冠军方案根据自然语言提问生成简单 SQL 查询语句,已达到了 92.19% 的准确度,你能做到吗?
首届中文 NL2SQL 挑战赛最近终于落下了帷幕,在 3 个月的角逐中,选手们围绕中文句子生成 SQL 查询语句探索了更多的解决思路。评委代表、复旦大学教授肖仰华说:「从所有参赛队伍的演讲与问答,我们可以看出选手都有非常深厚的理论功底、有很娴熟的 NLP 技巧、都会复现与改进 SOTA 模型,以及都吻合『预训练+调优』这一主流研究思路。」
本次中文 NL2SQL 挑战赛由追一科技主办、南京大学计算机软件新技术国家重点实验室协办,最后的总决赛答辩与颁奖典礼在南京大学举行。机器之心有幸能听到各位大神的模型及方法解析,本文也将为大家解读这些优秀的解题思路。
在最终决赛现场中,评委们根据 5 强选手队伍的方案分享、答辩以及最终成绩确定最后的名次。来自国防科技大学的选手团队夺得冠军,国双科技选手团队获得亚军,观安信息与妙盈科技选手联合团队获得季军,来自华南理工大学与佛罗里达大学的选手队伍、以及浙江大学的团队则获得优胜奖。
![]()
冠军团队「不上 90 不改名字」上台领奖,团队成员为国防科技大学 16 级博士生张啸宇、国防科技大学 18 级硕士生赛斌、昂钛客 ai 王苏宏。
冠军团队在 SQL 生成的正确率上已经达到了 92.19%,而 SQLova 在 WikiSQL 数据集获得 89.6% 的执行准确率就在论文表明其已经「超过人类水平」。所以,在这个中文 NL2SQL 任务上,或许简单语句的生成已经超过人类水平了。
虽然这次挑战赛比较难,但参赛队伍非常多,可以说是今年最为流行的中文 NLP 挑战赛之一。追一科技 CTO 刘云峰博士表示,「我们相信,随着 NLP 进入 AI 领域研究的焦点位置,数据库的创新交互,将拥有巨大的潜力。」此次 NL2SQL 大赛只是一个起点,如果希望真正「解放」文本数据,那么海量的关系型数据还需要我们做更多的前沿探索。
![]()
所有决赛选手(第一排)和评委(第二排)合影。评委团包括中国移动研究院首席科学家冯俊兰、复旦大学教授肖仰华、新加坡南洋理工大学副教授毛可智、南京大学教授俞扬、追一科技 CTO 刘云峰。
这次 NL2SQL 挑战赛真的很受关注,自 6 月份比赛启动以来,海内外共有 1457 支队伍、1630 名选手报名参赛,参与院校数达 170 所,其中 227 支队伍、318 名选手最终提交有效成绩。
