论文浅尝 | 基于动态知识图谱向量表示的对称合作对话代理的学习

链接:https://arxiv.org/abs/1704.07130
文本研究了对称合作对话(symmetric collaborative dialogue)任务,任务中,两个代理有着各自的先验知识,并通过有策略的交流来达到最终的目标。本文还产生了一个11k大小的对话数据集。为了对结构化的知识和非结构化的对话文本进行建模,本文提出了一个神经网络模型,模型在对话过程中对知识库的向量表示进行动态地修改。
任务
在对称合作对话任务中,存在两个agent,每个代理有其私有的知识库,知识库由一系列的项(属性和值)组成。两个代理中共享一个相同的项,两个代理的目标是通过对话找到这个相同的项。
数据集
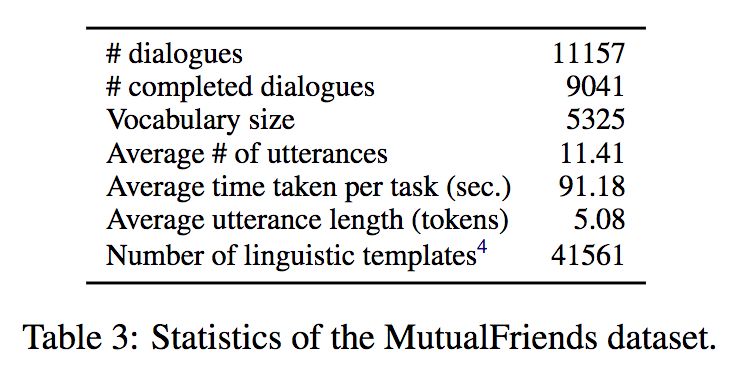
本文建立了一个对称合作对话任务数据集,数据集中知识库对应的schema 中包含3000个实体,7种属性。数据集的统计信息如下所示
模型
针对对称合作对话任务,本文提出了DynoNet(Dynamic Knowledge GraphNetwork),模型结构如下所示
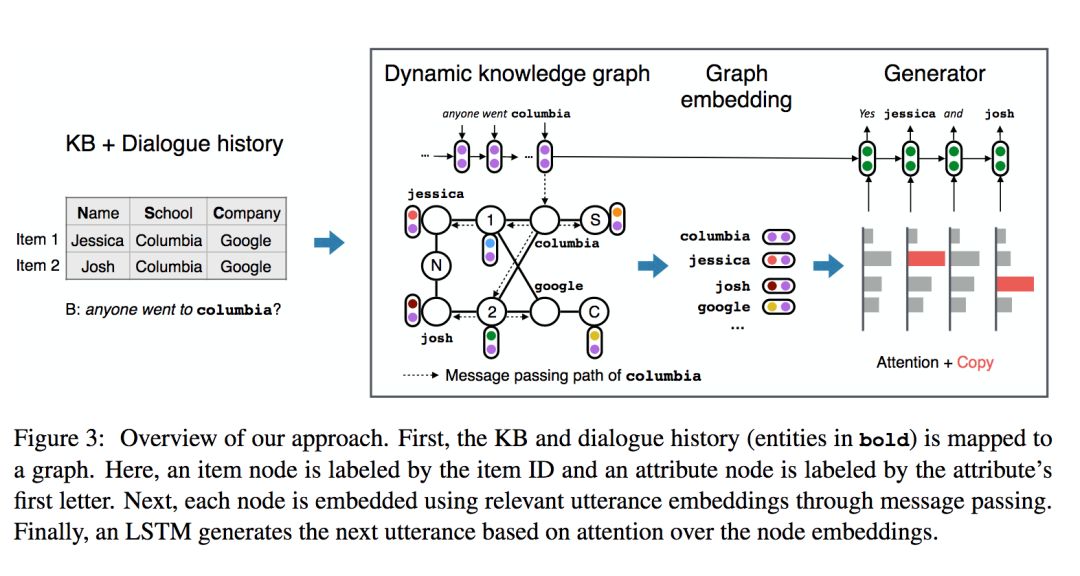
Knowledge graph
图谱中包含三种节点:item节点,attribute节点,entity节点。图谱根据对话中的信息进行相应的更新
Graph Embedding
t时刻知识图谱中每个节点的向量表示为V_t(v),向量表示中包含了以下来源的信息:代理私有知识库的信息,共享的对话中的信息,来自知识库中相邻节点的信息
Node Features
这个特征表示了知识库中的一些简单信息,如节点的度(degree),节点的类型。这个特征是一个one-hot编码
Mention vectors
