微软亚洲研究院副院长张益肇:弱监督学习在医学影像中的探索 | CCF-GAIR 2018


AI 科技评论按:2018 全球人工智能与机器人峰会(CCF-GAIR)在深圳召开,峰会由中国计算机学会(CCF)主办,雷锋网、香港中文大学(深圳)承办。
本次大会共吸引超过2500余位 AI 业界人士参会,其中包含来自全球的 140 位在人工智能领域享有盛誉的演讲与圆桌嘉宾。
大会第二天的 【计算机视觉专场】中,ICCV 2011和CVPR 2022大会主席权龙、微软亚洲研究院副院长张益肇、飞利浦中国CTO王熙、旷视科技首席科学家孙剑、7大Fellow获得者田捷、国际最高级别医学影像分析大会MICCAI 2019 联合主席沈定刚等人发表了重要演讲。
大会第二天的计算机视觉专场分为视频监控和医疗影像两个半场,汇集了两个领域的众多大咖。下午的医疗影像半场,微软亚洲研究院副院长张益肇博士发表了题为“弱监督学习在医学影像中的探索”的精彩演讲。
张益肇博士援引一篇报道表示,2000年左右出生的人,超过一半寿命将超过100岁。这将加剧人口老龄化,增加医疗支出。如果没有新的技术提高医疗效率、降低医疗成本,社会将难以承受。
过去两年大火的人工智能技术起到了一定的帮助。但训练人工智能模型需要标注大量的数据,能够标注医疗影像数据的专家又非常稀缺,时间成本也很高。为此微软亚洲研究院尝试用弱监督学习的方法,提高可被使用的数据量,取得了不错的成效。
张院长表示,微软亚洲研究院希望推动人工智能的普及化,但这一过程还需要与各方伙伴合作。他希望合作伙伴一要有丰富的数据资源,二要有足够的耐心和诚意。因为用人工智能解决医疗问题在技术上可行,但真正落地到医院却是一个漫长的过程。
以下是张益肇院长的全部精彩演讲内容,雷锋网做了不改变原意的整理与编辑:
感谢主办方提供机会,让我介绍微软在医学影像领域的探索。
我今天的演讲分为三部分:首先,介绍机器学习和人工智能在医疗领域的机会;其次,介绍我们过去使用的一个算法——弱监督学习,以及它为什么在医学影像领域特别有效;最后,介绍微软在医学影像领域的实践案例,包括北京、印度和剑桥的同事做的一些案例。