「此次挑战赛参与规模远超预期,显示出 NL2SQL 在学术和工业应用上的潜力,数据库的交互创新,正在受到越来越多关注。」追一科技刘云峰博士表示。这也是非常出人意料的,至少从机器之心常介绍的研究成果或读者反馈来看,NL2SQL 以前并没有这么受关注,但在比赛开启后,越来越多的开发者对它产生了浓厚的兴趣。
这次挑战赛这么受关注,很大一部分可以归功于新数据集的发布。挑战赛使用的中文 NL2SQL 数据集包含约 4 万条有标签的训练数据、1 万条无标签的测试数据,也就是说一共包括 4,870 张表格数据、49,752 条标注数据。
而除了这些之外,正式的开源数据还会包含另外一些「拒识数据」,即会有一些自然语言并没有对应的 SQL 语句,模型应该拒绝作出预测。例如我们问「DenseNet 在 ImageNet 上的 Top-5 准确率是多少?」,而数据库的表格都是金融领域的表格,那么模型应该拒绝生成 SQL 语句。
机器之心在挑战赛开启之前就曾对赛题、数据、基线模型有过一个较为详细的介绍,感兴趣的读者可以先看看那篇文章。在这里我们只简要展示一条完整的标注数据是什么样的,如下图所示,NL2SQL 希望根据 "question" 和对应表格预测出 "sql" 到底是什么样的。
![]()
对于标注样本中的 "sql",不同的索引数值有着不同的语义,例如"agg":[5] 表示聚合函数是"SUM";"sel":[2] 表示 Select 子句选择的是表格第二列。整体而言,根据上图问题需要正确预测出如下数据:
SELECT SUM(col_3) FROM Table_4d29d0513aaa11e9b911f40f24344a08 WHERE (col_1 == '大黄蜂' or col_1 == '密室逃生')
目前整个完整的数据集还没有正式开源,但选手可以从天池挑战赛页面下载比赛数据集。需要注意的是,NL2SQL 中文数据集比英文数据集 WikiSQL 引入了口语化表达、结合表格内容、命名实体链接、更复杂的 SQL 语法等挑战,难度更高的同时也更贴近于真实应用场景,所以读者们也可以继续探索更优秀的解决方案。
在决赛当天,追一科技刘云峰博士总结道:「我觉得到了今天,比赛就告一段落,但数据集的影响却是长远的。我关注到一个比较大的趋势,每当出现比较大型的比赛,或者说这样一个公开数据集以后,会大力地推进该项技术的发展。最显著的就是李飞飞等研究者提出的 ImageNet,它相当于一把公开的尺子,我们都愿意用它度量自己最好的方法。」
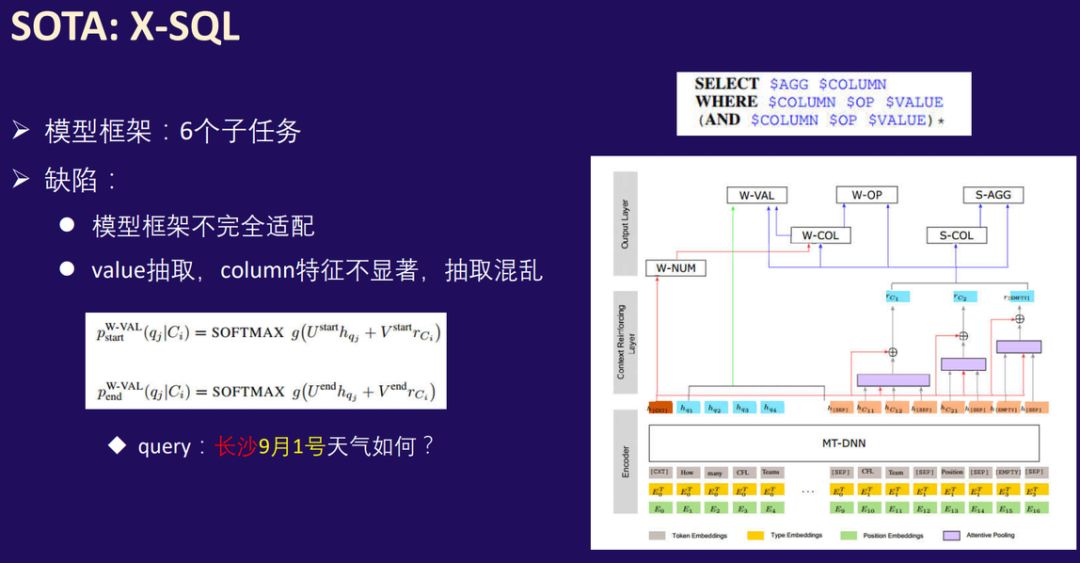
