在本文中,来自加拿大 Mila 研究所唐建课题组的研究人员提出了一种图上高性能的嵌入训练系统——GraphVite,训练百万级别的节点嵌入只需 1 分钟左右,比现有实现快 50 倍以上。该系统最大可处理二十亿边的图,是目前速度最快、规模最大的单机图嵌入系统。
图是一种通用、灵活的数据结构,可以用来编码不同对象之间的关系,并且在现实世界中非常普遍,如社交网络、引文图、蛋白质相互作用图、知识图谱等,涵盖了多个应用和领域。
最近,由于图在多个任务中表现出色,越来越多的研究人员开始尝试学习图的有效表征。
然而,这是一个颇具挑战性的问题,因为现实世界中的图可能非常庞大,并且是异质的。
因此,业界和学界的不同任务和应用都迫切需要可扩展的通用图表征系统。
为此,加拿大 Mila 研究所唐建课题组的研究人员开发了一个通用、高性能的图嵌入系统——GraphVite。
相较于 TensorFlow、PyTorch 等侧重张量计算的机器学习系统,该系统针对大规模图学习的特性,创新地将图中的边集划分成多个部分,使多 GPU 能以非常小的同步代价进行训练,并在多 GPU 上取得接近线性的加速比。
架构中还将采样部分移至 CPU 部分,既节省了超大图的显存开销,又充分利用了 CPU 和主存的随机访问特性。
相比已有系统或实现,该系统将嵌入训练速度提升了一至两个数量级,只需约一分钟的时间即可完成百万级别的节点嵌入训练,比现有实现快 50 倍以上。
该系统对大图上也有非常好的可扩展性,单机即可训练十亿级别的超大规模图嵌入,是目前速度最快、规模最大的单机图嵌入系统。
目前,该项目已经开源。
GraphVite 的开源版本包含节点嵌入、知识图谱嵌入和图结构&高维可视化三个应用的实现:
节点嵌入。目的是学习大规模图的节点表征。GraphVite 目前包含一些 SOTA 节点嵌入方法,如 DeepWalk、LINE 和 node2vec,未来还会继续增加。
知识图谱嵌入。目的是学习实体和关系的表征,目前支持多种表征方法,包括 TransE、DisMult、CompEx、SimplE 和 RotatE,之后还会加入更多方法。
图&高维数据可视化。GraphVite 还支持学习节点的二维或三维坐标来实现图的可视化,还可以泛化到任何高维数据的可视化。这对于可视化深度神经网络学到的表征形式特别有用。GraphVite 目前已经实现了最先进的可视化算法之一——LargeVis,未来还会实现更多的可视化算法。
![]()
除了惊人的速度,GraphVite 还为研发人员提供了用户友好的完整应用 pipeline。
该系统具有数据集和评估任务等模块,是一个用于嵌入模型和实验的自成体系的环境。
其标准数据集中包含 30 多个现有模型的基线基准。
