【CVPR2021】反事实的零次和开集识别

零次学习是指让机器分类没见过的对象类别,开集识别要求让机器把没见过的对象类别标成“不认识”,两个任务都依赖想象能力。《反事实的零次和开集识别》提出了一种基于反事实的算法框架,通过解耦样本特征(比如对象的姿势)和类别特征(比如是否有羽毛),再基于样本特征进行反事实生成。在常用数据集上,该算法的准确率超出现有顶尖方法 2.2% 到 4.3%。论文作者岳中琪指出,AI 认知智能的进化刚刚开始,业界的探索仍处在早期阶段,今后他们将不断提升和优化相关算法。
https://www.zhuanzhi.ai/paper/70853146dd56cd4468837754a1478949
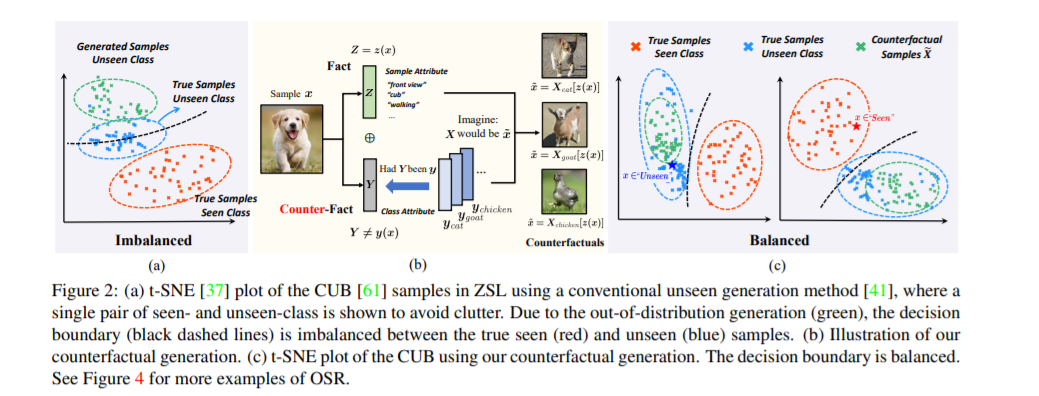
现有的零次学习和开集识别中,见过和未见过类别间识别率存在严重失衡,我们发现这种失衡是由于对未见过类别样本失真的想象。由此,我们提出了一种反事实框架,通过基于样本特征的反事实生成保真,在各个评估数据集下取得了稳定的提升。这项工作的主要优势在于:
我们提出的 GCM-CF 是一个见过 / 未见过类别的二元分类器,二元分类后可以适用任何监督学习(在见过类别上)和零次学习算法(在未见过类别上);
我们提出的反事实生成框架适用于各种生成模型,例如基于 VAE、GAN 或是 Flow 的;
我们提供了一种易于实现的两组概念间解耦的算法
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“GCMCF” 就可以获取《【CVPR2021】反事实的零次和开集识别》电子书专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2021年6月22日
Arxiv
0+阅读 · 2021年6月22日
Arxiv
4+阅读 · 2018年12月22日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年6月22日
Arxiv
0+阅读 · 2021年6月22日
Arxiv
4+阅读 · 2018年12月22日