在这次挑战赛中,中文 NL2SQL 数据与 WikiSQL 主要有三点差异,即更口语化的表达、可用表格数据以及单位存在差异。国防科大等研究者的方案也是从 WikiSQL 的 SOTA 模型 X-SQL 出发,并针对数据以及 X-SQL 现有的问题提出了新的方法 M-SQL。
首先对于 X-SQL 的基本思想,因为 SQL 是高度结构化的语句,因此从 SQLNet 到 X-SQL 等方法都将 NL2SQL 视为一种槽值填充任务,即通过多个子任务对 SQL 语句的关键部分进行预测。
X-SQL 独特的地方在于,它建立在预训练语言模型之上,并通过一个额外的层级强化其获得的上下文信息,从而构建出一种高度结构化和模式化的信息。X-SQL 相信 BERT 等模型在自然语言领域的编码已经做得非常好了,我们只需要将这种表征更贴近 NL2SQL 任务,获得更加结构化的表征。
如下右下角所示为 X-SQL 的主要架构,其中 h_q 表示问句的嵌入向量序列,而 h_C 表示表头嵌入向量序列,例如 h_C11 表示表头第一列第一个词的嵌入向量。在上下文强化层级中,最重要的结构就是橙色的特殊向量 h_[cxt] 和紫色的注意力池化,其中 h_[cxt] 能捕捉到全局的上下文信息,而注意力池化会根据列名与全局上下文信息的距离确定最终这一列的向量表征。
![]()
现在相当于 Query(中文问句)中每一个词的嵌入向量、每一个列名的嵌入向量,以及全局上下文信息 h_[cxt] 共同对 6 个子任务进行预测。但冠军团队成员、国防科大 16 级博士生张啸宇表示 X-SQL 主要有两点缺陷,即架构与中文 NL2SQL 任务不匹配、列名特征不显著等。
其中比较重要的是第二点,value 抽取时出现的混乱情况。研究者举了一个例子,假设 Query 是「长沙 9 月 1 号天气如何?」,那么我们希望模型能预测到「SELECT "天气" WHERE ("城市" == "长沙" AND "时间" == "9 月 1 日")」。我们希望能基于「城市」这个字段检索出「长沙」,但问题是 X-SQL 在抽取 Value 的过程中容易出错,混淆成"城市" == "9 月 1 日"。
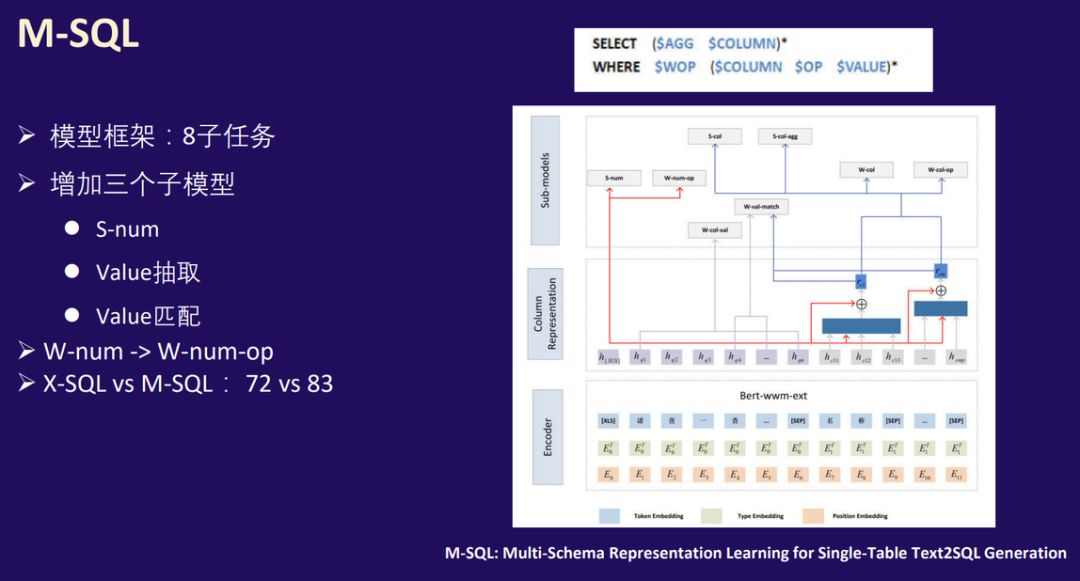
为此,国防科大等研究者提出了一种新模型 M-SQL,其中 M 表示 Multi-Schema,它重点表明多个子任务之间的联合优化能相互促进与提升。该模型在线下验证集上远远优于 X-SQL,且研究者在近期也会发布相关论文。如下图右侧所示,M-SQL 保留了 X-SQL 的全局上下文信息向量与注意力池化操作,并重点改进了子任务。
![]()
