系通过namespace来进行表示。
一般参数间的依赖关系因模型而已,所以较难抽象出通用的coordinator来,而必须以某种形式通过脚本parser来生产整个计算任务的DAG图,然后通过DAG调度器来完成。对这个问题的介绍可以参考Erix Xing的分享[5]。
Tensorflow
目前业界比较知名的深度学习框架有Caffee、MXNet、Torch、Keras、Theano等,但目前最炙手可热的应该是google发布的Tensorflow。这里单独拿出来稍微分解下。
前面不少图片引自此文,从TF的论文来看,TF框架本身是支持模型并行和数据并行的,内置了一个参数服务器模块,但从开源版本所曝光的API来看,TF无法用来10B级别feature的稀疏LR模型。原因是已经曝光的API只支持在神经网络的不同层和层间进行参数切分,而超大规模LR可以看做一个神经单元,TF不支持单个神经单元参数切分到多个参数服务器node上。
当然,以google的实力,绝对是可以做到第四重境界的,之所以没有曝光,可能是基于其他商业目的的考量,比如使用他们的云计算服务。
综上,个人认为如果能做到第四重境界,目前可以说的上是世界一流的大规模机器学习框架。仅从沐帅的ppt里看他曾经达到过,google内部应该也是没有问题的。第三重境界应该是国内一流,第二充应该是国内前列吧。
5. 其他
5.1 资源管理
本文没有涉及到的部分是资源管理,大规模机器学习框架部署的集群往往资源消耗也比较大,需要专门的资源管理工具来维护。这方面yarn和mesos都是佼佼者,细节这里也就不介绍了。
5.2 设备
除了资源管理工具,本身部署大规模机器学习集群本身对硬件也还是有些要求的,虽然理论上来说,所有commodity机器都可以用来搭建这类集群,但是考虑到性能,我们建议尽量用高内存的机器+万兆及以上的网卡。没有超快速的网卡,玩参数传递和样本加载估计会比较苦逼。
6. 结语
从后台转算法以来,长期沉浸于算法推理的论文无法自拔,对自己之前的后台工程能力渐渐轻视起来,觉得工程对算法的帮助不大。直到最近一个契机,需要做一个这方面的调研,才豁然发现,之前的工程经验对我理解大规模机器学习框架非常有用,果然如李宗盛所说,人生每一步路,都不是白走的。
在一个月左右的调研中,脑子每天都充斥这各种疑问和困惑,曾经半夜4点醒来,思考同步机制而再也睡不着,干脆起来躲卫生间看书,而那天我一点多才睡。当脑子里有放不下的问题的时候,整个人会处于一种非常亢奋的状态,除非彻底想清楚这个问题,否则失眠是必然的,上一次这种状态已经是很多年前了。好在最后我总算理清了这方面的所有关键细节。以此,记之。Carbon zhang于2017年8月26日凌晨!
致谢
感谢wills、janwang、joey、roberty、suzi等同学一起讨论,特别感谢burness在TF方面的深厚造诣和调研。因为本人水平所限,错漏难免,另外还有相当多的细节因为篇幅限制并未一一展开,仅仅是从较高抽象层面上简述了下大规模机器学习框架的关键思路,其他如分片向量锁、通信协议、时钟逻辑、DAG调度器、资源调度模块等均为展开来讲,希望以后有机会能补上。
引用
1. Wide& Deep Learning for Recommender Systems
2. Deep Neural Networks for YouTube Recommendations
3. https://www.zhihu.com/question/53851014
4. TensorFlow:Large-Scale Machine Learning on Heterogeneous Distributed Systems
5. http://www.jianshu.com/p/00736aa21dc8
6. Large Scale Distributed Deep Networks
7. MapReduce: Simplified Data Processing on Large
Clusters
8. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
9. https://www.zhihu.com/question/55119470
10. KunPeng:Parameter Server based Distributed Learning Systems and Its Applications in
Alibaba and Ant Financial
11. An Architecture for Parallel Topic Models
12. Scaling Distributed Machine Learning with the Parameter Server
13. Piccolo:Building fast, distributed pro- grams with partitioned tables
14. More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server
15. Angel-A Flexible and Powerful Parameter Server;黄明ppt
————— AI 科技评论招人啦! —————
我们诚招学术编辑 1 名(全职,坐标北京)、新媒体运营 1 名(全职,坐标北京),详情请阅读今日微信末条。
欢迎发送简历到 guoyixin@leiphone.com
————— 给爱学习的你的福利 —————
不要等到算法出现accuracy不好、loss很高、模型overfitting时,
才后悔没有掌握基础数学理论!
线性代数及矩阵论, 概率论与统计, 凸优化
AI慕课学院机器学习之数学基础课程即将上线!
扫码进入课程咨询群,组队享团购优惠!
详细了解点击文末阅读原文

————————————————————