用AI让经典重新跳动,这个平台开放了3000万古籍字符
机器之心原创
一百多年后,我们仍在为胡适提出的「整理国故,再造文明」而努力,但技术的发展让我们能够以一种新的形式完成这项历史使命。
1919 年 12 月,胡适在《新青年》杂志发表《新思潮的意义》一文,提出建设新文化的理论原则:「研究问题、输入学理、整理国故、再造文明。」由此在学术界引起了一场规模较大的「整理国故运动」。
在他看来,中国的古籍,实在是缺乏系统性。这就导致「一般青年,对于中国本来的文化和学术,都缺乏研究的兴趣」。所以,他希望大家都能「下一番真实的工夫,使彼成为有系统的…… 方能使人有研究的兴趣,并能使有研究兴趣的人容易去研究。」这场「整理国故运动」对于史料的保存与挖掘、中西方文化的连接与融合都起到了非常积极的作用。
经过一百多年陆陆续续的整理,我们的古籍已经具备了一定的系统性,也有越来越多的青年对它们产生了浓厚的兴趣,并从中汲取灵感和养料进行艺术创作。但新的问题开始涌现:古籍被整理好后就放入了图书馆、博物馆妥善保存,普通人想看一眼并不容易。如何让「有研究兴趣的人容易去研究」、让文明触手可及成为了新时代「整理国故」的新命题。
近日,由字节跳动和北京大学数字人文实验室、国家图书馆联合推出的古籍数字化阅读平台「识典古籍」的上线为这个新命题提供了一种解法。
平台链接:https://www.shidianguji.com/
「识典古籍」目前涵盖了 390 部经典古籍(主要来自《四部丛刊》),共计 3000 多万字。与之前访问门槛比较高的一些数字化平台不同,「识典古籍」是完全免费的,而且增加了简繁转换、原本影像对照、全文检索、注疏辅助等一系列便捷功能,人名、地名、书籍、时间、官职等信息都标注了出来,还添加了标点符号,真正做到了让普通人也能走近古籍,深入了解其中的文化内涵。

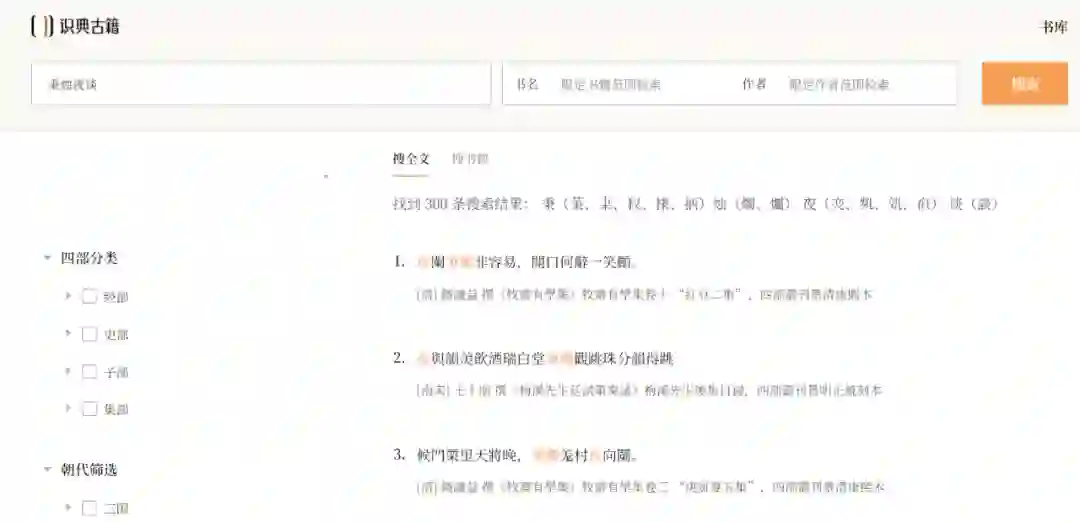
「识典古籍」支持多种检索方式,比如按古籍类别(经、史、子、集)检索以及按关键词、书名、作者检索等。