M-SQL 将中文 NL2SQL 任务分解为 8 个子任务,额外增加了三个子任务。那么 M-SQL 真的只是在分解子任务吗?「它相比 X-SQL 最核心的贡献或突出点又体现在哪?」,中国移动研究院首席科学家冯俊兰博士在点评时就有这样的提问。
其实 Value 抽取与匹配是 M-SQL 非常突出的贡献,它大大降低了 X-SQL 在 Value 抽取中出现的混乱现象。具体而言,Value 抽取不再基于列名特征抽取对应的 Condition Value,而是一次性将 Query 中包含的所有 Value 都抽取出来。然后再借助 Value 匹配任务将 Value 和数据库表中的字段进行匹配,这样才能极大地降低误匹配的概率。
在确定 M-SQL 整体架构后,剩下的就是在细节和数据上修正它的性能。从预处理过程到预训练语言模型的选取,研究者重点介绍了提升模型性能的十项改进。感兴趣的读者可以看看冠军团队开放的答辩 PPT,下面只简要介绍我们可能熟悉的改进。
首先非常重要的就是数据预训练,我们需要统一问句与标注中的不同表现形式,例如需要根据问句中的"5 百元"定位到表格中的"500"。研究者会使用规则修正数字、日期、年份、单位;使用编辑距离修正同义表达;这两者都旨在统一 Query 为确定的格式。
除此之外,研究者发现采用哈工大的 BERT-wwm-ext,要比采用原版 BERT-base 提高 0.3 个百分点;采用表格内容加强表格列字段名的可辨识度,可以提高 0.4 个百分点。
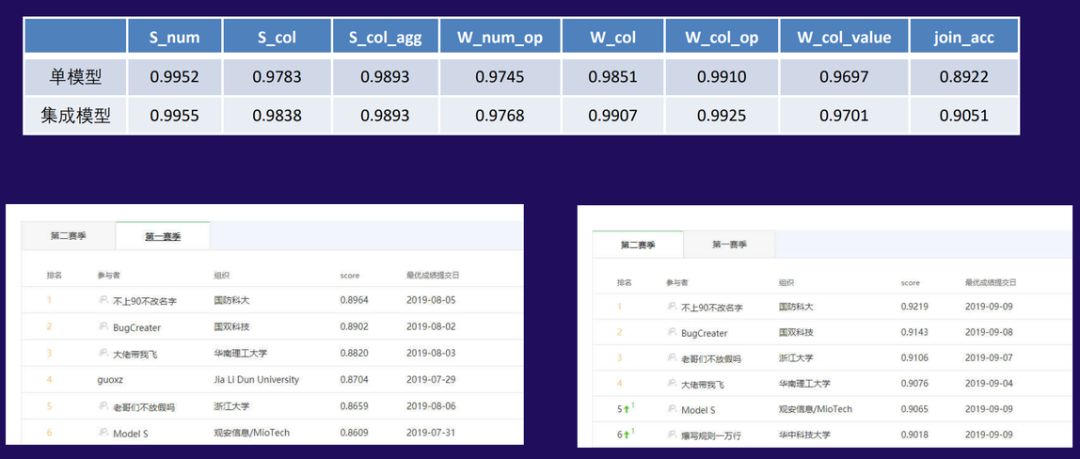
通过一系列实验与调优,模型最终才能得到最优的效果。如下展示了冠军模型在不同子任务的效果,其在线下验证集上最高能达到 90.51% 的准确率,而在未知的测试集上却能达到更好的 92.19%。这表明模型并没有过拟合,且研究者认为追一保留的测试集质量更高,做过更多的筛选,所以最终准确率反而高一点。
最后,非常重要的一点是,M-SQL 的训练速度和推断速度非常快。
国防科大张啸宇表示:
「M-SQL 在单张 2080ti GPU 上一个 Epoch 需要 20 分钟,模型只需要 3~4 个 Epoch 就能收敛。
而且在测试数据集上推断,单模型只要一分钟。
训练和推断效率在所有队伍中应该属于最高的一批。
」
除了冠军模型外,其它队伍也都有非常独特的闪光点。机器之心还记得有选手从数学上展示为什么 X-SQL 会造成 Value 预测的混乱、有选手尝试定义新任务以无监督地学习表格信息、有选手定义新的注意力方式以获得更优秀的表征向量...