只需一句指令即可复现这些基准,部署到更大的数据集也很容易,方便为图表征学习开发新的模型。
该研究显著加快了图嵌入、知识图谱嵌入和图结构&高维可视化的训练速度,将多个标准数据集上的嵌入训练时间刷新到了 15 分钟左右,直接促进了图上嵌入算法的实现与迭代,间接影响了图表征学习算法研发的范式。
单 GPU 17 分钟生成完整 ImageNet 数据集特征空间的可视化,极大地方便了深度学习模型的调试和可视化。
相较于同期 FAIR 的 PyTorchBigGraph 系统,单机多卡的设计更有助于学界的普及使用。
该系统所支持的超大规模图训练将会为工业应用带来不少机遇。
GraphVite 根据 CPU 和 GPU 各自体系结构的特点,将图嵌入训练分为采样和训练两个部分,分别交由 CPU 和 GPU 完成。
其中采样部分使用 CPU 并行在线增强,解决了现有算法中增强后的图占用内存过大的问题。
训练部分,系统提出了一种并行的负采样方法。
该方法将顶点的嵌入划分为若干块,并将每条边按其两端顶点进行分块。
在训练过程中,多块 GPU 始终在顶点集不相交的块上工作。
这一设计极大地减小了多 GPU 之间的同步代价,并使参数矩阵超出显存的大规模嵌入训练成为可能。
此外,GraphVite 还采用协同策略,令多 CPU 和多 GPU 异步工作,从而使训练速度翻倍。
节点嵌入方法的第一阶段是利用随机游动(random walk)来增强原始网络。
由于增强后的网络通常要比原始网络大一至两个量级,因此若原始网络已经足够大,则不可能将增强后的网络导入主存。
因此,研究人员提出了并行在线增强,它能够在线生成增强后的边样本,同时又无需显示地存储增强后的网络。
这种方法可视为 LINE 中所用到的增强和边采样方法的一种在线扩展。
首先,研究人员随机采样一个初始节点(depature node),其选择概率与节点度成正比。
然后,他们从初始节点执行随机游动操作,同时选择特定增强距离内的节点对作为边样本。
这里要注意的是,同一随机游动中生成的边样本具有相关性,可能会使训练效果变差。
受启发于强化学习中广泛使用的经验回放方法,研究人员收集边样本到样本池,并且在转移样本池至 GPU 进行嵌入训练之前对它展开洗牌(shuffle)。
当每个线程提前分配至单独的样本池时,文中提出的边采样方法可以进行并行化处理。
![]()
尽管样本池的洗牌对优化非常重要,但同时也减慢了网络增强阶段的运行速度(参见表 7)。
原因在于:
一般的洗牌包含大量随机存储访问,无法通过 CPU 高速缓存获得加速。
如果服务器不只有一个物理 CPU 插座(socket),则速度损失会更加严重。