「识典古籍」的注疏展示和原本影像对照功能展示。
在「识典古籍」之前,我们也能找到一些类似的数字化古籍平台,比如中国哲学书电子化计划(Chinese Text Project)、书同文古籍数据库等。这些平台有着各自的优势,但也有不同局限。书同文古籍数据库收费较高,普通读者无法随时随地进查阅和使用。中国哲学书电子化计划目前囊括了超过三万部著作,但未能解决一个基本问题——用户常常无法访问。相比之下,「识典古籍」访问起来要便利得多。
这类数字化平台的出现不仅是丰富大众文化生活的需要,也是解决当前古籍保护、传承困境的有效方法。
而且,「识典古籍」项目负责人对媒体解释说,「识典古籍」不只是一个数字化平台,还是一个针对古籍保护的完整项目,包括古籍修复、数字化、活化三大方向。该项目融合了字节跳动积累的文字识别、自动标点、命名实体识别等多项 AI 技术以及来自北京大学等各大高校的学者和文献专家的丰富经验,将为古籍的保护和传承贡献重要的力量。
古籍保护、传承面临的困境
「史在他邦,文归海外」
今年 10 月 3 日,中国人物画史上最杰出的画作之一——《女史箴图》绢本在大英博物馆迎来一年一度的开放展出季。此画是现存已知的最早的中国画长卷之一,笔法如春蚕吐丝,形神兼备。可惜的是,国人要想欣赏这幅画作,也只能远赴伦敦。

《女史箴图》代表了很多中国古籍面临的困境。它们在战争时期被人掠夺或走私到海外,流失、散佚在各国博物馆、图书馆、私人收藏家手中。因此,原文化部副部长兼文物局局长郑振铎曾写下慨叹:「史在他邦,文归海外」。
1949 年前,郑振铎、张元济等学者曾以个人之力收购古籍。1949 年之后,国家对于流失海外的中华古籍的回归一直非常重视,通过政府收购、专项调查等方式促使古籍以各种形式回归祖国。海外华人也基于爱国之情不断将获得的古籍捐赠给祖国。但比起数量巨大的流失古籍,能够顺利回归的古籍原件还是非常之少,普通国人更是没有近距离接触这些流失古籍的渠道。
在这种情况下,古籍的数字化回归是一种更为实际的解决方案。
修复难,数字化也难
我国古籍数量众多,但真正能在网上查阅的数量却很少。造成这种现象的原因是多方面的。
首先,我国古籍现存几十万种,但经过兵燹水火的损毁,只有一部分是保存完好的,其他很多都需要先修复、再数字化。

古籍修复工作之一——碎片连缀。图源:《穿越时空的古籍》
其次,当前的古籍修复、数字化还面临工作效率低、人手短缺等困境。
效率方面,普通古籍修复、整理团队所能调动的资源往往比较有限,一个团队可能只有两台扫描仪,工作效率很难提升。
人才方面,很多人相信「一万小时定律」,但在古籍修复领域,「一万个小时恐怕出不来一个熟手,两万个小时未必能造就一个大师,而且他(她)本人还要努力,」国家图书馆副馆长、国家古籍保护中心副主任张志清感慨说。据统计,全国各高校、社会层面做古典文献专业的人加起来不到 1 万人。
如果以这样的速度、条件修复、整理下去,北京大学数字人文研究中心主任王军算过一笔账:我国现存古籍约有 20 万种,从 1949 年到 2019 年,共修复整理出版了近 38000 种,要将现存古籍全部修复整理出来,可能需要三百年的时间。
可见,古籍的数字化需要一场生产效率的变革。
人工智能让古籍焕发新生
近几年,国内科技企业正越来越多地参与到古籍的数字化工作中来。比如在 2021 年,阿里巴巴的「汉典重光」平台帮助一批珍藏于美国加州大学伯克利分校的中文古籍善本,以数字化方式回归故土,首批 20 万页古籍已完成数字化,并沉淀为覆盖 3 万多字的古籍字典。公众可通过该平台翻阅、检索古籍。
无论是「汉典重光」还是「识典古籍」,我们都能看到 AI 技术在提高古籍数字化效率方面发挥的作用。
「识典古籍」项目负责人介绍说,为了实现全文检索、标点添加、人名地名标注等功能,「识典古籍」用到了字节跳动积累的文字识别、自动标点、命名实体识别等多项 AI 技术,克服了古籍数字化过程中的很多难题。
文字识别
文字识别就是用 OCR 技术对古籍的影印版文字进行单个切分、文字识别、顺序识别。所谓文字切分,是指古籍扫描件中的单字检测技术,能够获取每个字符的具体位置。文字识别就是将切分的图片送入文字识别模型,获取每个文字的具体编码。顺序识别就是结合文字内容和文字位置,获取整张古籍扫描件的阅读顺序。
这一流程的难点在于,古籍用的是繁体字,而繁体字又存在异体字和生僻字,同样一个简体字在古籍中的写法可能有十几种,如何识别并将它们在搜索结果中完整呈现是一项巨大的挑战。目前行业内 OCR 识别准确率平均为 93% 至 94%,「识典古籍」的准确率可以达到 96% 至 97%。