总体而言,整个答辩都是一场盛宴,我们可以看到不同的选手会从不同的角度理解赛题,并作出自己的探索。前面国防科大的 M-SQL 将 NL2SQL 视为槽值填充的任务,而浙江大学团队从 QA 的角度思考 NL2SQL。
具体而言对于列的抽取,浙大团队表示给定问题 Q 和表列名,期望输出中核心部分 S-COL、W-COL 都得到候选列集合,这个问题可以看做不定项多项选择问题。对于 W-VAL 的抽取,即使标注条件值可能不完全出现在 Query 中,但是对于 Query 中与其相似的部分,可以看做是抽取式问答任务。沿着这条思路,浙大团队构建出一种异于 SQLova 或 X-SQL 等「正统」方法的模型,并取得了很好地效果。
另一方面,前面介绍过 X-SQL 在预测 Value 时会出现混乱,而华南理工与佛罗里达大学的团队表示其根源出现在预测 Span 时的表达式不对。其中 Span 预测指确定 Query 中起始和结束位置,并将该范围内的词作为 Value 预测。
如下我们先看看原始 X-SQL 在预测 Span 时的表达式,其中 C_i 表示某个列名、q_j 表示 Query 第 j 个位置、p(q| C) 则希望在给定列时找到 Query 中对应的 Span。在这个例子中,找 Span 起始点可以表述为找令 softmax 值最大的索引 j,而 g 又是线性函数,因此就可以转化为 g(Uh_q) + g(Vh_c)。
问题来了,后一项根本与 j 无关,因此在最优化中可以省略,也就是说列名的隐向量并不会影响 Span 的选取。即使我们以不同的列为条件来预测 Query 中的 Span,其预测的结果很可能是一样的。因此在原始 X-SQL 中,它并做不到不同列有不同的 Value 预测。
![]()
知道原因后解决方法就很明确了,要么在 h_c 上拼接 h_q 的信息,要么将 Query 信息与列信息作进一步交互。改进预测函数,也是该团队非常重要的贡献之一。
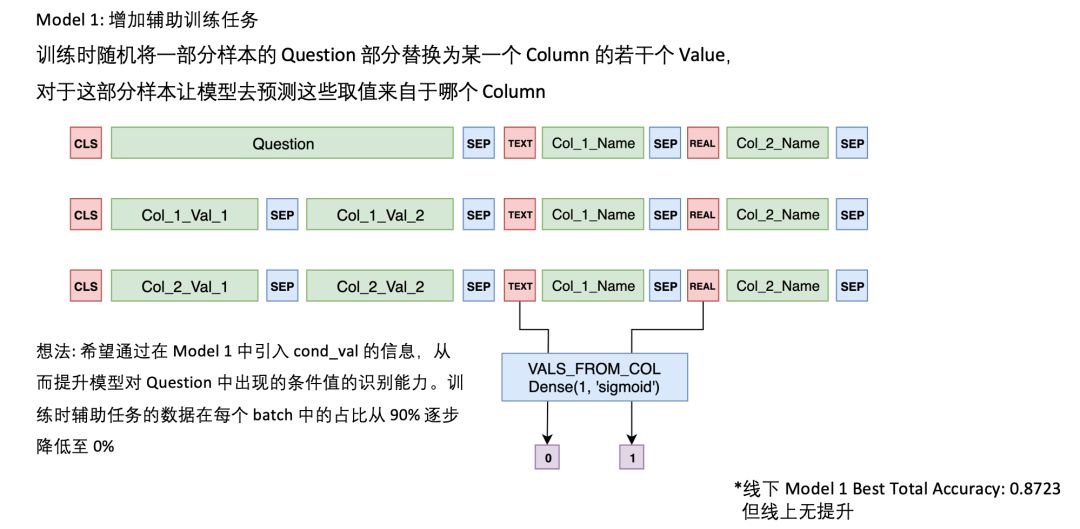
令人印象深刻的是,季军 Model S 团队提出了利用无监督辅助任务学习表格的内部联系。虽然这个尝试并没有带来很多性能提升,但众多评委对其都印象深刻。
![]()
南京大学教授俞扬博士说:「增加辅助训练任务这个想法非常好,但实验表示性能没有显著提升,那么就要明确它在什么情况下是有用的,在什么情况下又是没有帮助的。」如果明确了这一点,那么这种挖掘全局信息的思路,不仅在这个任务,在很多任务都会有更加突出的贡献。
复旦大学教授肖仰华点评总结中表示:「对表格数据的统计分析以及其它无监督学习是非常重要的,无监督方法在追一等企业的实际业务中特别有帮助。我们可以从数据中挖掘出一些模式、挖掘出一些先验知识,然后考虑其怎样与后面的深度学习模型相结合,这是非常有效的一种研究思路。」
以上就是整个决赛的概览了,从初期最好的成绩 60% 多,经过一番千帆竞渡,比赛结束时成绩已达到了 90% 多。追一科技 CTO 刘云峰博士表示,我们开放的中文 NL2SQL 就是这样一个数据集,它就是一把度量 idea 的标准尺子,它会推动大家一步一个脚印地向前发展。
参考资料:
季军方案与代码:http://github.com/beader/tianchi_nl2sql
复赛第 6 名代码:https://github.com/eguilg/nl2sql
挑战赛页面:https://tianchi.aliyun.com/competition/entrance/231716/information
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com