为了缓解这个问题,研究人员提出了伪洗牌(pseudo shuffle)方法,该方法以一种更有利于高速缓存的方式对关联样本进行洗牌,并显著提升了系统运行速度。
在嵌入训练阶段,研究者将训练任务分解成小的片段,并将它们分配给多个 GPU。
子任务的设计必须使用少量共享数据,以最小化 GPU 之间的同步成本。
为了弄清如何将模型参数无重叠地分配到多个 GPU,研究者首先引入了一个ϵ-gradient exchangeable 的定义。
![]()
基于节点嵌入中观察到的梯度可交换性,研究者提出了一个用于嵌入训练阶段的并行负采样算法。
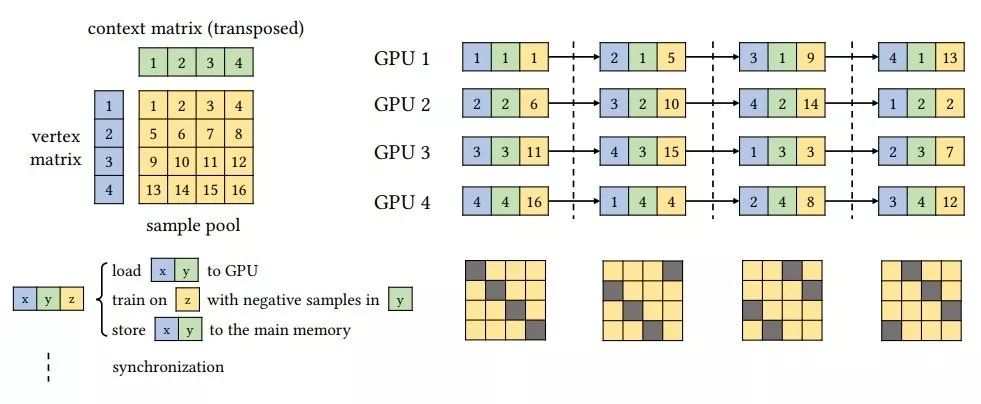
对于 n 个 GPU,他们将顶点行和语境行分别划分为 n 个分块(见图 2 左上角)。
结果得到一个 n × n 的样本池分块网格,其中每条边都属于其中一个块。
如此一来,只要对每一块施加迭代数量限制,任何一对不共享行或列的块都是 gradient exchangeable。
相同行或列里的块是ϵ-gradient exchangeable。
研究者将 episode 定义为并行负采样中使用的块级步骤。
在每个 episode 中,他们分别向 n 个 GPU 发送 n 个不相交的块及其对应的定点和语境分块。
接下来,每个 GPU 借助 ASGD 更新自身的嵌入块。
由于这些块是梯度可互换的,并且在参数矩阵中不共享任何行,因此多个 GPU 可以在不同步的情况下同时执行 ASGD。
在每个 episode 结尾,研究者从所有 GPU 中收集更新的权重并分配另外 n 个不相交的块。
此处的ϵ-gradient exchangeable 由 n 个不相交块中的样本总数来控制,研究者将其定义为 eposode size。
eposode size 越小,嵌入训练中的ϵ-gradient exchangeable 越好。
然而,较小的 eposode size 也会导致更频繁的同步。
因此,episode size 的大小需要在速度和ϵ-gradient exchangeable 之间进行权衡。
下图 2 给出了 4 个分块的并行负采样示例。
![]()
图 2:
在 4 个 GPU 上的并行负采样示例。
在每个 episode 期间,GPU 从样本池中获取正交块。
每个 GPU 利用从自身上下文节点中获取的负样本训练嵌入。
同步只需要在 episode 之间进行。
通常来讲,节点嵌入方法从所有可能的节点中采样负边。
然而,如果 GPU 必须通过互相通信才能获得它们自己的负样本,那将非常耗费时间。
为了避免这一开销,研究者对负样本进行了限制,规定其只能从当前 GPU 语境行获取。
尽管这看起来有点问题,但实际效果非常好。