Mentions vector M_t(v) 表示在t时刻的对话中与节点v相关的上下文信息。对话的表示u_t 由个LSTM络计算得到(后文会提到) 为了区分agent自身产生的对话语句和另一个代理产生的对话语句,对话语句表示为
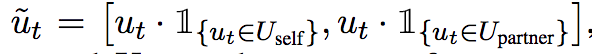
Mentions vector通过以下公式进行更新
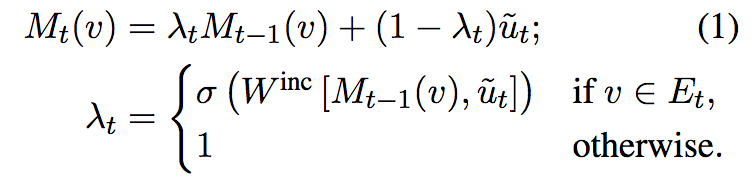
Recursive Node Embeddings
一个节点对应的向量表示也会收到相邻其他节点的影响
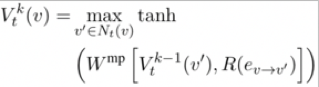
其中k表示深度为k的节点,R表示边对应的关系的向量表示
最后节点的向量表示为一系列深度的值的连接结果
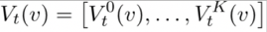
本文中使用了
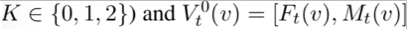
Utterance Embedding
对话的向量表示u_t由一个LSTM网络计算得到
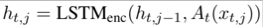
其中A_t为实体抽象函数,若输入为实体,则通过以下公式计算
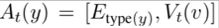
若不为实体,则为文本对应的向量表示进行zero padding的结果(保证长度一致)
使用一个LSTM进行对话语句的生成
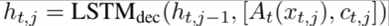
输出包含字典中的词语以及知识库中的实体
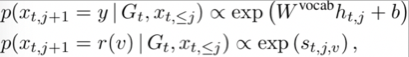
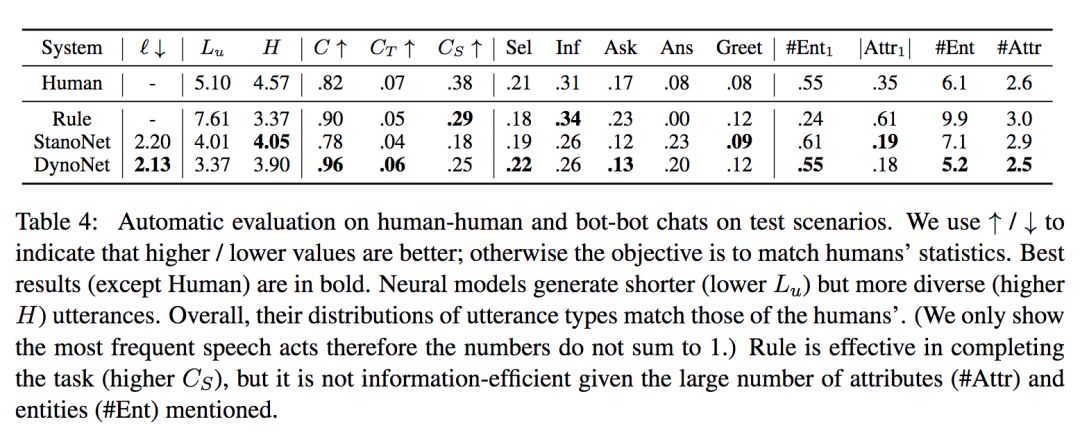
实验结果
笔记整理:王旦龙,浙江大学硕士,研究方向为自然语言处理。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。