希望今天能通过很短的时间给大家一个印象,让大家了解微软对医疗的看法,以及人工智能在医疗方面的应用。
人工智能在医疗领域的机遇
首先分享一个好消息。粗略统计,今天台下听众本人是90后或孩子是90后的人占到了70-80%。我做医学研究的时候曾看到这样一篇报道说,按照医学的发展速度,2000年左右出生的人,超过一半寿命将超过100岁。这将是一个非常了不起的成就,我非常期待。看到这个好消息,我非常振奋也很好奇,就去查阅了这篇文章背后的学术论文。
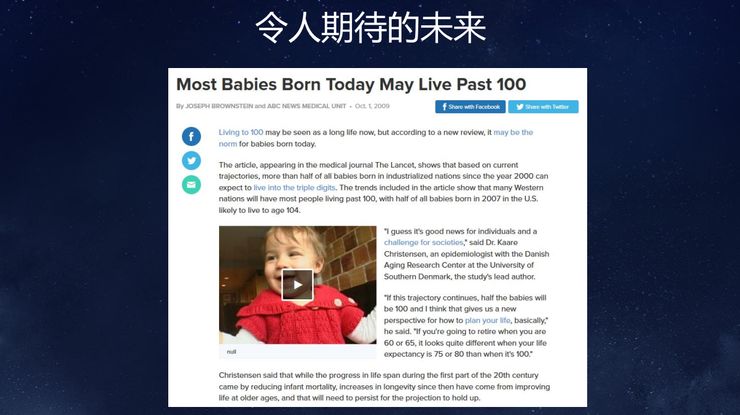
我看到一篇2009年在英国《柳叶刀》杂志上发表的论文,它标题写的是“未来的挑战”。假如未来超过一半的人寿命超过100岁,对社会医疗系统将是非常大的挑战。现在人口老龄化已经非常严重,通常来说,人的年纪越大医疗成本就越高。假如超过一半人活过100岁,而我们又没有更好的医疗方法,将给社会带来很大的成本。我们刚开始做医疗研究时,美国每年大约有14%的GDP耗费在医疗上,现在这一占比已经上升到了18%,越来越高了。按这个趋势发展下去,社会将无法承受。我们相信,解决这个问题一定要靠技术。如果没有新的技术,就无法给大家提供好的医疗条件,让大家健康快乐地活到100岁。

我举一个医疗领域的例子——病理切片的解读,这在中国是一个特别大的挑战。中国每10万人口中只有不到两位病理医生,美国每10万人中有超过50位病理医生,日本每10万人中也有超过10位病理医生。也就是说,中国的病理医生非常缺乏。我们再看病理医生要做哪些工作:假如一个人不幸患了肺肿瘤,病理医生要把他的切片切成二三十片,然后仔细观察其中哪一类是病变的,是什么样的病变,A、B、C类型病变的百分比各是多少。这个工作很耗时间,另外,训练这样的专业人才也很困难。假如我们可以用电脑辅助医生做这些工作,是不是可以让他们更加高效?

弱监督学习
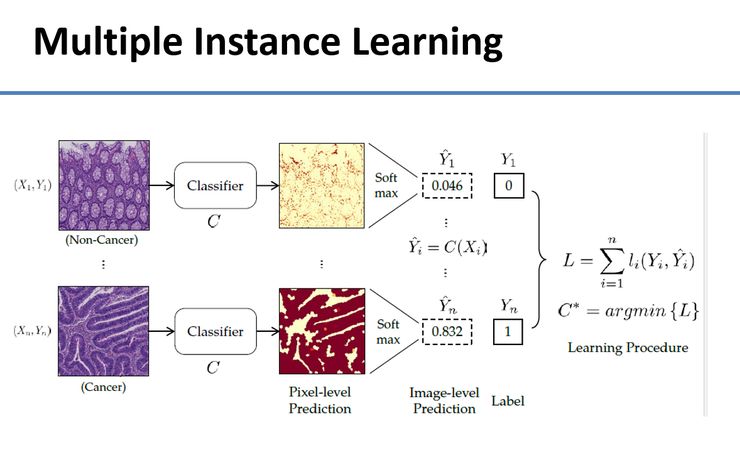