注意,虽然本文中列出的分区数等于 n,但并行负采样可以很容易地推广到分区数大于 n 的情况,只需在每个 episode 期间处理 n 的子组中的不相交块即可。
下图中的算法 3 展示了这一多 GPU 的混合系统。
![]()
上述并行负采样使得不同的 GPU 可以同时训练节点嵌入,只需要在 episode 之间进行同步。
然而,应该指出的是,GPU 和 CPU 之间也共享样本池。
如果它们在样本池上同步,那么只有同一阶段的 worker 才能同时访问样本池,也就意味着硬件只在一半的时间处于理想状态。
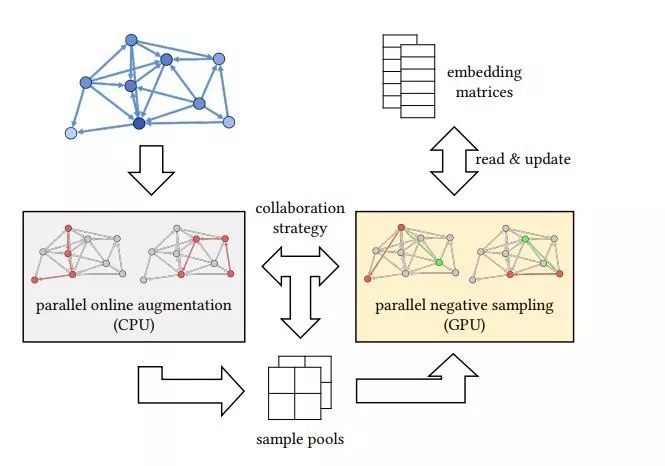
为了解决这一问题,研究者提出了一种协作策略来减少同步开销。
他们在主内存中分配了两个样本池,让 CPU 和 GPU 始终在不同的样本池上工作。
CPU 首先填充一个样本池并将其传送给 GPU。
然后,分别在 CPU 和 GPU 上并发执行并行在线增强和并行负采样。
当 CPU 填满一个新池时,这两个采样池进行调换。
下图 1 展示了这一步骤。
利用这种协作策略可以降低 CPU 和 GPU 之间的同步成本,同时将系统的速度加倍。
![]()
图 1:本文中的混合系统概览。灰色和黄色框分别对应网络增强和嵌入训练阶段。这两个阶段借助本文提出的协作策略异步执行。
研究人员利用实验验证了 GraphVite 的有效性和效率。
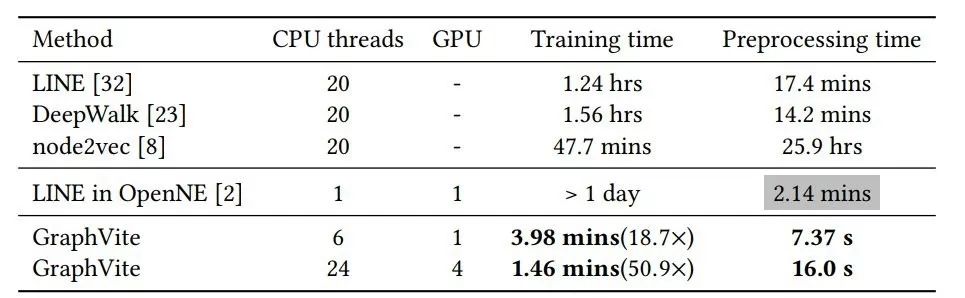
他们首先在 Youtube 数据集(节点嵌入文献中广泛使用的大型网络)上对系统进行评估,然后又在三个更大的数据集(Friendster-small、Hyperlink-PLD 和 Friendster)上评估了 GraphVite。
![]()
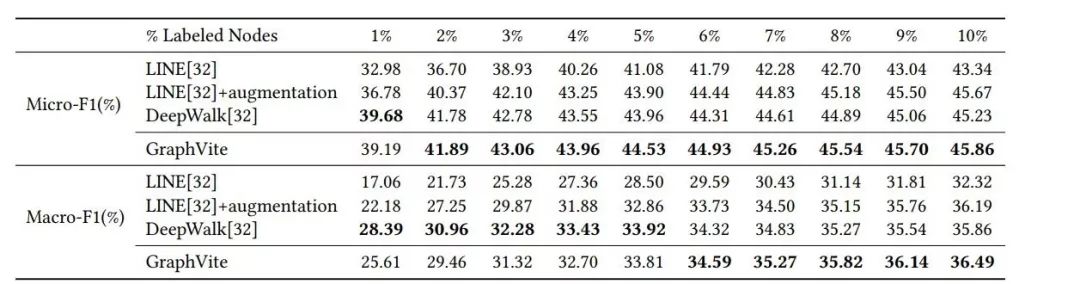
表 3:Youtube 数据集上不同系统的时间结果。预处理时间指的是训练前的所有开销,包括网络输入和离线网络增强。需要注意的是,OpenNE 的预处理时间没有可比性,因为它缺少了网路增强阶段。GraphVite 的加速比基于当前最快的系统 LINE 进行计算。
![]()
表 4:
Youtube 数据集上的节点分类结果。
![]()
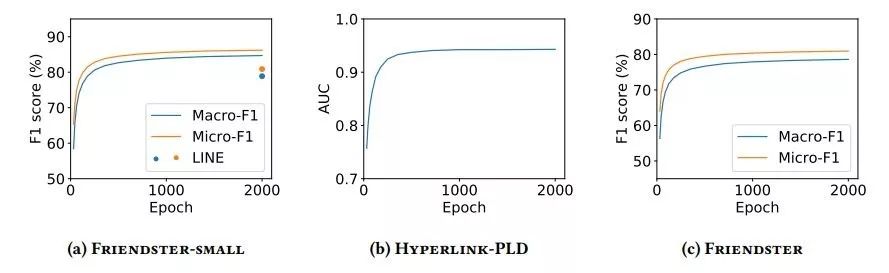
表 5:更大数据集上的时间结果。研究人员只用 4 个 GPU 评估了 Hyperlink-PLD 和 Friendster 数据集,因为它们的嵌入矩阵无法读入单个 GPU 的内存。
![]()
图 4:
GraphVite 在更大数据集上的性能曲线。
