【面试现场】为什么MySQL数据库要用B+树存储索引?
来自:互联网侦察

小史是一个应届生,虽然学的是电子专业,但是自己业余时间看了很多互联网与编程方面的书,一心想进BAT互联网公司。

话说两个多月前,小史通过了A厂的一面,两个多月后的今天,小史终于等到了A厂的二面。
简单的自我介绍后,面试官看了看小史的简历,开始发问了。

【面试现场】


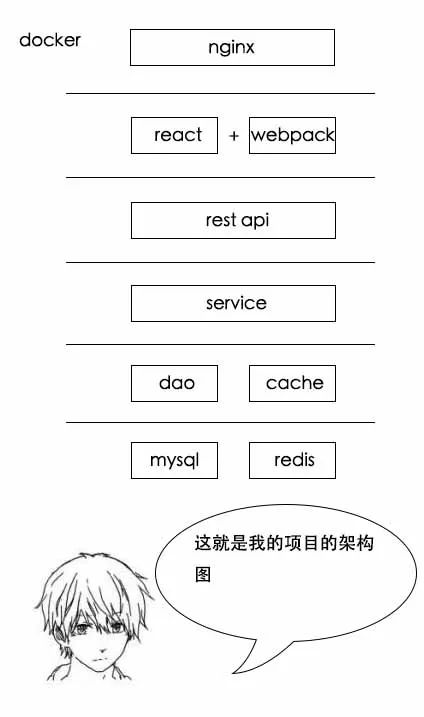
小史:没问题,这个项目前端用的react+webpack,后端用的nginx+SpringBoot+Redis+MySql,前后端分离的,最后用docker进行容器化部署。主要模块有师生系统、课程系统、成绩系统、选课系统等。




这个项目的架构和说辞,小史早已背得溜溜的。

小史:底层mysql是存储,redis是缓存,dao层操作mysql,cache层操作redis,service层处理业务逻辑,rest api层为前端提供rest接口。前端这边用react进行模块化,webpack打包部署。网关nginx进行负载均衡。mysql、redis、nginx和springboot应用都放在docker里部署。














题目:为什么MySQL数据库要用B+树存储索引?
小史听到这个题目,陷入了回忆。
【前段时间的饭局】
话说吕老师给小史讲完人工智能的一些知识后,他们一起回家吃小史姐姐做的饭去了。


【饭后】


吕老师:面试的时候一定是往深了问,不精通的话容易吃亏。不过面试时一般都是根据项目来问,项目中用到的技术,一定要多看看原理,特别是能和数据结构和算法挂钩的那部分。



小史:树的话,无非就是前中后序遍历、二叉树、二叉搜索树、平衡二叉树,更高级一点的有红黑树、B树、B+树,还有之前你教我的字典树。
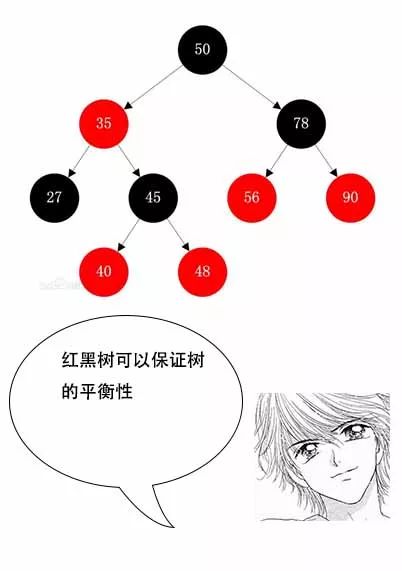
【红黑树】