所以我们提出了机器学习,这就带出了我的下一个话题——弱监督学习。为什么要提弱监督学习?面对一个病理切片,我们通常有三个目标——分类、切割或聚类。病理图片通常很大,一张病理图片可以达到5万X5万像素,甚至更大。训练模型有三种方法:一是没有标签的训练,这对病理图片来说很难;二是弱标签训练,即利用相对简单的标签学习;三是带详细标签的训练,比如刚才提到的肺肿瘤的例子,你需要标注每一个肿瘤组织的情况。
下面给大家展示两张图片,看看人类是如何学习的。

我给几位医生看过这两张图片,他们很快就发现了其中的差别:上面这张图片中有两种鱼,除了橘色的小丑鱼,还有一种黑白相间的鱼;下面这样图片则只有小丑鱼。使用弱监督学习的时候,只要告诉系统这两张图片有差别,不需要说明差别在哪,让他自己学习就好了。这样一来,标注的工作就少了很多。
回到病理切片的例子,下面这张图片中既有癌细胞又有正常细胞:上面的是癌细胞,下面的是正常细胞。就像前面讲的,我们只需要提供这两类图片,无需勾画所有癌细胞和正常细胞的边界,系统就能学习。这样的好处在于:中国的病理医生很缺乏,让他们标这些图像的边界是非常大的工作量而且也很难。现在只需要标出有没有癌细胞,就相对容易多了。弱监督学习的优势就在于在减少标注工作量的情况下,更充分、有效地利用数据。
这种弱监督学习的方法我们从2012年就开始使用了,当时还没有深度学习。下面介绍一项新的研究成果——把弱监督学习和深度学习结合在一起。大家如果感兴趣,可以查阅我们去年11月发表的论文。
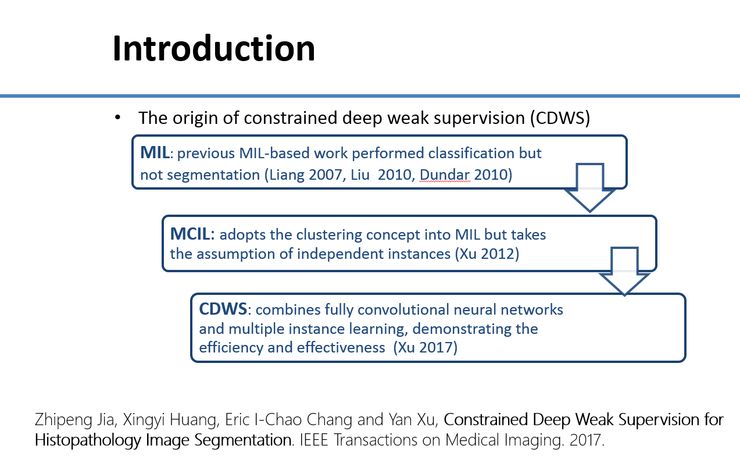
这个方法的基本概念是训练两个分类器,上面是正常细胞,下面是有癌细胞。我们希望自动训练分类器,让它在像素级别告诉我们一个细胞到底是癌细胞还是正常细胞。我们统计出图片中的细胞有癌还是无癌后,再把它放到下图中的训练方程式里。
下面是一张比较完整的架构图,我们不仅分了好几层,还用到了Area Constraints。
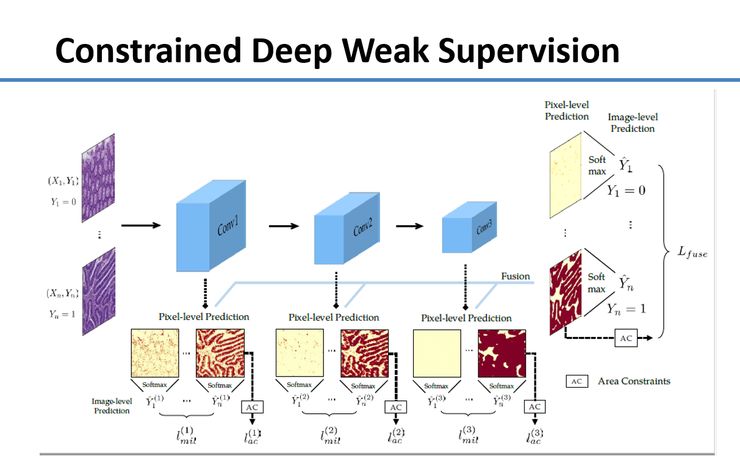
如果光用刚才讲的分类的方法,不管一张图片中有10%的面积是癌细胞,还是60%的面积是癌细胞,它训练的评价模式是一样的。所以它倾向于把越来越多的细胞当成癌细胞。我们想,能不能继续减少标注量,同时还能得到更好的效果?于是我们加入了Area Constraints。医生只需要估计里面到底有10%、20%还是30%的面积是癌细胞就可以了,而不用标出癌细胞在哪,这又减轻了工作量。我们让两位医生标注,如果标注结果不统一,再请第三位医生来看哪个标注结果是正确的。