常见异体字辨别。图源:http://www.xuehuile.com/blog/b6894345d9d446c7b80149c265afc264.html
自动标点
自动标点技术是通过序列标注的方式自动为古籍添加标点。这项工作之前都是由专家、学者来完成,因为他们对古籍有足够的了解。
目前,AI 已经能够胜任一部分工作。「识典古籍」已经支持「,。?!、:;」七种标点。但由于古籍的自然语言理解比普通文本要难得多,目前 AI 还是会犯一些错误(3% 到 4% 左右)。
随着算法的迭代,项目团队有望将标点准确率提升到 98% 左右。
命名实体识别
命名实体识别是通过序列标注,识别古籍文本中的命名实体。「识典古籍」支持识别人名、地名、书籍、时间、官职这五种类型的实体,但它的最终形态并不会止步于此。

「识典古籍」项目负责人介绍说,随着平台版本的迭代,他们希望用知识图谱技术将这些人名、书名、地名等信息关联起来,并将其与百科业务打通,为读者提供更加系统的上下文背景信息。
当然,这些技术也离不开人的支持。王军表示,北大在这次合作中联合各大高校学者和文献专家,负责人工审核与校对,弥补人工智能有识别错误率的短板,并利用自有学术平台,连接更多专业研究者和学生群体。
「在这一系列技术的支撑下,我们不需要再花 300 年才能把 26 万本古籍转换过来,也许我们 30 年就能做到,」王军说。
古籍数字化的下一步:活化
如今,古籍的保护和传承正在受到前所未有的重视。今年 4 月,中共中央办公厅、国务院办公厅印发了《关于推进新时代古籍工作的意见》。今年的全国两会上,「加强文物古籍保护利用」首次被写进《政府工作报告》。各大科技公司也在积极响应这些号召,在古籍保护、传承工作中发挥自己的优势。
就「识典古籍」而言,它还存在很多可以改进的地方,比如典籍数量较少、标点错误率较高,文字也有一定的错误存在。
目前,北京大学 - 字节跳动数字人文开放实验室已经制定了初步目标:在未来三年内陆续完成 10000 种古籍的智能化整理工作,基本覆盖儒家、道家和佛学的核心典籍目录。项目团队的技术理想是通过人工智能算法实现古籍全自动整理校对。如果能够实现这样的能力,他们也非常愿意将其开放给全社会,让所有整理古籍的人都能够免费使用他们的平台。
在聊完古籍的数字化问题之后,王军提出了一个更加尖锐的问题:「如何让一个习惯刷手机的普通用户来看这些晦涩难懂的古代文献呢?」
他给出的答案是:重新阐释。「这种重新阐释不是一字一句去翻译,而是要跟当代人生活结合在一起,为我们当代人精神提供养料,这样才能真正实现活化,」王军解释说。
这种「活化」的提法和胡适的「整理国故,再造文明」是一脉相承的,但也有其时代创新性。
王军认为,放到今天的全球互联网语境下,「再造文明」意味着我们要将整理古籍这件事放到全球文明体系下来看待,「我们保护的不仅仅是中华文明,而是全人类的珍贵文化遗产,所以我们要放在这个大的文明体系下来重新审视我们自己的文明。就像胡适这一批知识分子说的,典籍的重新整理不仅要连接过去与现代,而且要沟通东方和西方,否则就变成一种孤芳自赏。」
这也是北京大学和字节跳动合作的一个终极目标,即要打造融媒体环境下典籍传承的完整生态,为当代人提供心灵滋养和精神寄托。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