一听到红黑树,小史头都大了,开始抱怨了起来。

小史:红黑树看过很多遍了,但是每次都记不住,它的规则实在是太多了,光定义就有四五条规则,还有插入删除的时候,需要调整树,复杂得很。

吕老师:小史,问你红黑树,并不是让你背诵它的定义,或者让你手写一个红黑树,而是想问问你它为什么这样设计,它的使用场景有哪些。





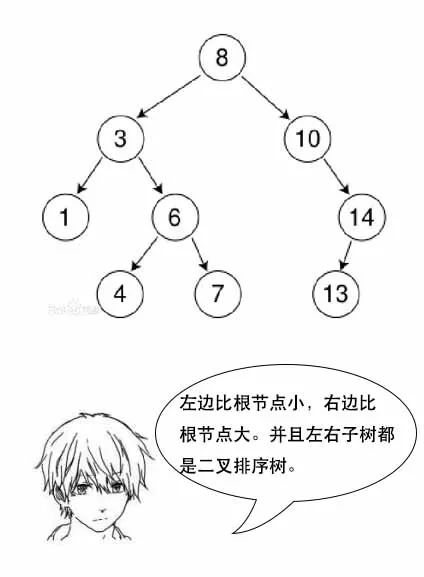

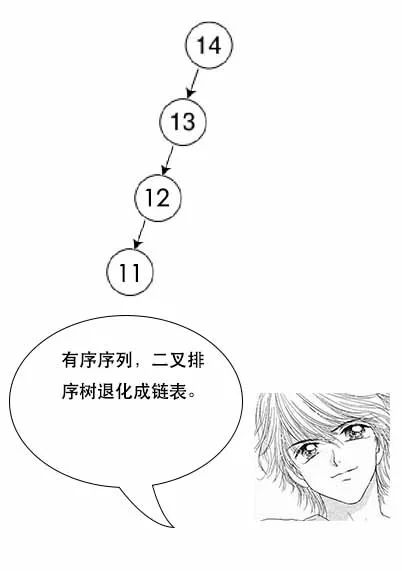






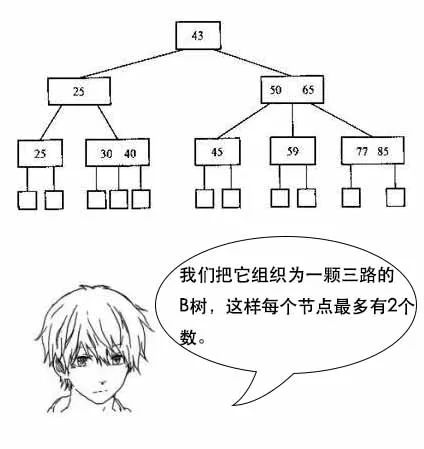
【B树】




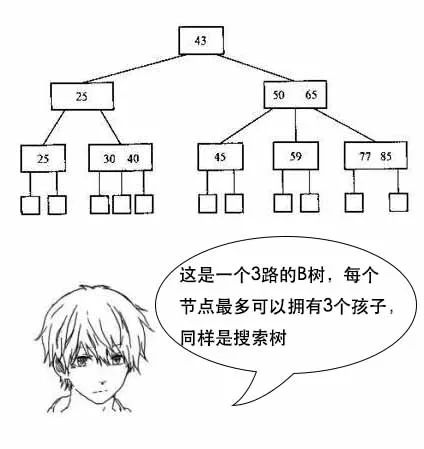




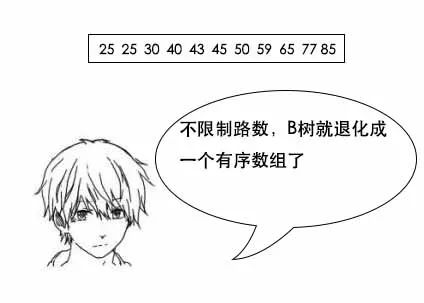







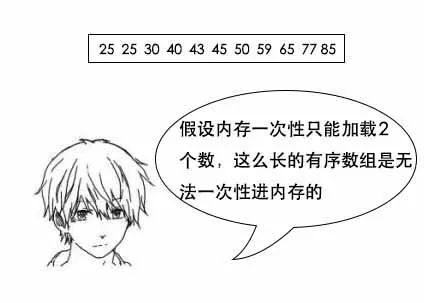
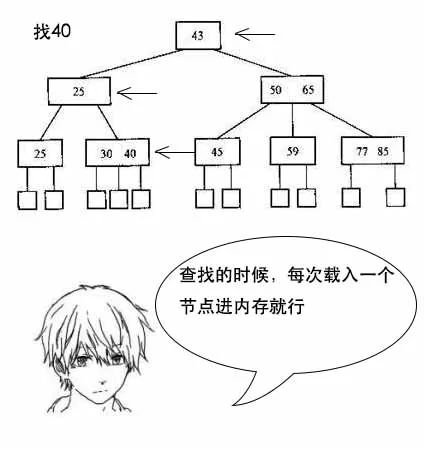
吕老师:小史,你要知道,文件系统和数据库的索引都是存在硬盘上的,并且如果数据量大的话,不一定能一次性加载到内存中。

两个月前,小史面试没考虑内存情况差点挂了,传送门



【B+树】

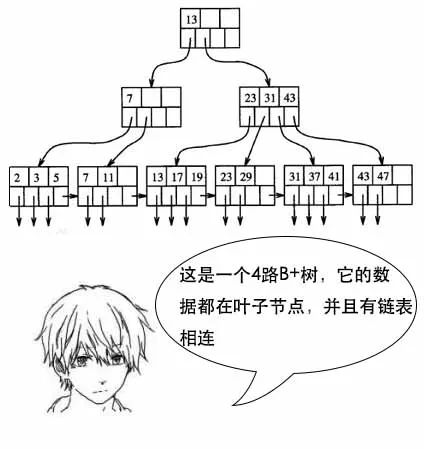





吕老师:这也是和业务场景相关的,你想想,数据库中select数据,不一定只选一条,很多时候会选多条,比如按照id排序后选10条。

小史:我明白了,如果是多条的话,B树需要做局部的中序遍历,可能要跨层访问。而B+树由于所有数据都在叶子结点,不用跨层,同时由于有链表结构,只需要找到首尾,通过链表就能把所有数据取出来了。
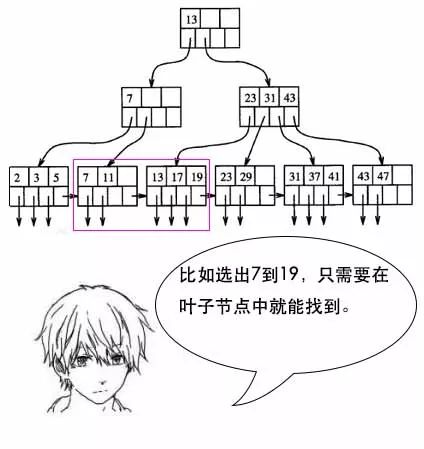

【回到现场】


小史:这和业务场景有关。如果只选一个数据,那确实是hash更快。但是数据库中经常会选择多条,这时候由于B+树索引有序,并且又有链表相连,它的查询效率比hash就快很多了。

小史:而且数据库中的索引一般是在磁盘上,数据量大的情况可能无法一次装入内存,B+树的设计可以允许数据分批加载,同时树的高度较低,提高查找效率。

HR和小史简单地聊了聊基本情况,这次面试就结束了。
小史走后,面试官在系统中写下了面试评语:

几天后,小史收到了A厂的offer。


●编号814,输入编号直达本文
●输入m获取文章目录

人工智能与大数据技术
更多推荐《25个技术类公众微信》
涵盖:程序人生、算法与数据结构、黑客技术与网络安全、大数据技术、前端开发、Java、Python、Web开发、安卓开发、iOS开发、C/C++、.NET、Linux、数据库、运维等。