下图中的数据库是我们微软亚洲研究院和浙大合作的,用一些大肠癌的图片训练,训练数据约有600张,测试数据有两百张左右。

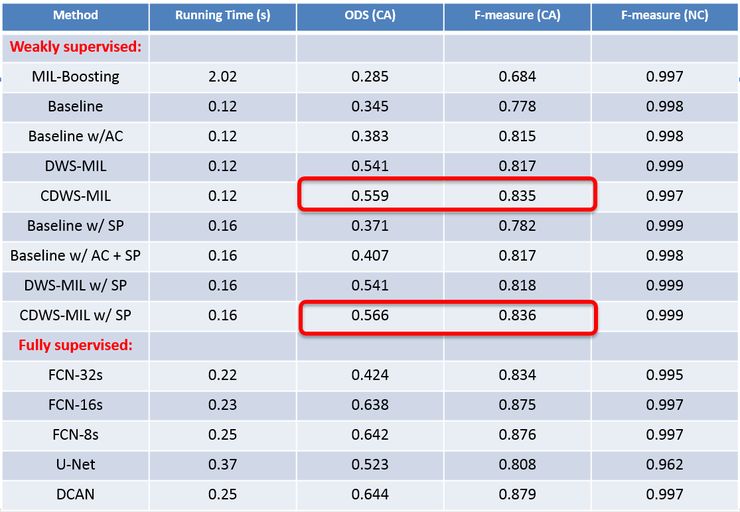
我们用这个方法实验,来看一下结果。下图中红色标注的是弱监督学习的结果,它的指标与人工判别的情况差不多,跟大量标注训练的结果也差不多。我们希望通过这种方法,用更多数据来训练——原来只有一两百张,现在可以用几千张——同时大幅降低数据标注的成本。
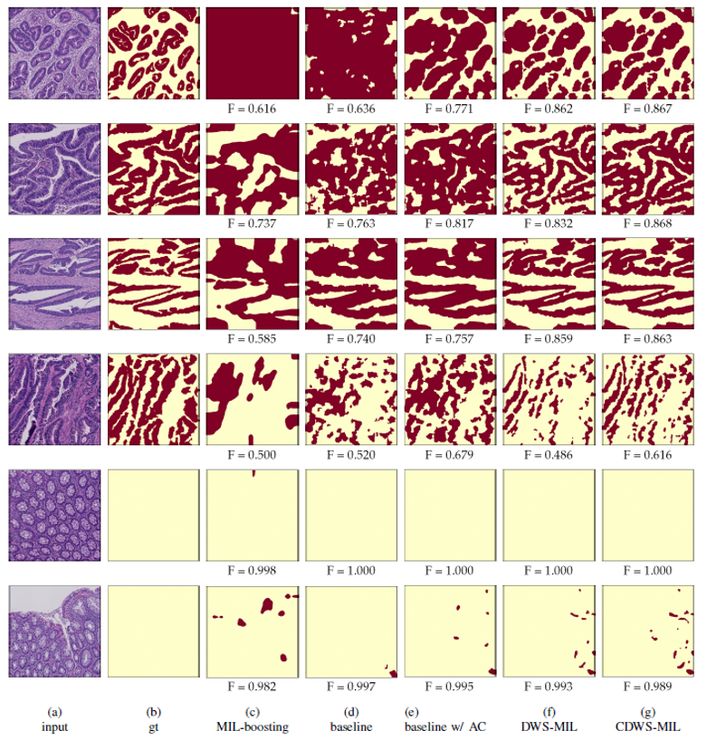
下图也展示了我们的成果:第二列是医生标注的结果,最右边一列是我们系统标出来的结果。可以发现,只要有癌细胞的地方,系统基本都找出来了。这是我们2012年还没有用深度学习时达到的效果,这五年里又取得了很多进步。
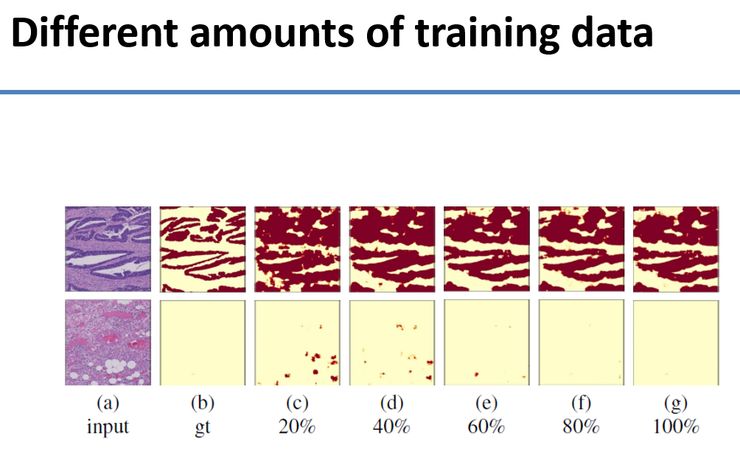
下图中我们改变了训练的数据量,从20%-100%,数据越多,效果就越好。
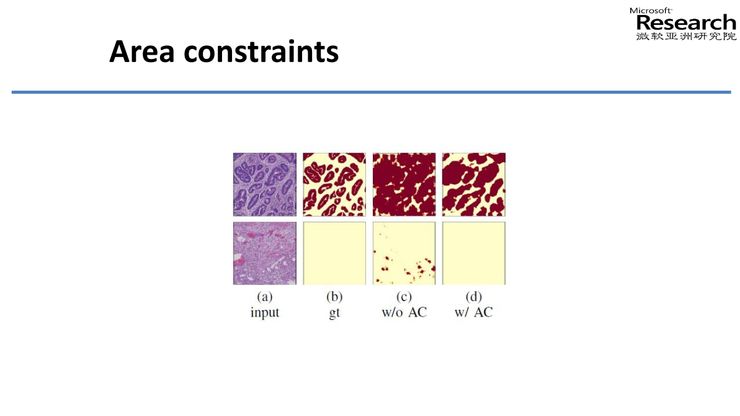
下图是我们加入Area Constraints前后的对比。加入Area Constraints之前,系统把大部分细胞当成了癌细胞,加入之后它把所有正常细胞和癌细胞进行了区分。
简单总结一下:我们希望通过端到端的深度学习方法培育这个系统,帮助在标签有限的情况下,进行医学影像的处理、分类和切割。这种方法除了前面提到的大肠癌,在很多其他领域也可以用到,比如肺癌、宫颈癌等。因为它们面对的是同样的问题,有很多数据需要标注。如果能减少标注时间,就能利用更多的数据。

合作案例
除此以外,我们微软亚洲研究院在别的领域也做了一些研究,比如我们和比尔盖茨基金会合作的疟疾方面的应用。疟疾现在仍是全球的一个大问题,每年有七八十万人——相当于每天有近2000人死于疟疾。大家或许感觉不到,因为疟疾主要发生在欠发达地区。