对于 Friendster 数据集,研究人员绘制了 LINE 的结果以供参考。
其他系统无法在一周内解决以上任何一个数据集。
为了更全面地了解 GraphVite 的不同组件,研究人员进行了以下几项控制变量实验。
为了呈现出直观的比较,他们在标准 Youtube 数据集上对这些实验进行评估。
由于空间限制,研究人员只提供了 2% 标记数据基础上的性能表现结果。
所有的加速比根据 LINE 进行计算。
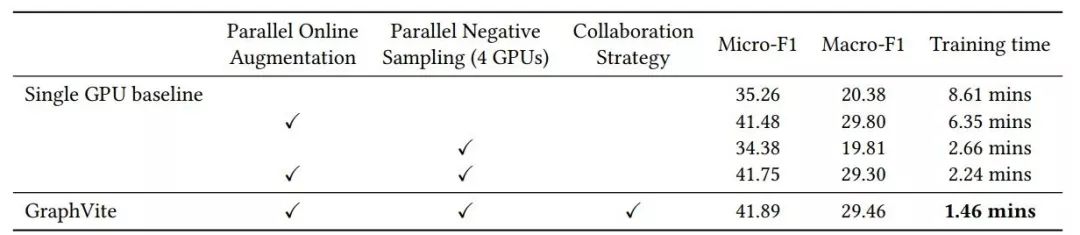
![]()
表 6:
GraphVite 主要组件的控制变量。
需要注意的是,基线具有与 GraphVite 相同的 GPU 实现效果,并在 CPU 上展开并行边采样。
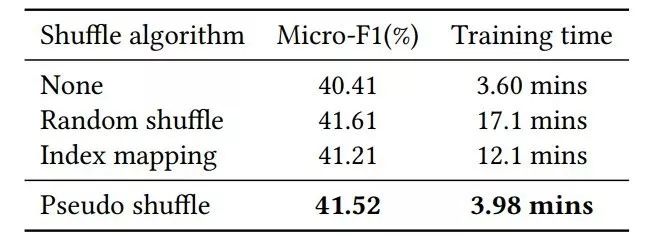
![]()
表 7:
不同洗牌算法下的性能表现结果和训练时间。
文中提出的伪洗牌(pseudo shuffle)算法在性能和速度之间达到了最佳权衡。
![]()
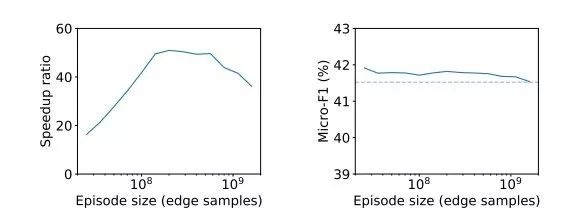
图 5:
不同 episode 大小下 GraphVite 的速度和性能表现。
虚线表示未进行并行负采样的单个 GPU 基线。
![]()
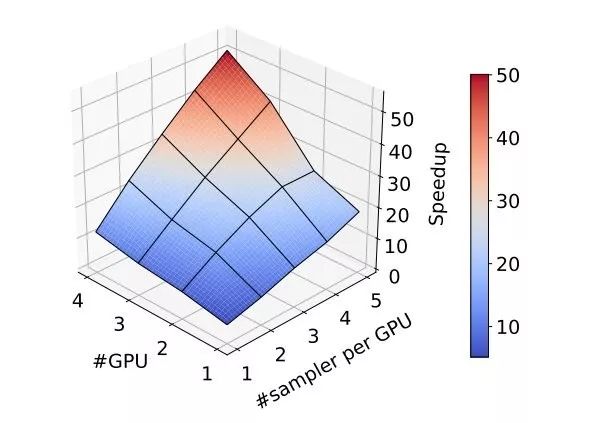
图 6:
不同硬件数量下的加速结果。
加速几乎与 CPU 和 GPU 的数量呈线性相关。
![]()
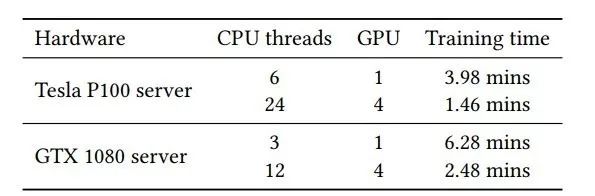
表 8:
Tesla P100 服务器和 GTX 1080 服务器两种硬件配置下的 GraphVite 训练时间。
这项工作由加拿大 Mila 研究所唐建老师小组的博士一年级学生 Zhaocheng Zhu 担任一作,Shizhen Xu 和 Meng Qu 也参与了研究。
加拿大 Mila 研究所是由图灵奖得主 Yoshua Bengio 带领的深度学习研究所。
作为学界最大的机器学习研究机构之一,Mila 专注于深度学习相关的基础研究,以及学习算法在不同领域的应用。
研究所在机器翻译、物体识别和生成模型等方面有诸多为人熟知的工作,著名的《Deep Learning》一书亦出自 Mila。
唐建老师带领的研究组是 Mila 活跃的图学习研究小组,其主要方向包括图表征学习和深度学习的基础研究,涵盖知识图谱、药物发现和推荐系统等不同应用领域。
研究组在图表征学习领域具有相当的知名度,代表作有 LINE,LargeVis 和 RotatE 等等。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com