比尔盖茨基金会和一家厂商合作,开发了一款很小的设备,它可以自动扫描玻璃膜片,在穷乡僻壤帮助诊断疟疾。医务人员只需要抽血做膜片就可以了,不必从膜片中找红血球和疟疾细菌侵入的样本。这个系统可以自动扫描出有多少红血球被疟疾细菌侵入了,统计疟疾细菌侵入的密度,密度越高表示病情越严重。长期治疗中,我们可以用这种方法观察密度的变化。如果膜片有很多层,系统还可以自动对焦,看哪个是最准的。

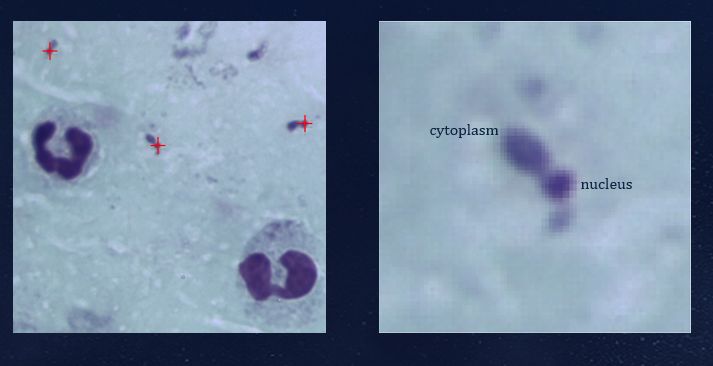
下面列举了一些案例。图中红色部分是被疟疾侵入的细胞,用肉眼很难看出来。每天要看这么多膜片,统计被入侵红血球的数量,是一项非常繁琐的工作。这项工作需要专家来做,但在非洲和拉丁美洲的偏远农村,根本不可能找到这方面的专家。所以我们希望通过这种方法,让电脑自动完成这些工作。
再看一个脑肿瘤病理切片分析的例子,脑肿瘤病理切片分析也是一项庞大的工作。一个肿瘤被切除后,需要知道切片中的肿瘤属于哪一类,这决定了你的预后处理方式,是观察、化疗,还是放射性治疗。病理医生需要看切片然后给出建议,这中间存在着两大挑战——分类和切割。
一般病理图片非常大,2014年已经有了深度学习系统,我们当时决定,不管分类还是切割都用深度学习的方法来做。深度学习不需要涉及特征,而是通过机器学习的方法学习特征。我们用到的是迁移学习的方法,也就是说,特征不是在病理切片等医学影像上训练,而是在ImageNet上训练出来的。虽然如此,这个神经网络还是可以抽取病理图像的信息,把它送入分类器并分析出来。
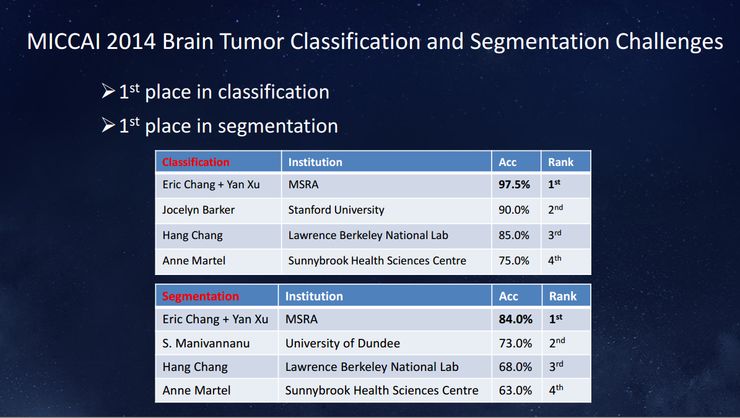
下图是我们2014年用这种方法获得的结果,不管在分类还是切割上都排名第一。当时深度学习刚刚出来,我们在这个课题第一次使用了深度学习,而后面几名都没用,可见当时深度学习的效果。
作为一家平台公司,微软需要跟不同领域的专家和企业合作,才能更大程度地发挥人工智能等前沿技术的价值。
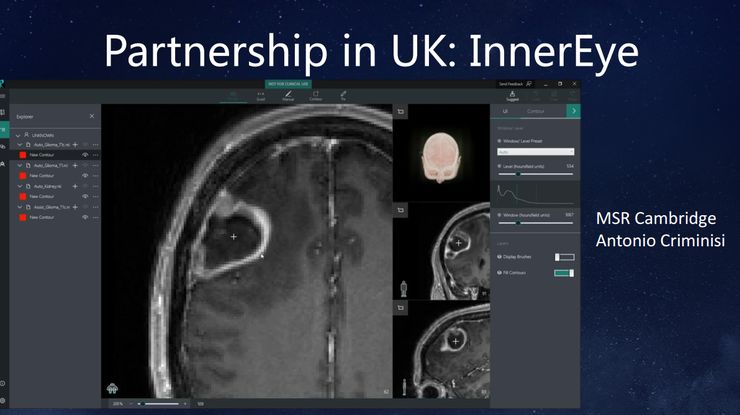
下图介绍了我们和英国剑桥医院的医生合作的一个关于图像分割的项目。假如一个脑肿瘤患者要做放射性治疗,第一步要把肿瘤分割出来,甚至还要标出一些正常部位,比如管视觉或听觉的部位。通过这种方法让放射性治疗更精准,避免误伤其他细胞。
我曾经问做放射性治疗的医生,做这件事情要花多长时间。他回答说,这件工作挺复杂的,可能需要30分钟左右。我又问,如果病人是你的母亲,你会花多长时间。他回答说,这种情况可能要花三个小时。大家都是人,为什么会有这种差别?这表明,很多情况下医生无法花那么长时间细致地做这件事。所以,我们希望利用人工智能和机器学习,帮助医生更高效地完成工作。
再看一个微软与印度合作的案例。我们和印度一家做眼底设备的企业合作,检测视网膜上的糖网病变,做早期筛查,评估病变的严重程度。目前全世界有超过20个国家在使用这家企业的设备,治愈了超过20万名病患。美国FDA不久前刚刚批准了这类应用。我相信国内也有很多合作伙伴在做这类事情。我的看法是,这种技术多多益善。

我们还和印度另一家机构合作,分析病人是不是有近视,会不会转化成严重近视,以及是否会出现视网膜脱落等。这家机构有很多小孩子在不同年纪拍摄的眼底照片。我们基于这些照片进行机器学习,用算法检测他的眼部疾病是否会继续恶化。

除了医学影像之外,还有没有别的利用人工智能改善医疗的机会?我这里也有一些案例。
美国每年有38000人死于交通事故,很多交通意外是由人为因素导致的,所以大家对自动驾驶充满热情。如果我们能用自动驾驶减少这些人为因素,即使只减少一半,在美国每年也能挽救近2万人的生命,是对社会的巨大贡献。
美国约翰霍普金斯的一个团队做过调查,美国医院里每年有近26万人因为医疗意外(包括交叉感染、意外跌倒等)死亡,是除心脑血管疾病和癌症之外的第三大死因,致死人数是车祸的近6倍。如果我们能用技术减少这种错误,对社会也是巨大的贡献。

这方面我们也有一些案例。比如,微软跟巴西一家医院合作,通过视频分析病人在病床上的行为。如果病人在床上,但是安全栅栏没拉起来,系统就会发出警报,提醒护士查看。这里又要提到弱监督学习,因为视频的数据量非常大,如果每一帧都要标注,工作量十分庞大。采用弱监督学习的方法,只要看到病人有没有下床就可以了,不用每一帧都标注。
未来,在医院的复杂环境中,可以通过计算机视觉判断更多情况,比如一个刚刚做完手术的病人是否走得太远了,需不需要人去接他等。通过这种方法可以减少医疗意外。

最后快速总结一下:有人开玩笑说,所谓的人工智能是靠大量人工实现少量的智能,比如做图片识别,需要先找大量人对图像进行标注。医疗影像的标注需要专业知识,甚至需要几位专家商量后才能决定怎么标,很难找到这么多标注人员,标注成本也很高。
所以我们希望通过弱监督学习的方法提高可被使用的数据量,充分发挥机器学习的能力,构建更复杂和精确的模型。
我案例中提到的很多场景,从病理切片到视频分解,都可以采用类似的模式来减少数据标注工作。关于这些案例,我们网站上有详细介绍,欢迎大家访问浏览。
未来希望能与各地的不同企业和单位合作,在医疗领域充分发挥人工智能的价值,让大家可以健康活到100岁。谢谢!
以下是问答环节的精彩内容:
提问:您刚才提到用AI摄像头监控病房,目前应该只是做行为观测,有没有更深入一点的,比如分析病人的心跳、呼吸或睁眼等情况?
张益肇:这个想法很好,需要我们跟合作伙伴一起实现。你刚才提到的眨眼识别,我们研究院做了一些表情分析的研究。针对心理疾病患者,可以通过表情的变化进行分析和监测。
提问:微软在医疗领域有没有用人工智能处理CT或者三维数据?
张益肇:有。我刚才提到英国同事做的肿瘤和健康组织的分割就是三维的。另外,我们在北京也在做肺结节识别的研究,也是三维的。今天时间有限所以没有介绍。
提问:微软研究院主要做基础科研,这些技术能不能对外合作?
张益肇:可以。我们希望把人工智能普及化,如果有好的伙伴,我们很愿意合作。我们对合作伙伴的要求是,要有数据资源和合理的期望值。因为产品在技术上是可行的,但真正在医院落地是一个漫长的过程。我们希望合作伙伴有真诚的意愿和足够的耐心。
提问:您刚刚介绍的案例大部分是在高端私人医院或大型公立三甲医院。对于民营综合性医院或社区医院来说,医疗人工智能对它们有价值吗?
张益肇:有。我刚才提到印度的案例,用设备检测糖尿病的发展情况。在基层和医生资源不够的地方,这种人工智能发挥的作用更大。我刚才提到的疟疾的例子也是如此。
┏(^0^)┛欢迎分享,明天见!